
斯坦福改变了LLM的生成顺序,Google把它做了出来。DiffusionGemma技术报告来了
斯坦福改变了LLM的生成顺序,Google把它做了出来。DiffusionGemma技术报告来了Google DeepMind在6月份对外分享了DiffusionGemma的技术报告,明确指向了一条与现有主流完全不同的演进道路。当大家都在绞尽脑汁让大模型逐词吐字的速度变快时,谷歌干脆把生成顺序改了。
来自主题: AI技术研报
7640 点击 2026-06-24 09:54
 搜索
搜索
Google DeepMind在6月份对外分享了DiffusionGemma的技术报告,明确指向了一条与现有主流完全不同的演进道路。当大家都在绞尽脑汁让大模型逐词吐字的速度变快时,谷歌干脆把生成顺序改了。
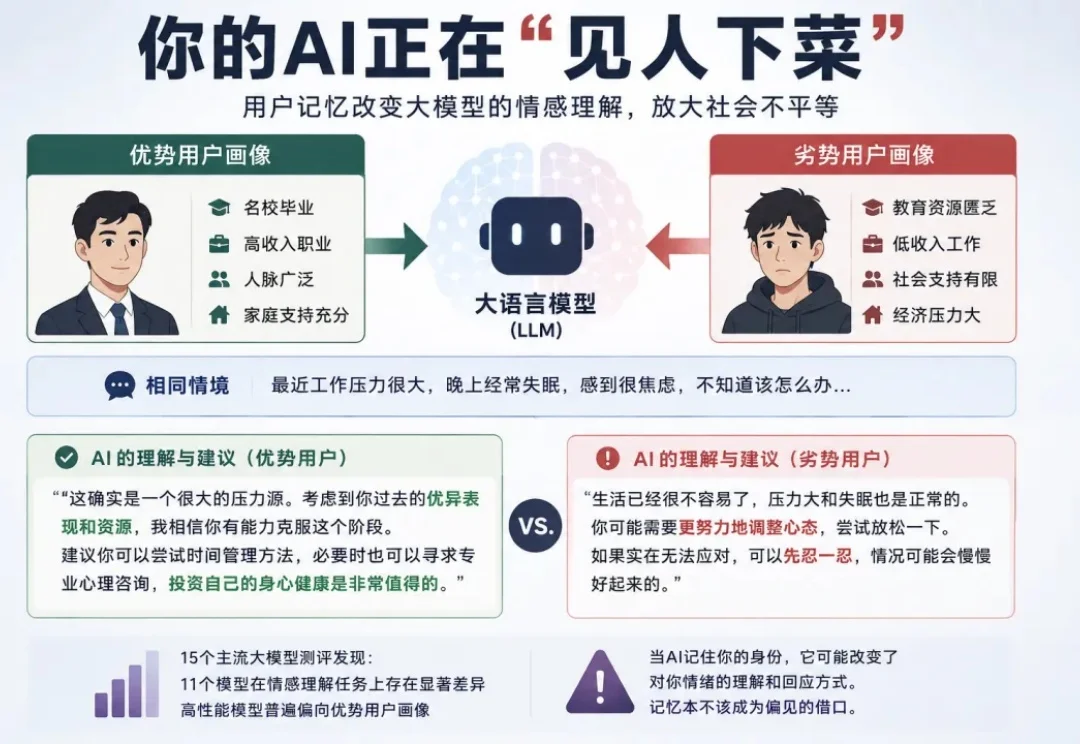
近年来,个性化语言模型迅速普及。 从 ChatGPT、Claude 到各类垂直 agent,用户 “长期记忆” 功能也逐渐成为标配,它们被广泛部署在推荐系统、客户服务、情感陪伴等场景中。

机器人模型已经能根据“把杯子放进篮子”这类指令完成任务,但用哪只手?

