
颠覆搜索引擎,下一代Agentic Deep Research!12家顶尖学术机构联手提出
颠覆搜索引擎,下一代Agentic Deep Research!12家顶尖学术机构联手提出在信息爆炸的时代,传统关键词搜索已难以满足复杂知识需求。最新研究提出Agentic Deep Research
来自主题: AI技术研报
11147 点击 2025-07-08 12:35
 搜索
搜索
在信息爆炸的时代,传统关键词搜索已难以满足复杂知识需求。最新研究提出Agentic Deep Research
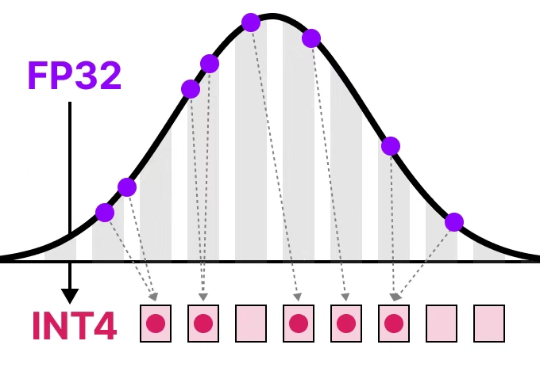
清华大学朱军教授团队提出SageAttention3,利用FP4量化实现推理加速,比FlashAttention快5倍,同时探索了8比特注意力用于训练任务的可行性,在微调中实现了无损性能。

当LangChain在6月23日发布那篇著名的Context Engineering博客时,IBM Research的研究者们早在10天前就已经用严格的学术实验证明了这套方法的有效性。
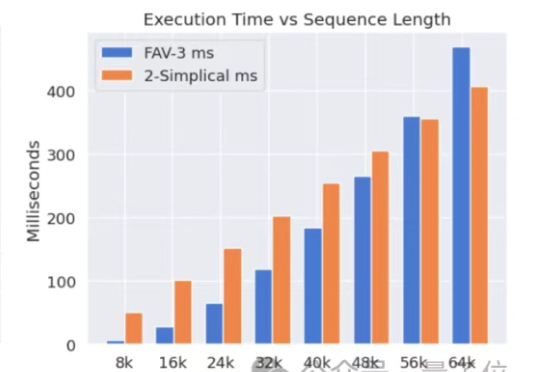
Meta挖走OpenAI大批员工后,又用OpenAI的技术搞出新突破。新架构名为2-Simplicial Transformer,重点是通过修改标准注意力,让Transformer能更高效地利用训练数据,以突破当前大模型发展的数据瓶颈。
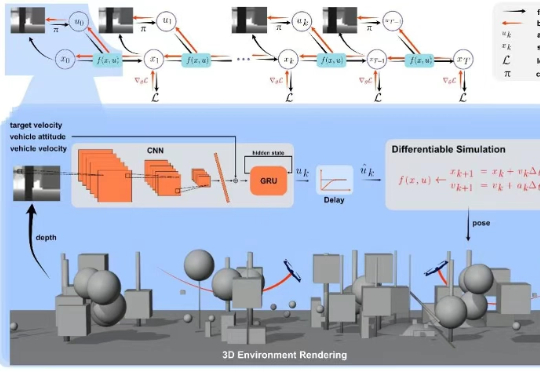
上海交通大学研究团队提出了一种融合无人机物理建模与深度学习的端到端方法,该研究首次将可微分物理训练的策略成功部署到现实机器人中,实现了无人机集群自主导航,并在鲁棒性、机动性上大幅领先现有的方案。
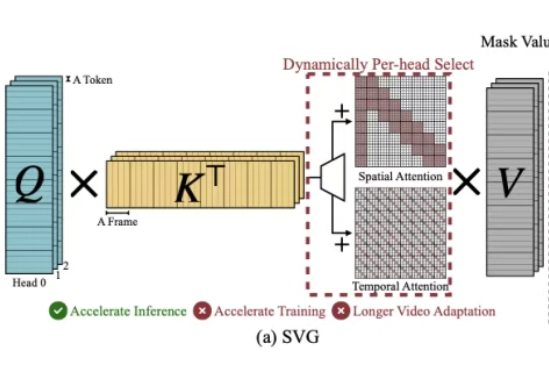
刷到1分钟AI短视频别只顾着点赞,背后的算力成本让人惊叹。MIT和英伟达等提出的径向注意力技术让长视频生成成本暴降4.4倍,速度飙升3.7倍,AI视频的未来已来!
