
给835页文档,还你一个数据库!Cursor重塑「大模型经济学」:AI蜂群化身终极廉价编译器
给835页文档,还你一个数据库!Cursor重塑「大模型经济学」:AI蜂群化身终极廉价编译器多模型Agent系统显然是未来的趋势。cursor 的一篇很不错的文章。他们的最新研究表明,将前沿模型作为规划者和协调者,与一个更廉价的“主力”模型搭配,可以大幅降低项目中总token的成本,从而实现 15 倍的成本改进。
来自主题: AI技术研报
7617 点击 2026-07-25 11:37
 搜索
搜索
多模型Agent系统显然是未来的趋势。cursor 的一篇很不错的文章。他们的最新研究表明,将前沿模型作为规划者和协调者,与一个更廉价的“主力”模型搭配,可以大幅降低项目中总token的成本,从而实现 15 倍的成本改进。
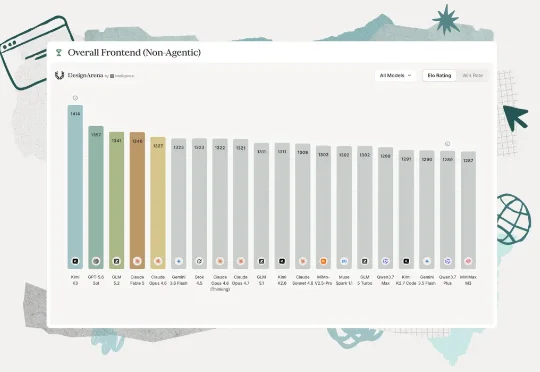
停停停!Kimi K3的最佳打开方式可能不在Coding——用它做前端设计,才是真·Interesting。在Design Arena最新公布的单次生成前端榜单中,Kimi K3以1414分位列第一,力压Fable 5和GPT-5.6 Sol。
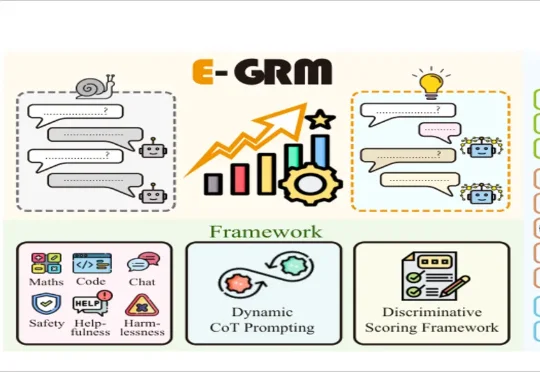
E-GRM的核心思路就是让模型自己判断输入复杂度——通过多次采样看答案是否收敛。收敛了就直接回答,不收敛再触发CoT。在RM-Bench、RMB、RewardBench三个基准上,约58%的样本被智能路由到“直答”,延迟降低62%,同时准确率还有提升。
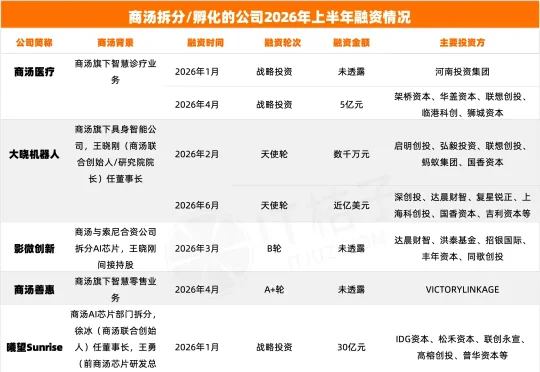
根据IT桔子数据,截至2026年7月17日, 32家“商汤系”公司在上半年共完成28笔融资,累计融资额超过470亿元人民币,在中国AI融资市场取得了耀眼的成绩。其中,既有商汤科技自身通过“1+X”战略拆分出的子公司——曦望Sunrise、大晓机器人、商汤医疗等;也有大批从商汤离职创业的前高管所创立的公司
