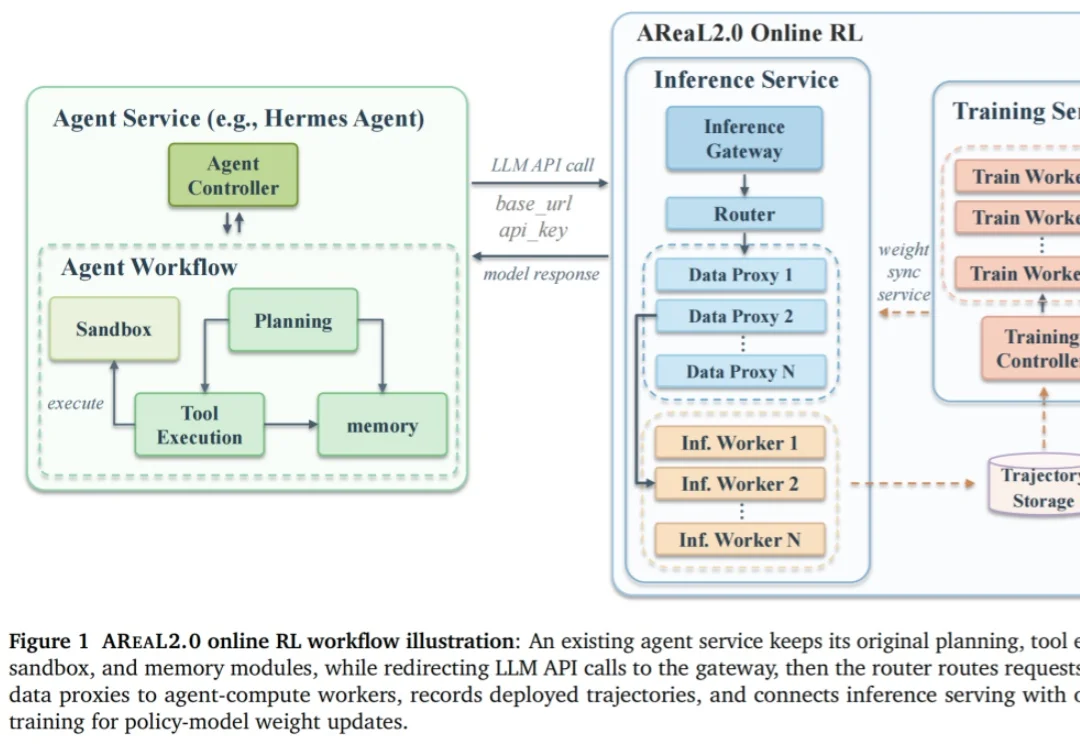
Agent的自演进,被刚刚开源的AReaL 2.0按下了加速键
Agent的自演进,被刚刚开源的AReaL 2.0按下了加速键当 Agent 从演示视频中的炫技片段开始走进真实工作流与生产环境,下一阶段的「何去何从」成为业界关注的焦点。
来自主题: AI技术研报
6145 点击 2026-07-02 14:31
 搜索
搜索
当 Agent 从演示视频中的炫技片段开始走进真实工作流与生产环境,下一阶段的「何去何从」成为业界关注的焦点。
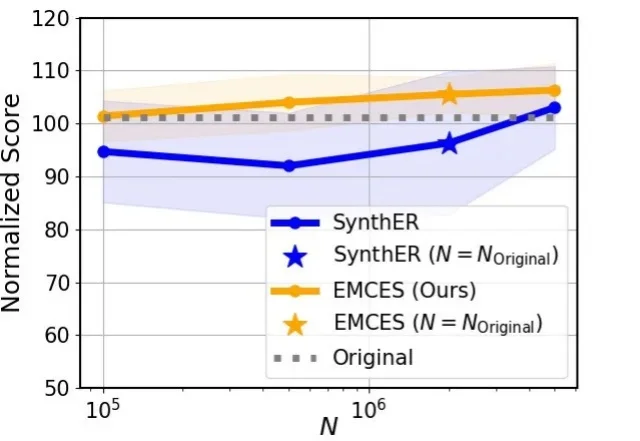
