
Anthropic被曝造芯!挖OpenAI老兵,密谈三星2nm
Anthropic被曝造芯!挖OpenAI老兵,密谈三星2nm刚刚,The Information爆出:Anthropic已启动自研AI芯片的早期工作,并与三星电子讨论潜在的代工合作。据知情人士称,考虑中的选项包括三星的2nm制程和先进封装。
来自主题: AI资讯
9696 点击 2026-07-03 16:14
 搜索
搜索
刚刚,The Information爆出:Anthropic已启动自研AI芯片的早期工作,并与三星电子讨论潜在的代工合作。据知情人士称,考虑中的选项包括三星的2nm制程和先进封装。

今晚,我在旧金山 Howard Street 的 Inngest 总部,参加了一场叫做 {AI} in Production 的小型聚会。主办方是 Inngest,Cursor、Arcade、Vapi 联合参与。清一色是在一线真正跑 AI agent 的工程师和创始人,一群人坐在一起,讲他们把 AI 部署进生产环境之后遇到的真实问题。

华大智造子公司涌生智能×上海人工智能实验室,联合发布两项新成果:ProtoPilot:一款由真实实验室场景驱动的自进化多智能体系统;BioLab Bench:生命科学领域首个从用户需求到设备可执行的全流程Agent评测体系。

刚刚,纽约大学联合LeCun初创AMI带来JEPA系列的最新成果——AdaJEPA。与过去在预训练结束后就冻结参数的世界模型不同,AdaJEPA能够在与环境交互中,基于测试时自适应(Test-Time Adaptation, TTA),实时调整世界模型的编码器和预测器参数,从而实现持续学习。
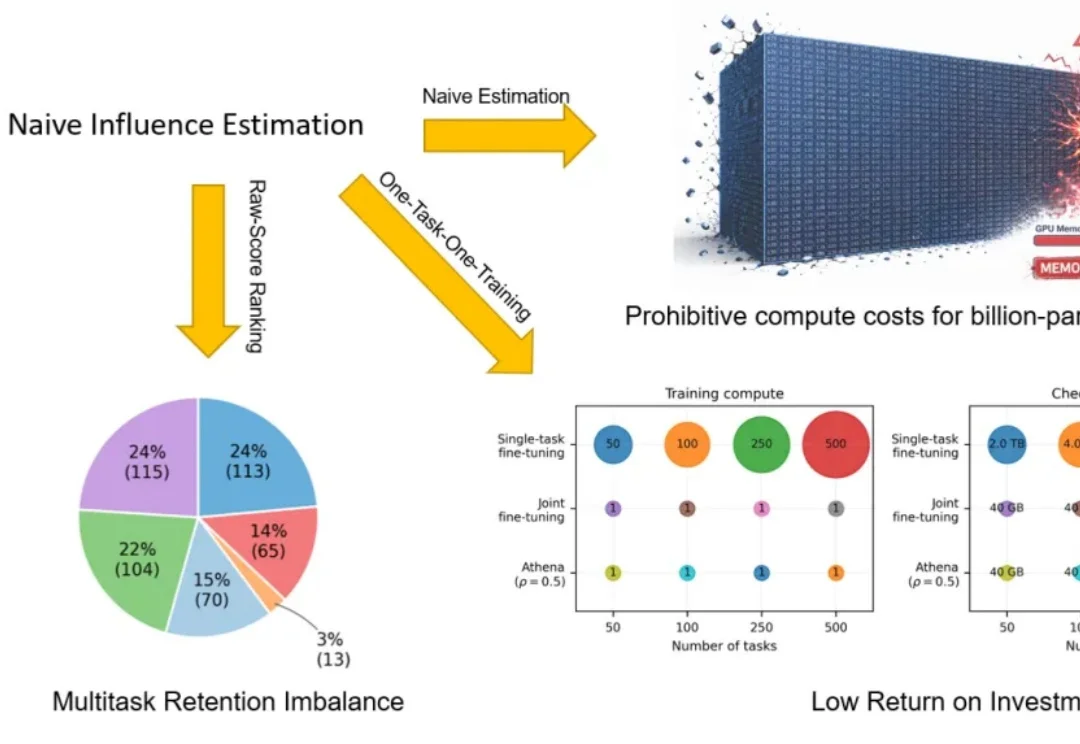
具身智能正在进入数据 scaling 时代。Vision-Language-Action(VLA)模型让机器人可以从大规模示教数据(demonstrations)中学习更通用的操作策略。但对机器人 VLA 训练来说,数据并不总是越多越好:低质量数据可能会拖累模型性能,而每一条 demonstration 都意味着昂贵的人力采集、机器人运行,以及云端存储和训练成本。