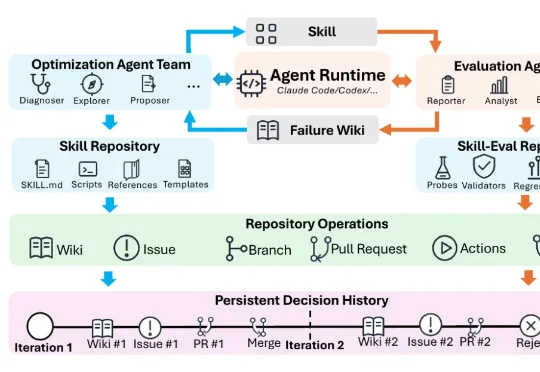
腾讯微信在论文 SkillHone 中,将这个问题归结为优化历史丢失,进而提出了面向持续 Skill 进化的开发框架。 SkillHone 把每轮诊断、候选修改、评估证据和最终决定组织成持久决策历史。同时,持续优化的对象也从单一的 SKILL.md 文件扩展到了整个 Skill 文件夹及其修改过程。
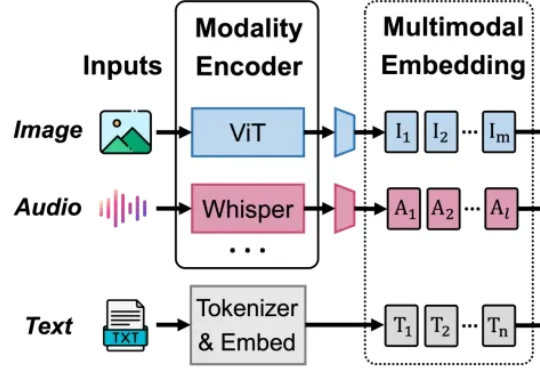
BigMac 是原生多模场景下的流水并行训练新范式。它针对多模态大模型训练中计算效率与显存占用难以兼顾的问题,提出了依赖安全的嵌套流水线:以成熟的 LLM 流水线为主干,在不打乱 LLM 执行顺序的前提下,有序嵌入编码器和生成器计算,从而在不增加 LLM 流水线空泡、保持激活显存有界的同时,高效实现多模态流水训练。
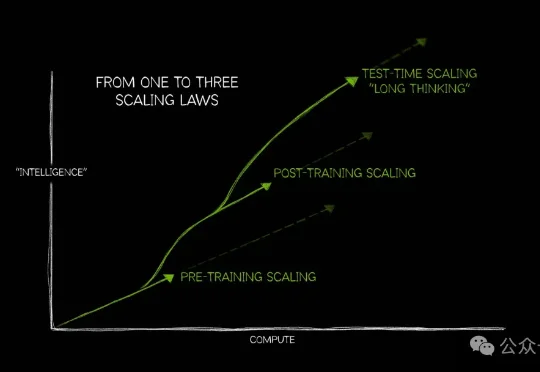
新智元报道 大模型变强,过去靠两条路。 做大——Scaling Law出现后,参数从百亿推向千亿,算力支出一路飙升。 想久——o1带火思考模型,用更长的思维链、更多推理时间换结果。 问题是,除了Sca

数据市场的故事,正在进入新一轮周期。来自企业真实工作流的 Real-world Data,成为越来越多 AI Labs 争夺的新资源。比如 GitHub 就是典型的 Real-world Data,它几乎完整保留了一个问题从出现到解决的全过程。相比之下,今天绝大多数 Human Data 公司提供的,仍是人为构造的数据。
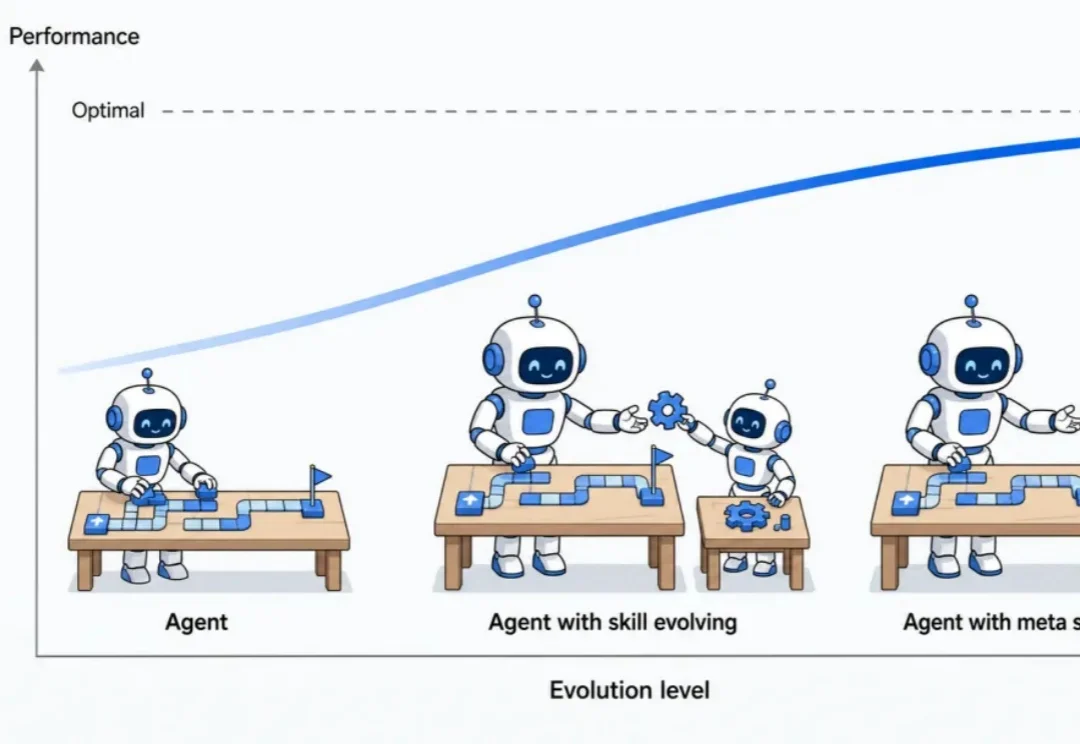
当大模型 Agent 被部署到工具调用、长程任务和开放环境中,一个关键问题会随之出现:能否在不更新模型参数的情况下,将执行经验沉淀下来,并在下一次做得更好?