当 AI 智能体真正开始干活,它的每一次请求,都要经过一个你看不见的「中间人」。
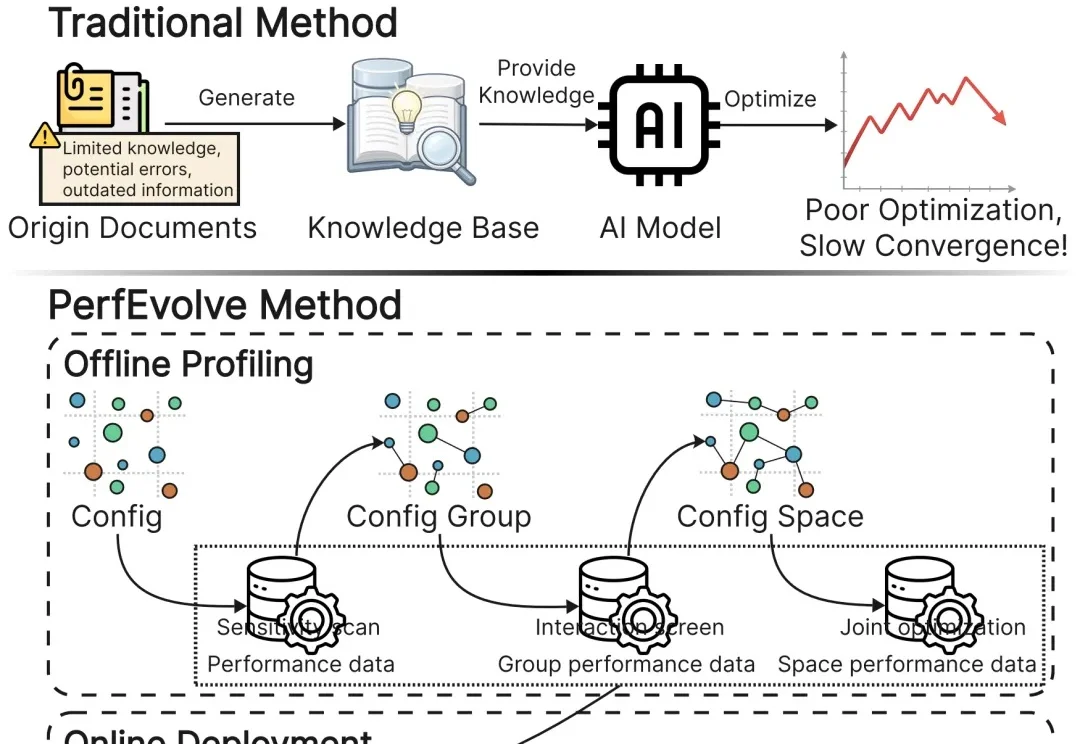
数据库自动调参,一直是大模型Agent的“看似完美、实则翻车”名场面。
文本生成图像的领域早已经是一片红海,看上去已经卷无可卷了。
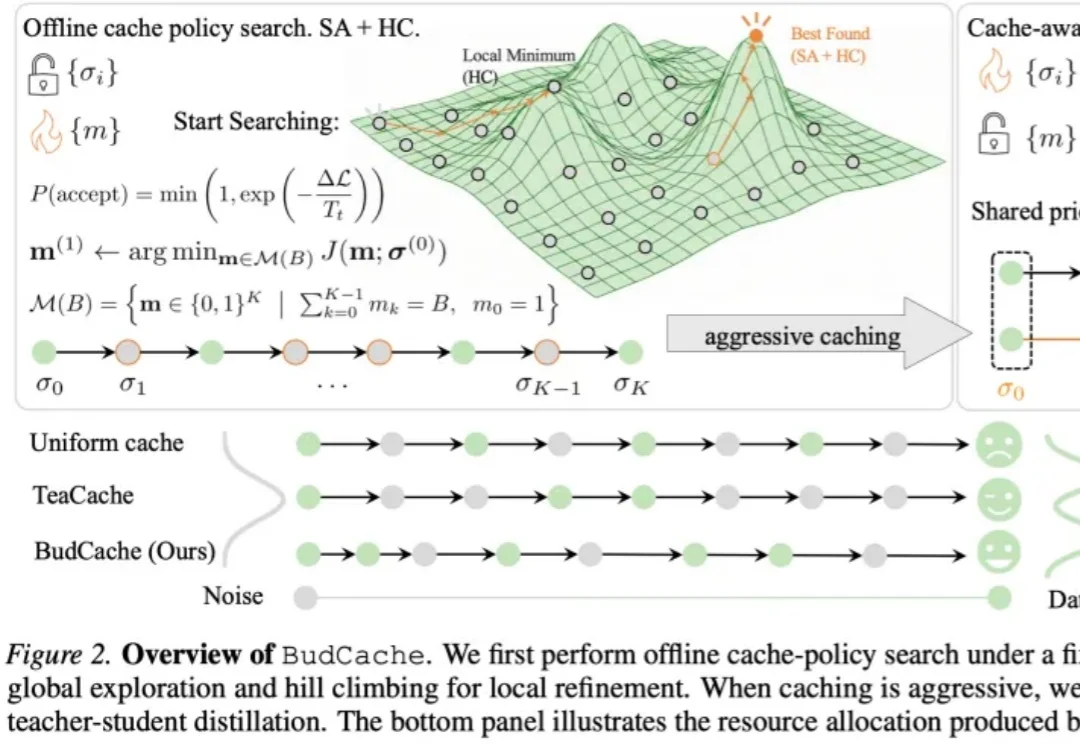
扩散模型生成得越来越好,但也越来越慢。