据外媒 The Information 报道:Meta 正在限制员工在 AI 模型构建中使用 Claude Code 和 Codex,原因是担心涉及模型蒸馏。 Meta 担心这些外部模型生成的内容,可能进入自家的训练数据或评测体系,从而引发所谓的模型蒸馏争议。

2026年6月17日,Nature 刊登了一项里程碑式的研究,来自海德堡大学医院的研究团队开发了一个名为MIRA(Medical Intelligence for Reasoning and Action) 的自主医疗AI智能体。

《读佳》获知,高德在内测一款Vibe Coding产品“袋马”(“代码”的谐音梗),主打自然语言驱动的零门槛应用构建能力,聚焦小程序与iOS原生应用场景,可快速生成可直接上线、真机可用的应用产品。截至目前,高德官方尚未对外披露该产品的正式上线时间、行业合作模式及商业化细则,相关产品动态仍处于内测阶段。
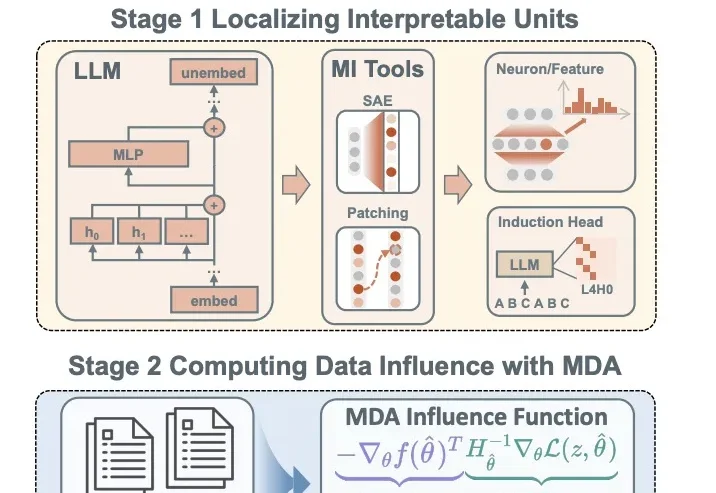
近年来,大语言模型展现出了越来越强的能力,从上下文学习(In-Context Learning, ICL)到复杂推理、代码生成,这些能力不断刷新人们对模型能力边界的认知。
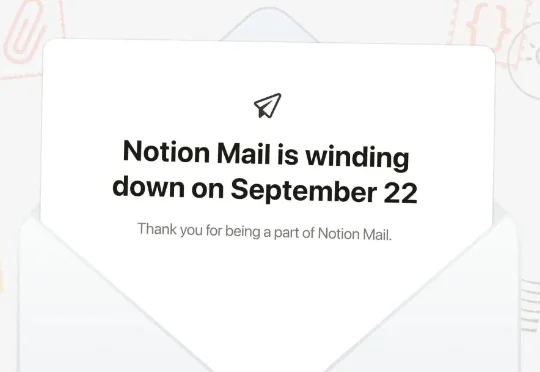
这款 AI 邮箱客户端 2025 年 4 月才正式上线,总生命周期不过 17 个月。Notion 给出的理由很直接,随着 Agent 能力变得更强,越来越多用户将邮件工作流交给 Agent 处理。"如今,超过一半的 Notion Mail 用户在不打开收件箱的情况下管理邮件。因此,我们决定全面转向由 Agent 来管理你的收件箱。"