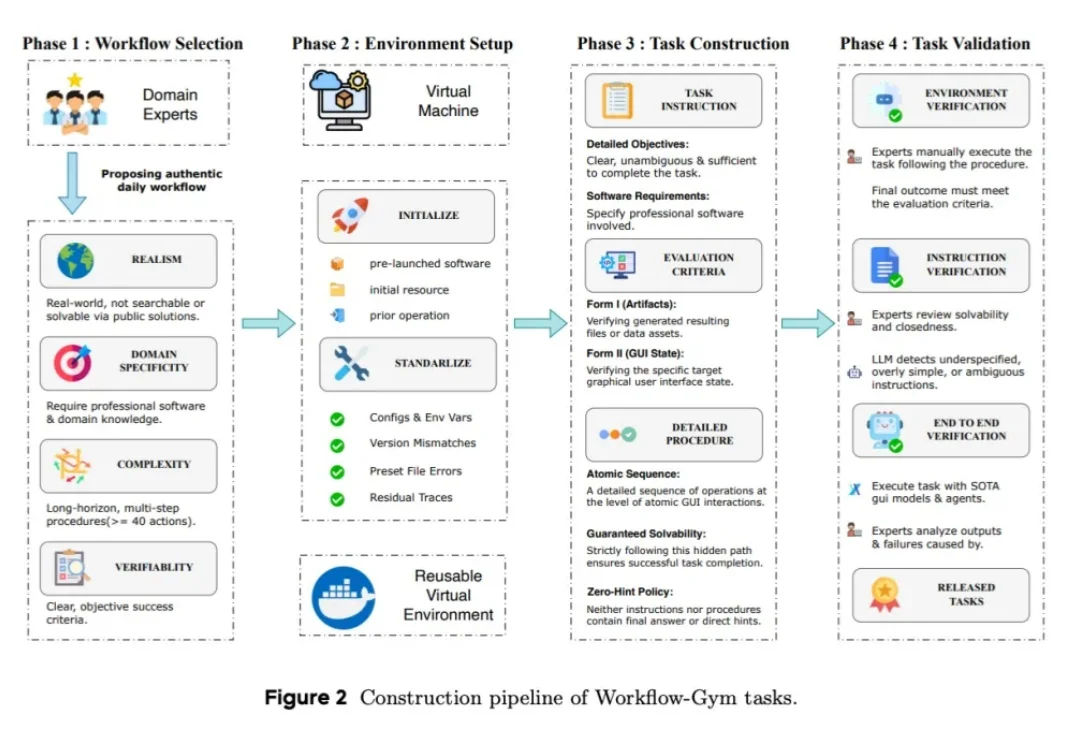
你可能已经在各种 benchmark 榜单上看过 GUI Agent 的 "大胜" 了。
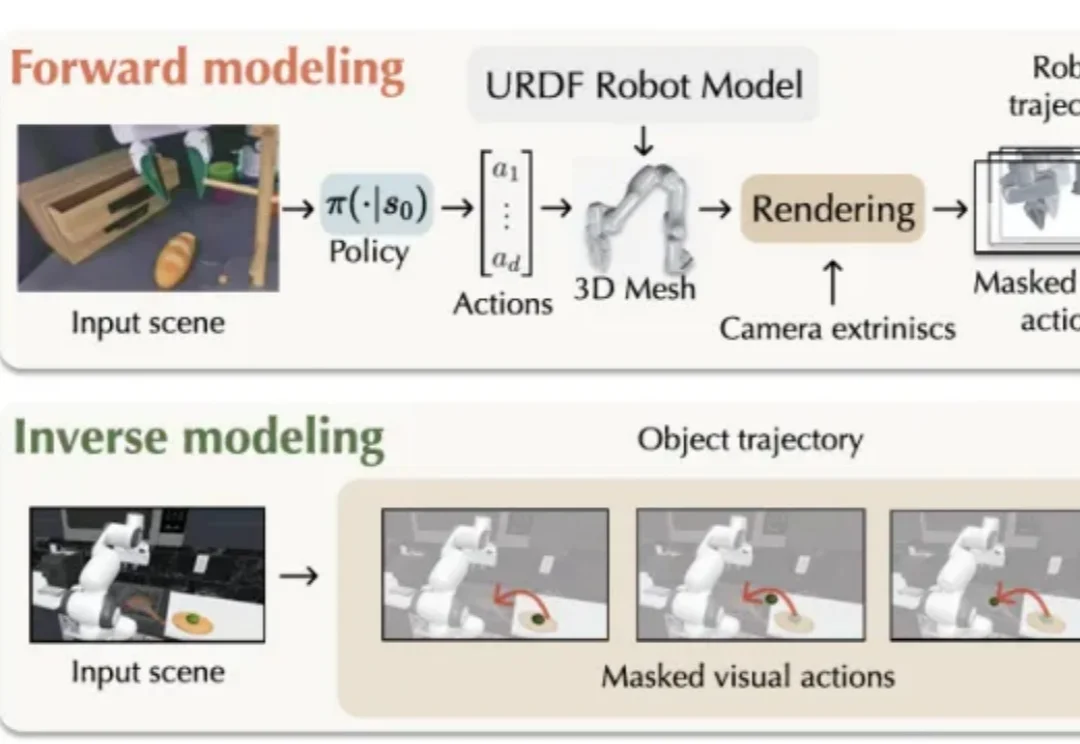
