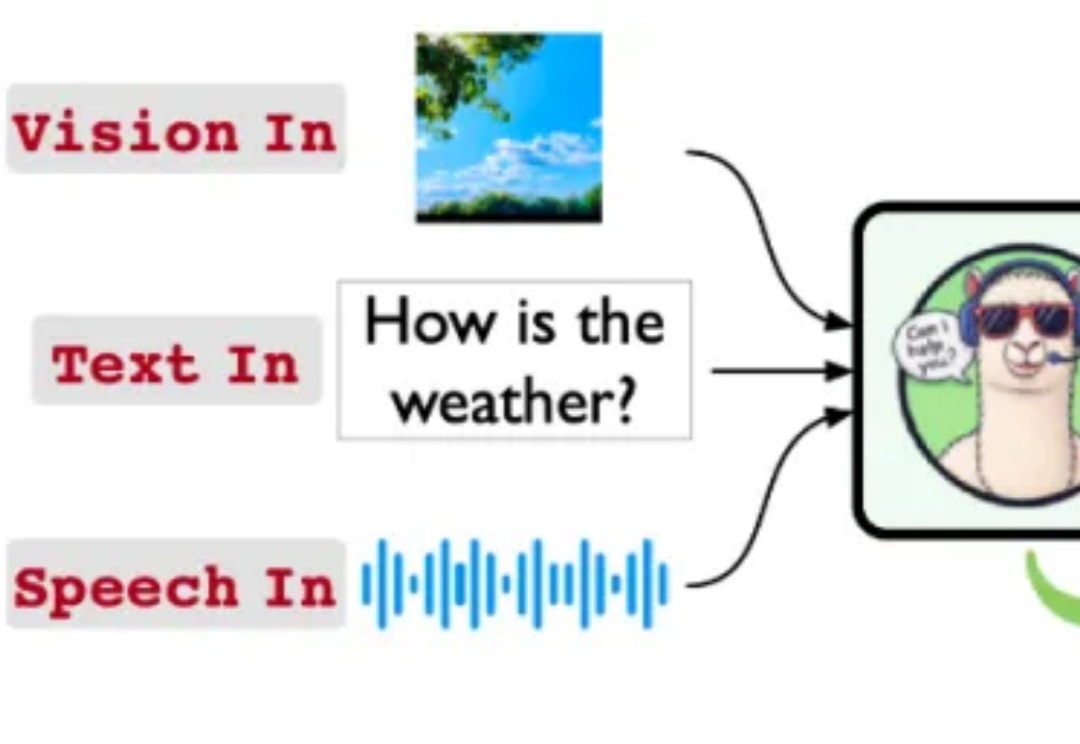
Stream-Omni:同时支持各种模态组合交互的文本-视觉-语音多模态大模型
Stream-Omni:同时支持各种模态组合交互的文本-视觉-语音多模态大模型Stream-Omni:同时支持各种模态组合交互的文本-视觉-语音多模态大模型
来自主题: AI技术研报
9447 点击 2025-07-07 14:19
 搜索
搜索
Stream-Omni:同时支持各种模态组合交互的文本-视觉-语音多模态大模型
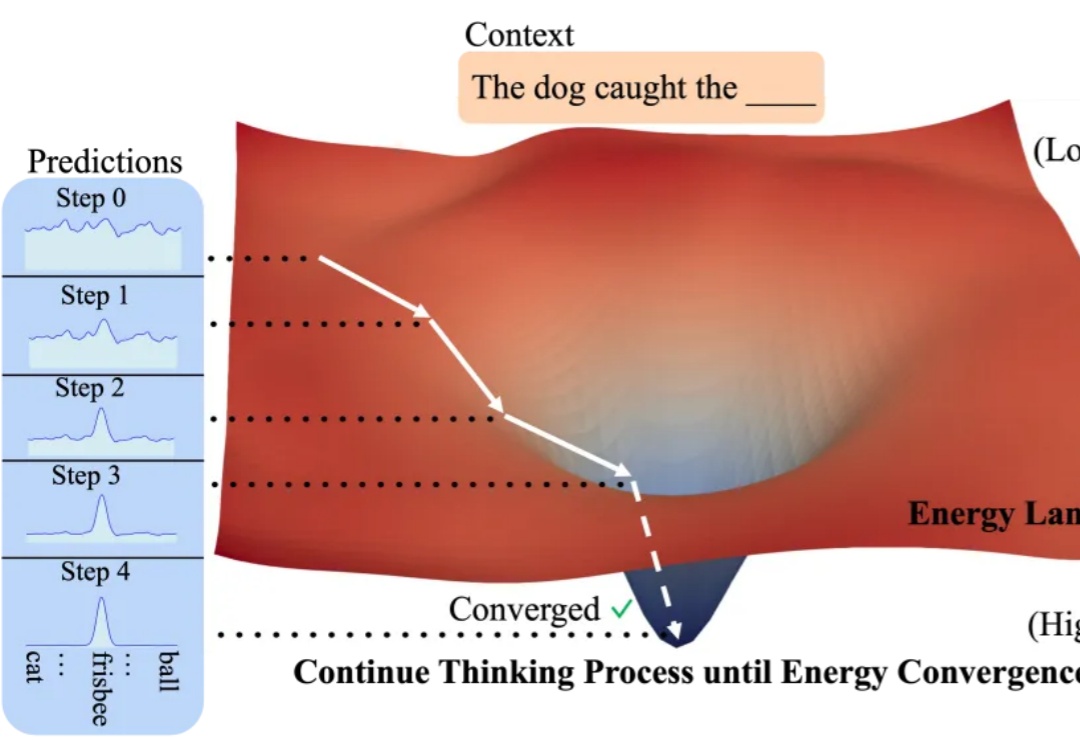
是否可以在不依赖额外监督的前提下,仅通过无监督学习让模型学会思考? 答案有了。
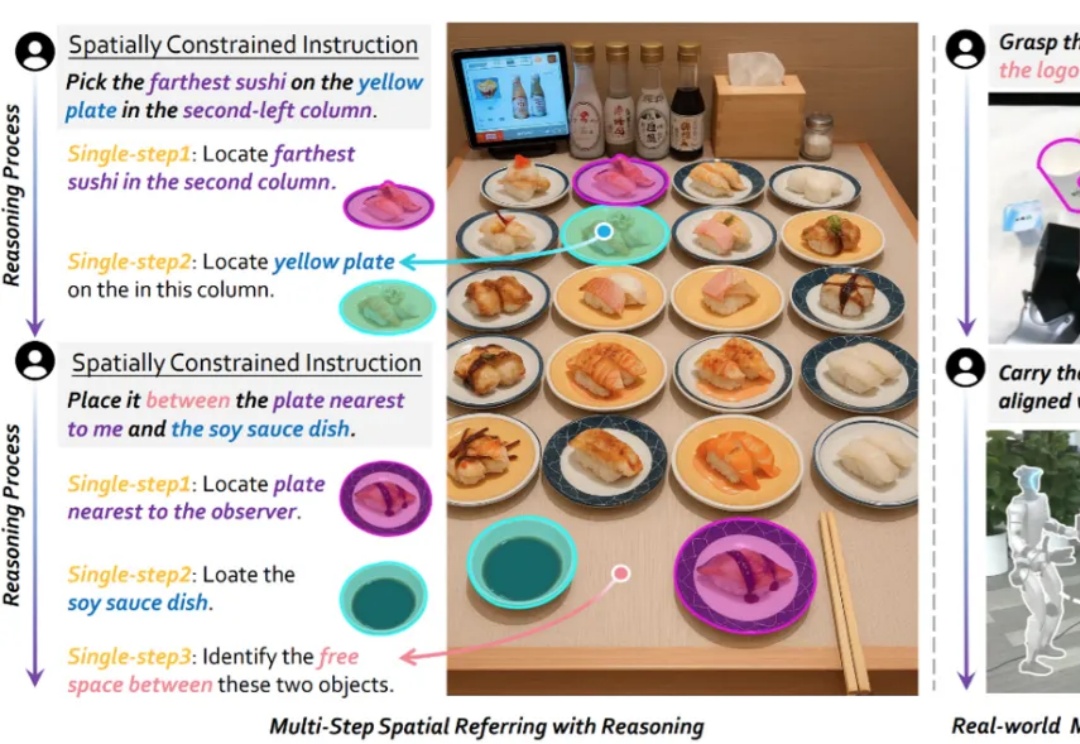