近年来,强化学习在游戏智能体、具身智能、大语言模型等领域取得了显著进展。然而,在真实世界中,强化学习仍面临一个核心难题:高质量样本的获取不仅成本高昂,还可能带来多种风险。因此,样本增强成为缓解强化学习中样本获取成本高、风险大等问题的重要途径之一。

具身智能数据的竞争,正在从“量大管饱”进入下一关。

扩散模型已经越来越会「画」,却还远没有学会「守住要求」。决定系统是否可靠的,已不再只是画质,而是生成结果能否持续遵守条件、维持状态,并符合人类与现实世界的基本标准。
DeepMind 联合创始人、2024 年诺贝尔化学奖得主 Demis Hassabis 曾谈到,他一直将 AI 视为推动知识前沿的重要工具。AI 可以帮助科学家处理复杂数据、发现隐藏模式,也可能在未来参与更深层的科学探索。
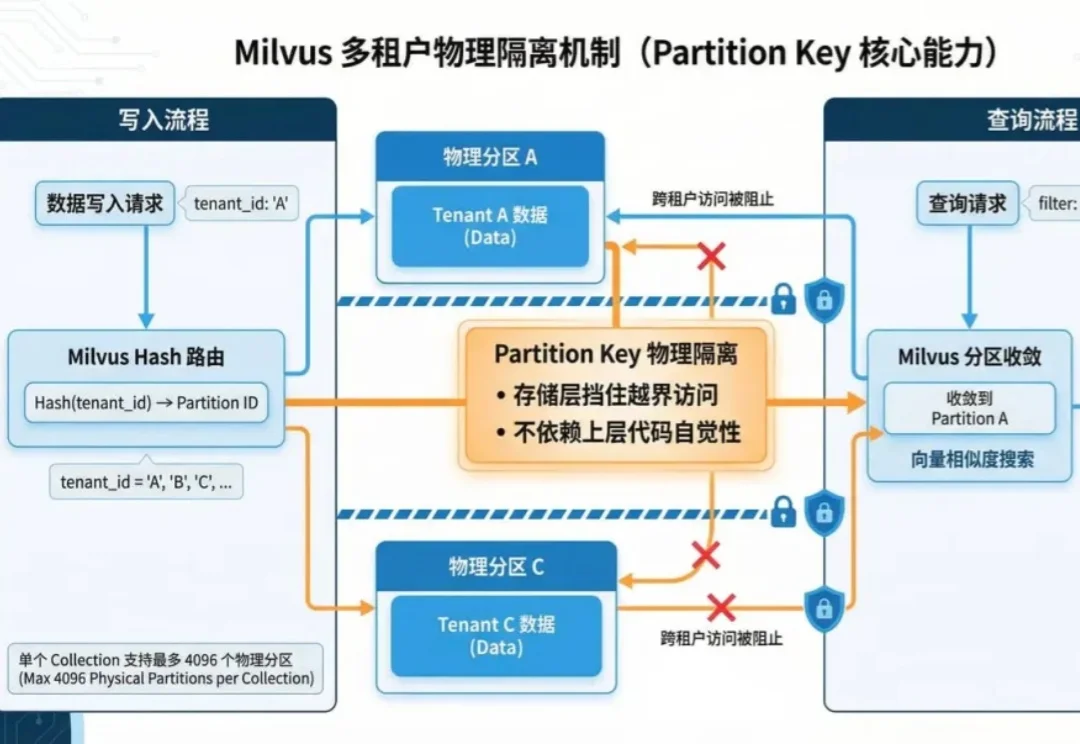
多租户 RAG 与Agent系统的生产实践中,最致命的事故莫过于数据串租,系统将租户 B 的私有数据作为背景知识,回答了租户 A 的提问。
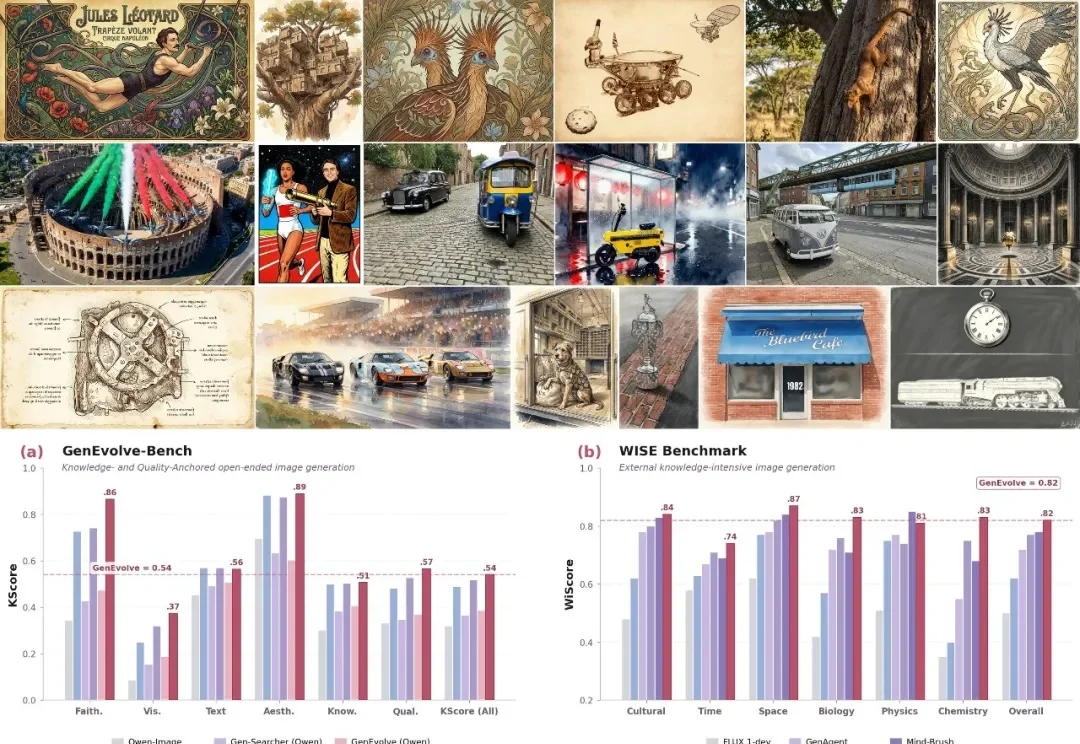
图像生成正在从「一句话生成一张图」,走向更接近真实创作流程的开放任务。
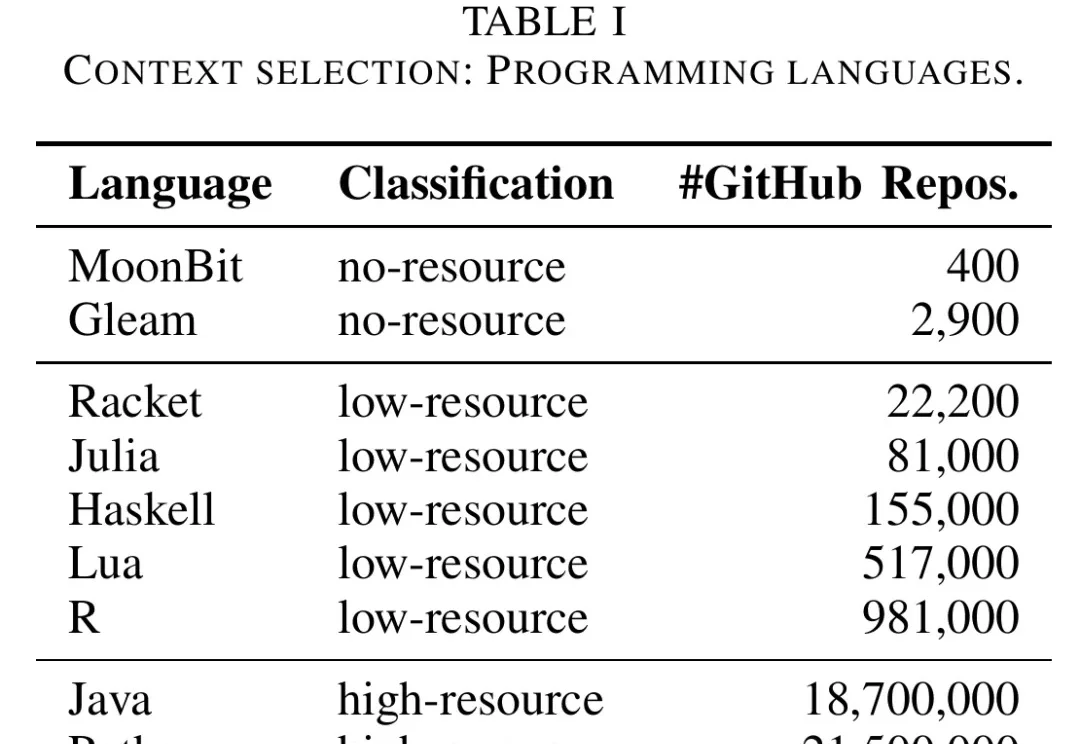