如果要让机械臂把咖啡机旁的杯子移到桌上,需要经历哪几个步骤?
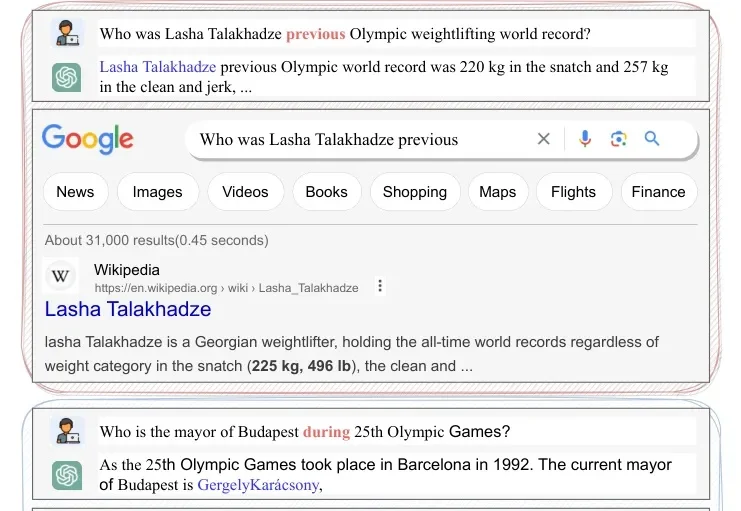
向ChatGPT问一个看起来挺简单的问题:“Lasha Talakhadze之前的奥运举重纪录是多少?”