机器人走出实验室、进入真实世界真正可用,远比想象中更复杂。现实环境常常杂乱无序、物体种类繁多、灵活多变,远不像实验室那样干净、单一、可控。
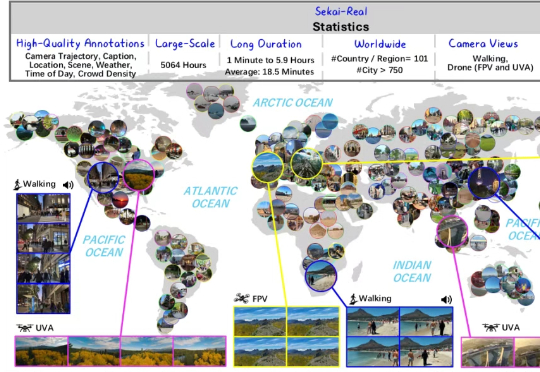
现在,国内研究机构就从数据基石的角度出发,拿出了还原真实动态世界的新进展:上海人工智能实验室、北京理工大学、上海创智学院、东京大学等机构聚焦世界生成的第一步——世界探索,联合推出一个持续迭代的高质量视频数据集项目——Sekai(日语意为“世界”),服务于交互式视频生成、视觉导航、视频理解等任务,旨在利用图像、文本或视频构建一个动态且真实的世界,可供用户不受限制进行交互探索。
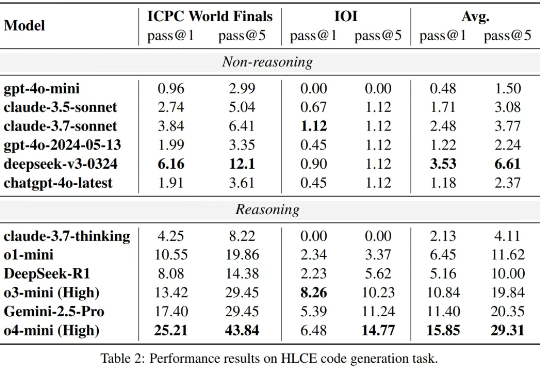
大语言模型(LLM)在标准编程基准测试(如 HumanEval,Livecodebench)上已经接近 “毕业”,但这是否意味着它们已经掌握了人类顶尖水平的复杂推理和编程能力?
