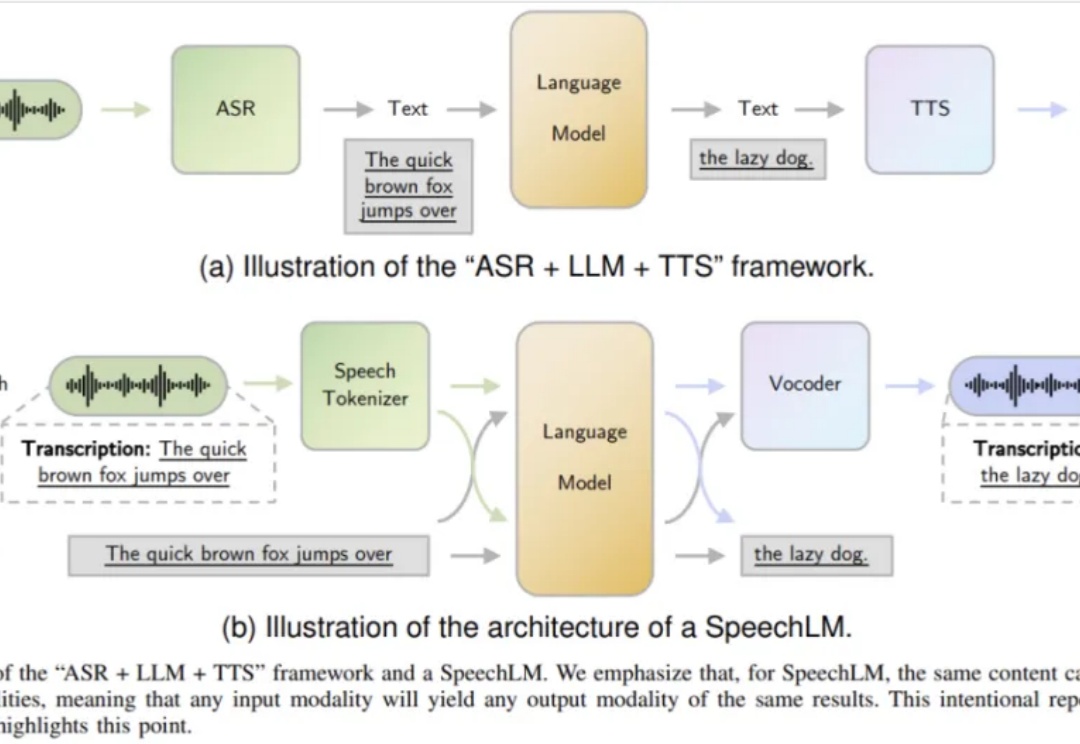
首个全面梳理语音大模型发展脉络的权威综述,入选ACL 2025主会
首个全面梳理语音大模型发展脉络的权威综述,入选ACL 2025主会由香港中文大学团队撰写的语音语言模型综述论文《Recent Advances in Speech Language Models: A Survey》已成功被 ACL 2025 主会议接收!这是该领域首个全面系统的综述,为语音 AI 的未来发展指明了方向。
来自主题: AI技术研报
9004 点击 2025-06-17 16:45
 搜索
搜索
由香港中文大学团队撰写的语音语言模型综述论文《Recent Advances in Speech Language Models: A Survey》已成功被 ACL 2025 主会议接收!这是该领域首个全面系统的综述,为语音 AI 的未来发展指明了方向。

思维链(Chain of Thought, CoT)推理方法已被证明能够显著提升大语言模型(LLMs)在复杂任务中的表现。而在多模态大语言模型(MLLMs)中,CoT 同样展现出了巨大潜力。