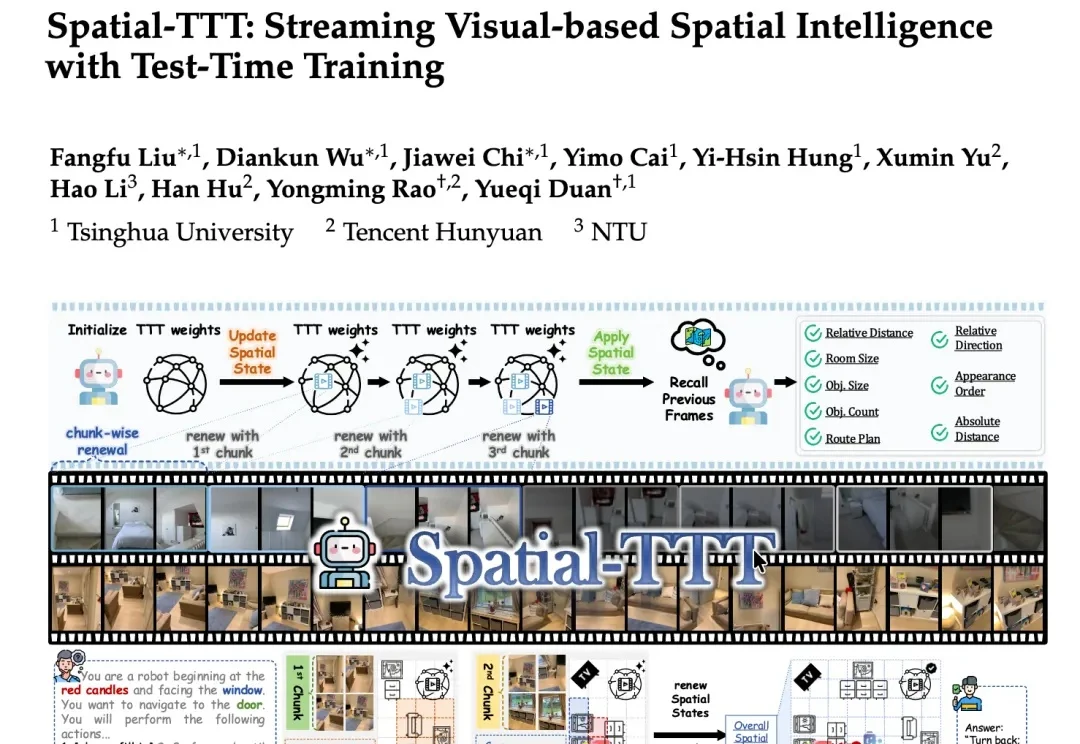
在机器人、自动驾驶、AR等真实场景中,空间理解从来都不是“看一眼图像”就能解决的问题。
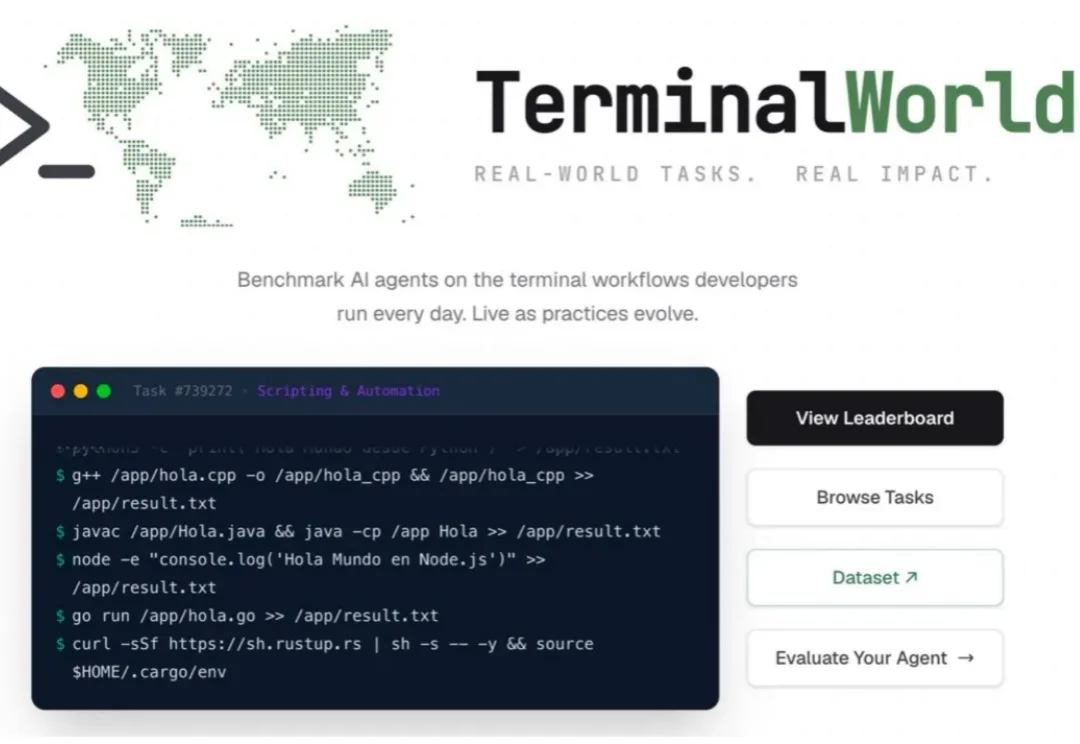
AI Agent 正在重塑软件开发。写代码、修 bug,它的能力肉眼可见地往上涨。但软件开发,从来不止 "写代码" 这一件事。