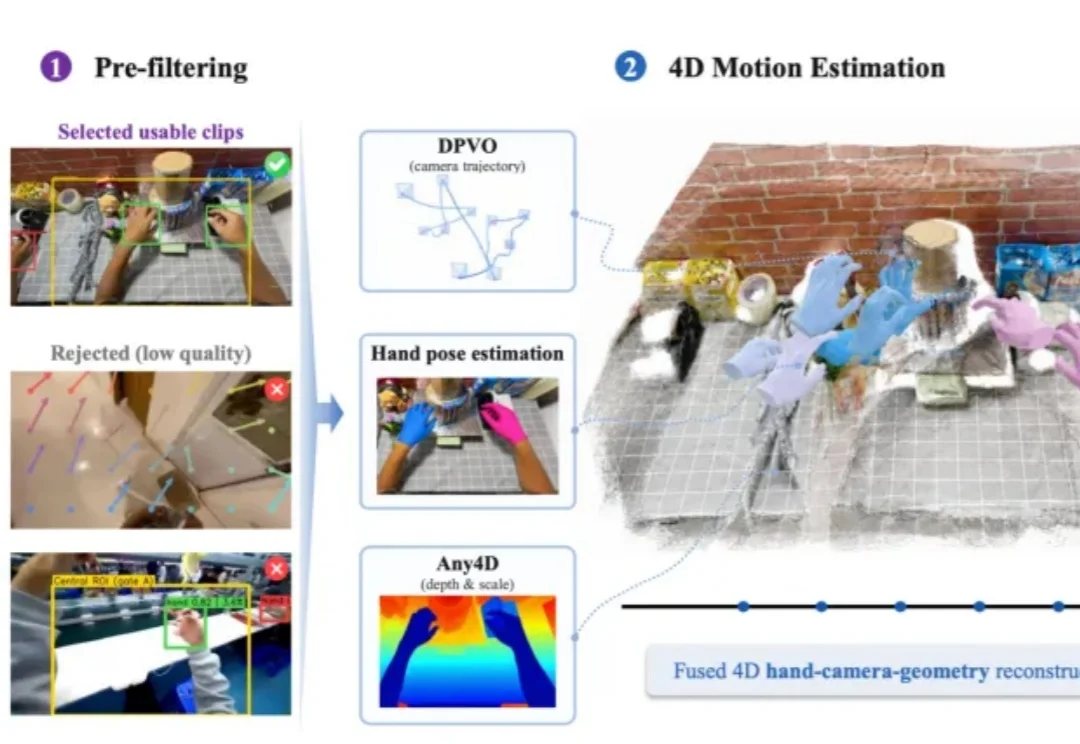
记得何同学做过一个超复杂的流水线项目吗?

逛过WAIC具身智能展区的人,多半有同一个疑问: 都2026年了,机器人干活,怎么还是慢吞吞的?

在近日的具身智能顶会 RSS(Robotics: Science and Systems)2026 上,最高奖项 Outstanding Paper Award 提名名单里,出现了一个不太 “机器人” 的名字 —— 影眸科技,一家头部 3D 生成大模型公司。

最新研究发现,AI幻觉不只会骗你了,还能喂大你的自信心、削弱你的判断力。

国防科技大学虚拟现实与视觉计算团队(SAW Lab)联合先进制导与控制技术国家级重点实验室等推出面向航拍几何 3D 视觉的统一大规模数据集与评测基准 「AirZoo」。