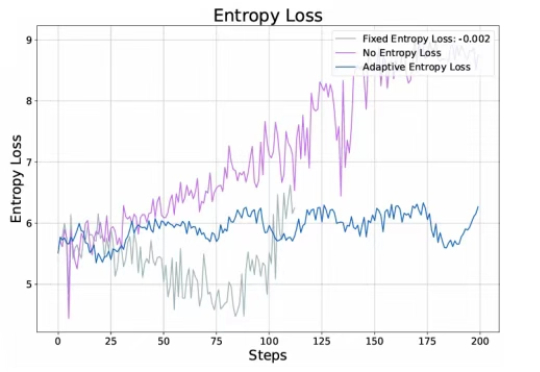
近年来,链式推理和强化学习已经被广泛应用于大语言模型,让大语言模型的推理能力得到了显著提升。

您有没有发现一个奇怪的现象:同样是Vibe coding,有些人轻松拿到完整的Flask应用,有些人却只得到几行if-else语句?剑桥大学计算机科学与技术系的研究者们最近发布了一项研究,用科学的方法证实了我们的直觉——AI确实会"看人下菜碟"。

当前,Agentic RAG(Retrieval-Augmented Generation)正逐步成为大型语言模型访问外部知识的关键路径。但在真实实践中,搜索智能体的强化学习训练并未展现出预期的稳定优势。一方面,部分方法优化的目标与真实下游需求存在偏离,另一方面,搜索器与生成器间的耦合也影响了泛化与部署效率。
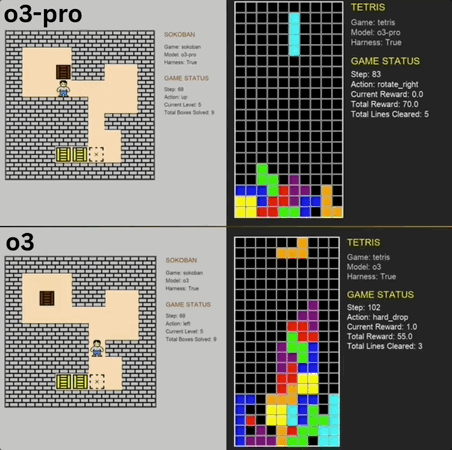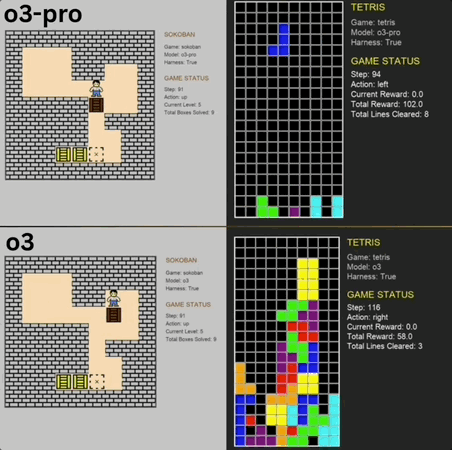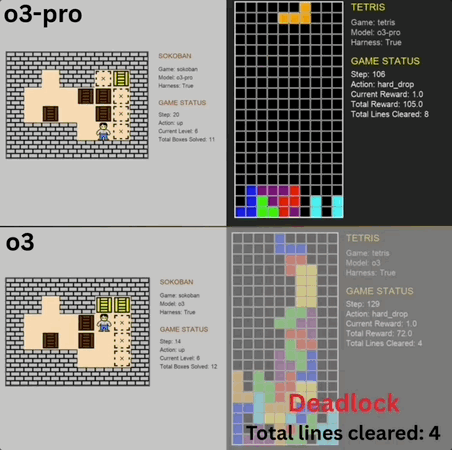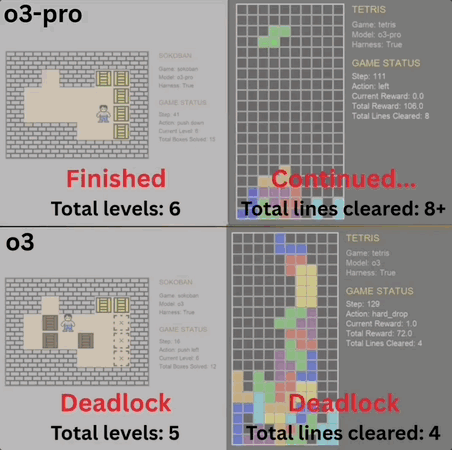