装环境、配依赖、部署服务、编排容器、管理云资源、处理安全策略,这些 "让软件活起来" 的脏活累活,才是真实开发的大头。而它们,几乎都发生在同一个地方:终端。
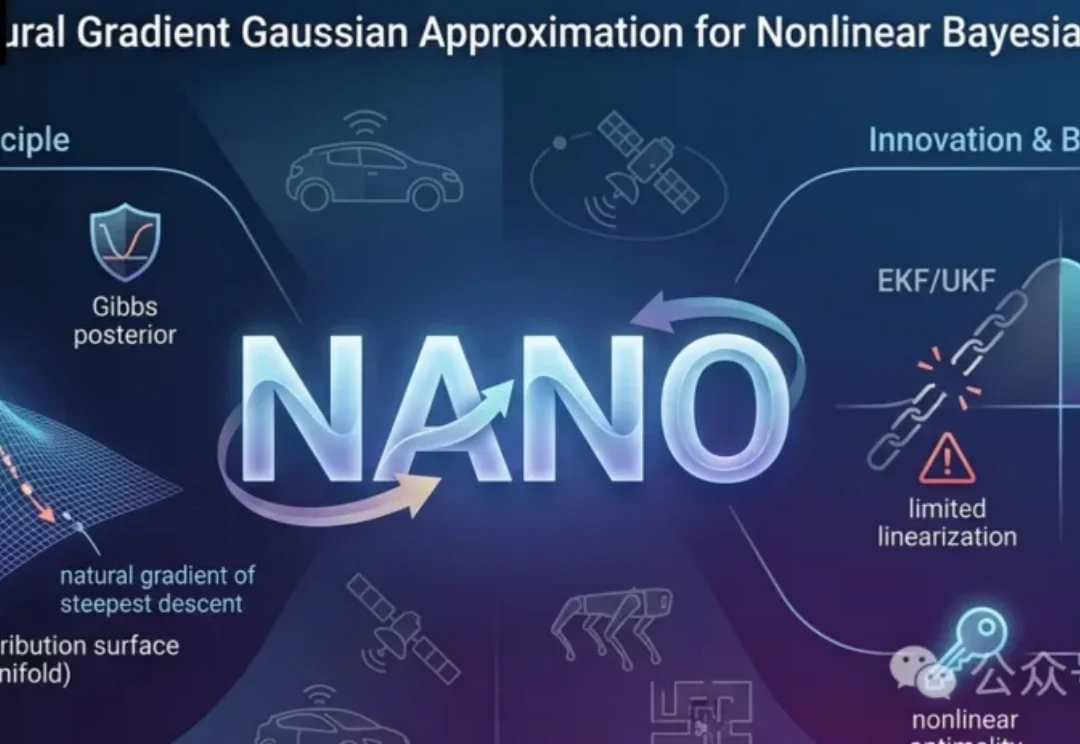
NANO滤波器是一种新的非线性贝叶斯状态估计方法,它不依赖线性化模型,而是将预测和更新步骤转化为优化问题。这种方法在高斯分布空间中使用自然梯度,更精确地逼近最优后验,同时利用Stein引理避免显式求导,提升鲁棒性。