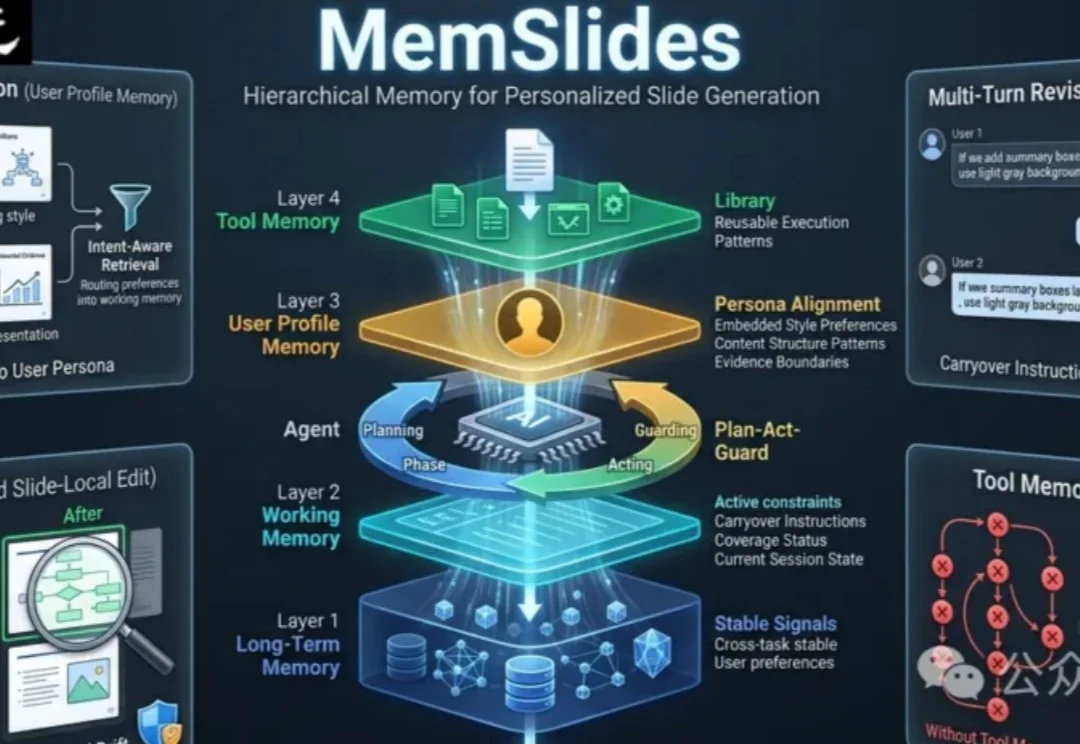
最尴尬的一刻,往往不是AI PPT生成失败。
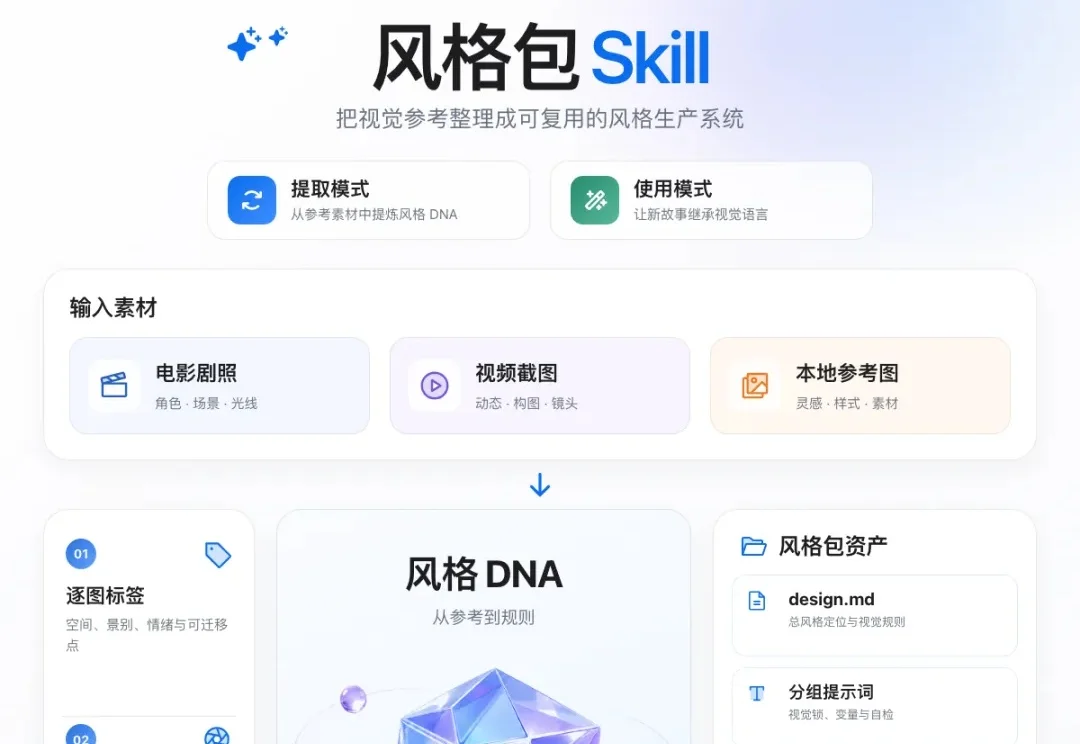
嗨大家好!我是阿真! 刷短视频就是这点不好,上次看到一个 AI 视频拆解分析的教程,感觉很有意思,刷完了过两天忘记在哪里刷的了。

智能的下一阶段,已从“模型”转向“系统可靠性和进化性”的比拼。
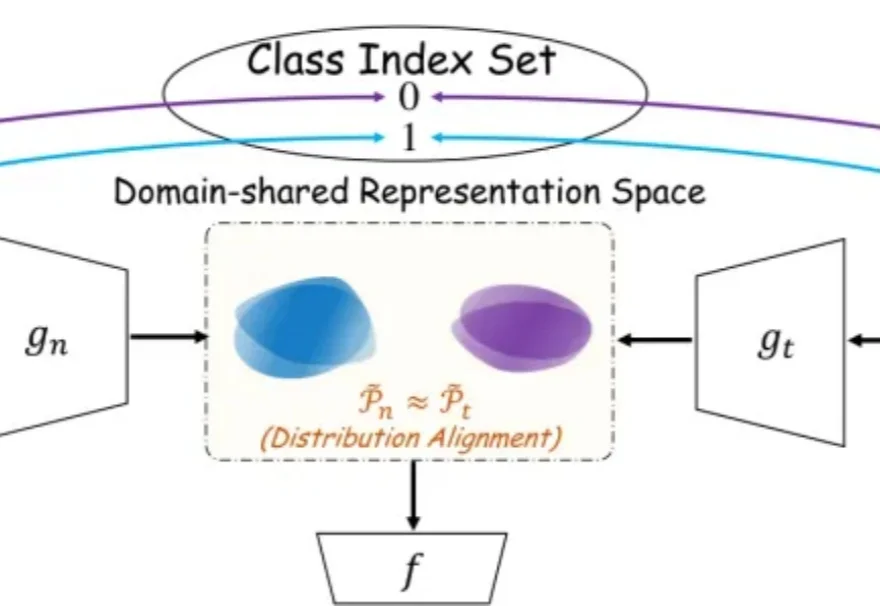
迁移学习里的“源数据”,未必非得是图像、文本或音频。

一夜之间,Tokenmaxxing成为硅谷热议话题!