推箱子、俄罗斯方块……这些人类的经典怀旧小游戏,也成大模型benchmark了。 o3-pro刚刚也挑战了这两款游戏,而且表现还都不错,直接突破了benchmark上限
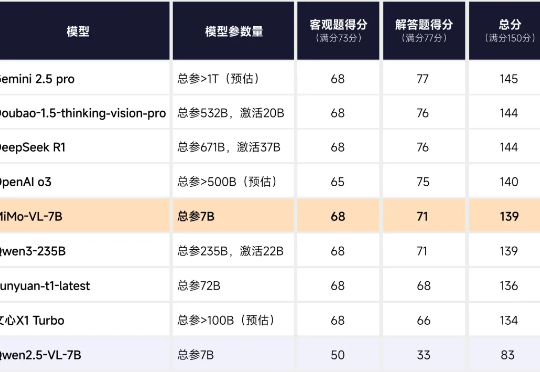
上上周的 2025 高考已经落下了帷幕!在人工智能领域,各家大模型向数学卷发起了挑战。
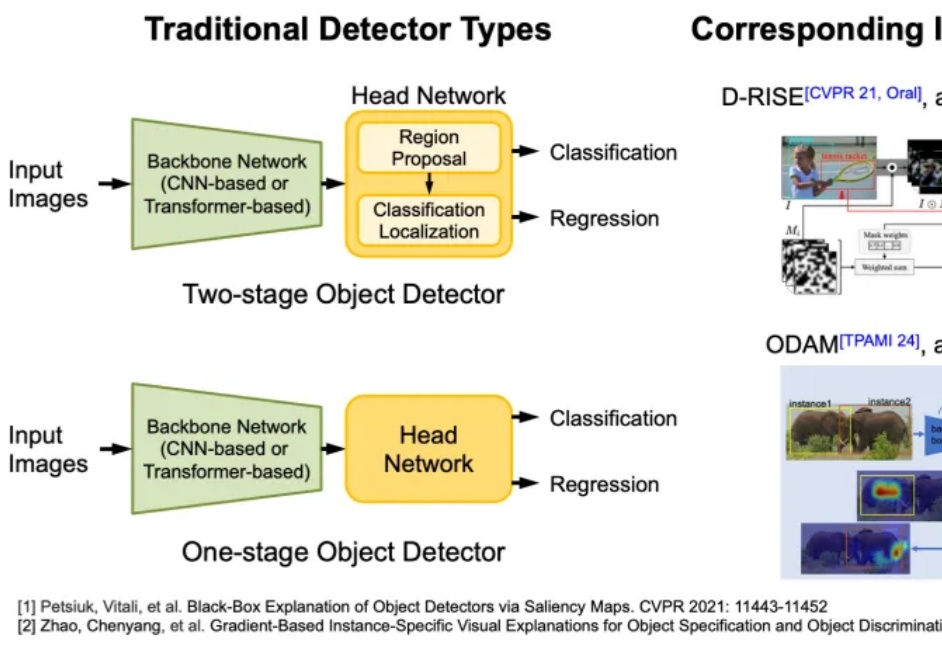
AI 决策的可靠性与安全性是其实际部署的核心挑战。当前智能体广泛依赖复杂的机器学习模型进行决策,但由于模型缺乏透明性,其决策过程往往难以被理解与验证,尤其在关键场景中,错误决策可能带来严重后果。因此,提升模型的可解释性成为迫切需求。
推理大模型虽好,但一个简单的算数问题能推理整整三页,还都是重复的“废话”,找不到重点……

苹果一篇论文,再遭打脸。研究员联手Claude Opus用一篇4页论文再反击,揭露实验设计漏洞,甚至指出部分测试无解却让模型「背锅」的华点。