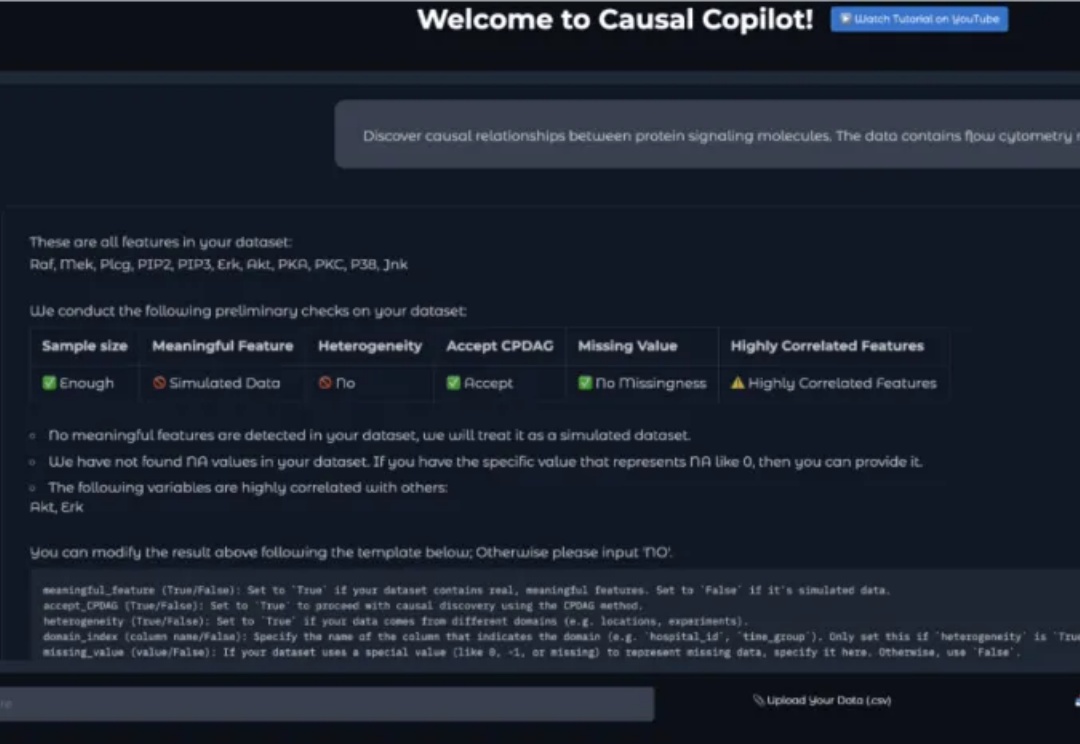
想象这样一个场景:你是一位生物学家,手握基因表达数据,直觉告诉你某些基因之间存在调控关系,但如何科学地验证这种关系?你听说过 "因果发现" 这个词,但对于具体算法如 PC、GES 就连名字都非常陌生。
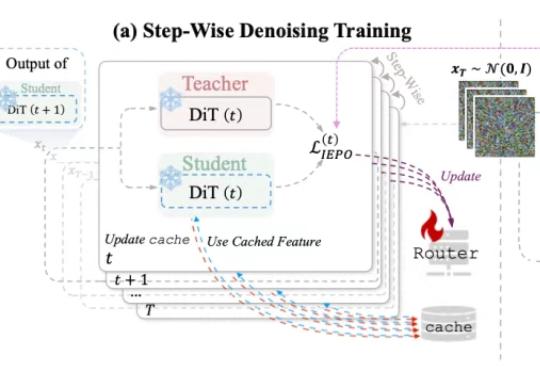
面对扩散模型推理速度慢、成本高的问题,HKUST&北航&商汤提出了全新缓存加速方案——HarmoniCa:训练-推理协同的特征缓存加速框架,突破DiT架构在部署端的速度瓶颈,成功实现高性能无损加速。
2017 年,一篇《Attention Is All You Need》论文成为 AI 发展的一个重要分水岭,其中提出的 Transformer 依然是现今主流语言模型的基础范式。