交互式视频世界模型正在从「一次性生成短片」走向「像游戏一样边操作边生成」。但长轨迹交互会迅速放大上下文、显存和多步去噪开销。Light Interaction不改模型参数、不重新训练,只在推理阶段把相机轨迹变成调度信号,动态选择历史上下文、在回访状态复用去噪输出,并用面向自回归生成的3D稀疏注意力降低计算。
炒股到现在最对不起的,就是家人。

商业地图可以告诉机器人「前方右转」,却无法直接告诉它眼前应该从哪里转、沿哪一侧通过;即使已经生成路线,控制误差、地面变化和动态障碍,也可能让机器人在行进过程中逐渐偏离。

视频是描述物理世界的重要数据形态,更是人类与物理世界交互的重要载体,视频理解大模型是让 AI 从数字世界走向物理世界最基础、最原生的组成部分。
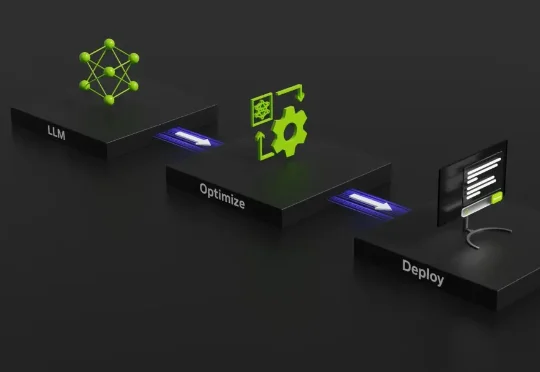
就在最近,英伟达亲自下场,发布了一篇名为《AI Model Co-Design: Hardware-Friendly LLM Design》的技术博客。整篇文章洋洋洒洒,其实就想点醒行业一件事:别光顾着堆算力了,来看看你们是怎么把顶级显卡逼成“磨洋工”的吧。