对于Python、Java、JavaScript这些语言,大模型通常能给出相当成熟的答案。
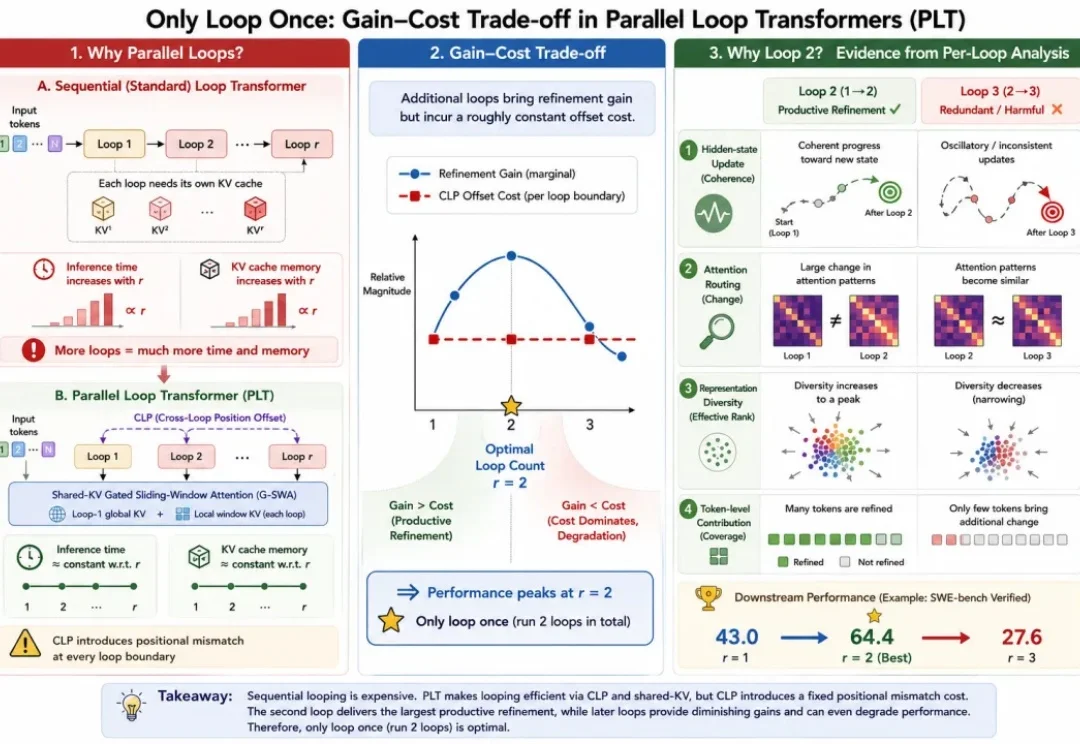
当所有人都在比谁「想得更久、算得更多」——推理模型动辄输出成千上万个思考 token,循环式架构恨不得在内部反复迭代十遍八遍——一项新研究反手泼了盆冷水:

AgentSociety²是清华大学团队推出的社会科学研究新工具,通过AI智能体模拟社会行为,帮助研究者构建实验环境,直接运行社会假设。它让AI同时扮演研究助手和实验参与者角色,使复杂社会问题能被构造、运行和分析,提升研究效率与可复现性。