尤其是在基于 Transformer 的语言模型的 Scaling Law 得到实验验证后,AI 领域的发展更是进入了快车道。
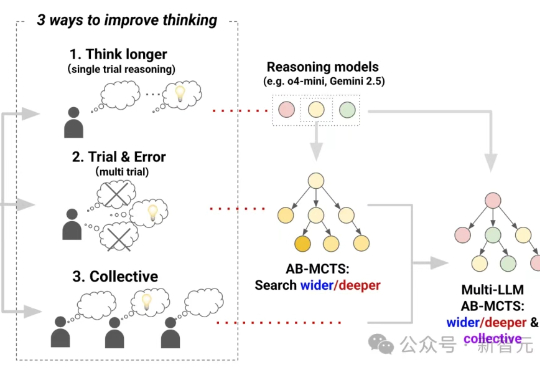
三个前沿AI能融合成AGI吗?Sakana AI提出Multi-LLM AB-MCTS方法,整合o4-mini、Gemini-2.5-Pro与DeepSeek-R1-0528模型,在推理过程中动态协作,通过试错优化生成过程,有效融合群体AI智慧。
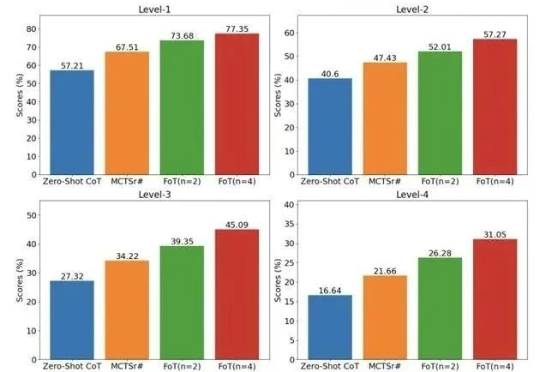
大模型越来越大,通用能力越来越强,但一遇到数学、科学、逻辑这类复杂问题,还是常“翻车”。为破解这一痛点,华为诺亚方舟实验室提出全新高阶推理框架 ——思维森林(Forest-of-Thought,FoT)。