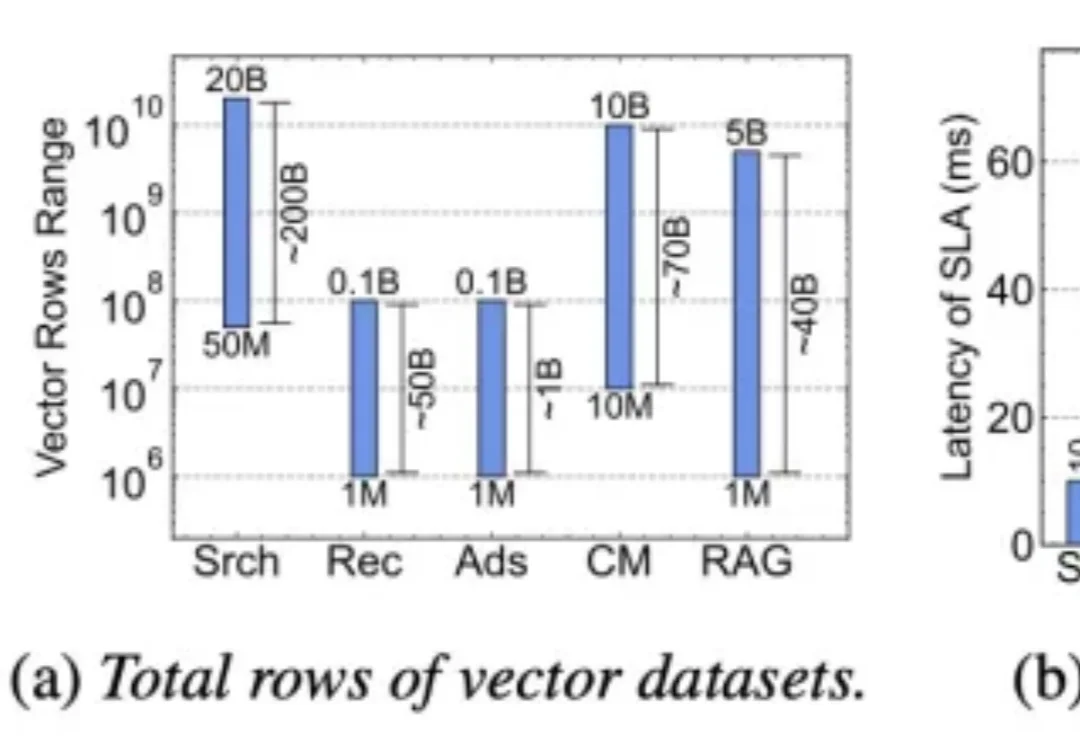
近日,围绕搜索、推荐、广告等核心业务中的大规模向量检索成本与性能问题,小红书引擎架构团队在 OSDI 2026 会议上发表了论文《The Clustering Strikes Back: Building Cost-Effective and High-Performance ANNS at Scale with HELMSMAN》。
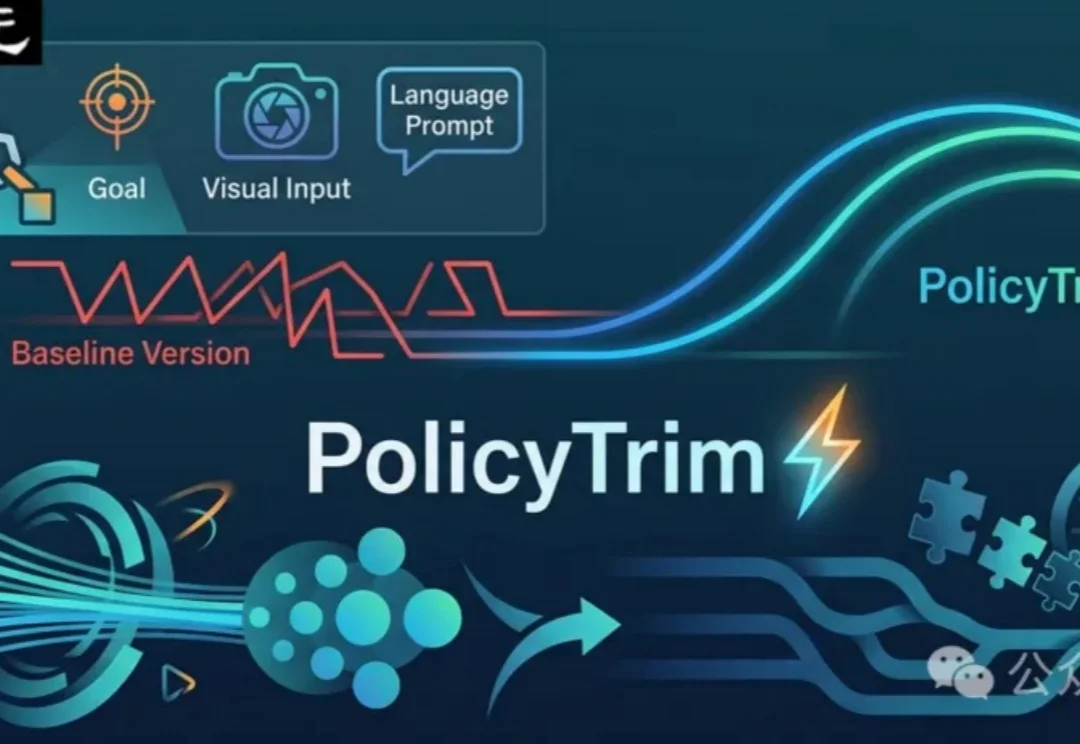
VLA模型已经会做任务,但真实机器人还是慢!PolicyTrim是一种优化VLA机器人执行效率的方法,无需重新训练。它通过扩展可靠动作序列并减少冗余步骤,帮助机器人更直接完成任务,提升整体速度。
刚刚结束的 2026 年世界人工智能大会(WAIC) ,具身智能与 AI 终端占据了最显眼的位置,人形机器人、灵巧手和各类智能硬件吸引了大量目光。