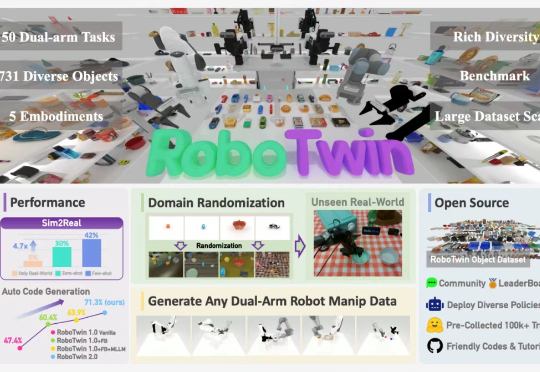
最近,上海交通大学 ScaleLab 与香港大学 MMLab@HKU 领衔发布 RoboTwin 系列新作 RoboTwin 2.0 以及基于 RoboTwin 仿真平台在 CVPR 上举办的双臂协作竞赛 Technical Report。
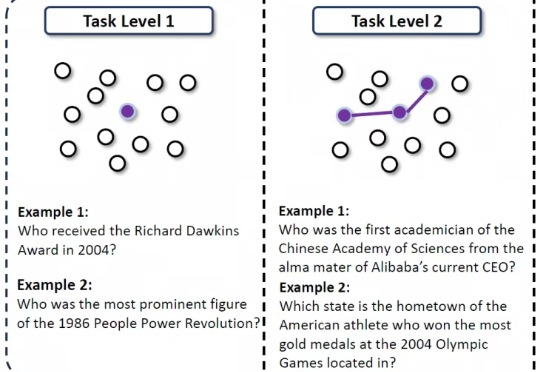
在互联网信息检索任务中,即使是很强的LLM,有时也会陷入“信息迷雾”之中:当问题简单、路径明确时,模型往往能利用记忆或一两次搜索就找到答案;但面对高度不确定、线索模糊的问题,模型就很难做对。

在开发DeepResearch时,生成多样化的查询 (query) 是一个关键细节。我们在开发时会在至少两处遇到这个问题。
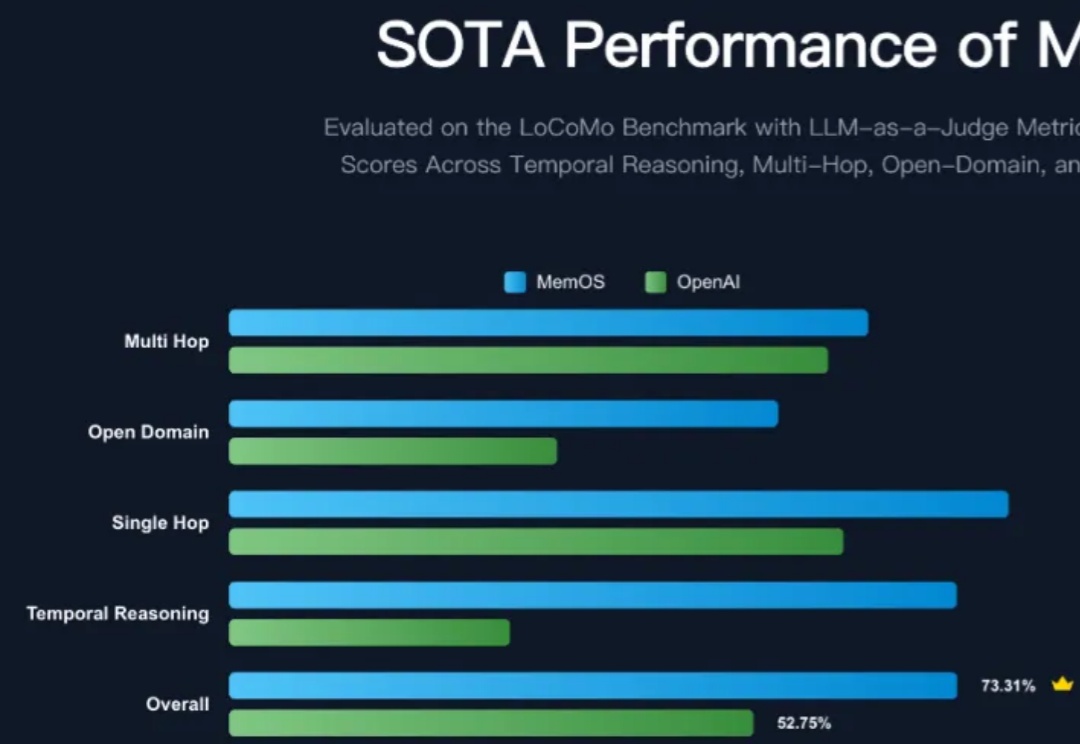
大模型记忆管理和优化框架是当前各大厂商争相优化的热点方向,MemOS 相比现有 OpenAI 的全局记忆在大模型记忆评测集上呈现出显著的提升,平均准确性提升超过 38.97%,Tokens 的开销进一步降低 60.95%,一举登顶记忆管理的 SOTA 框架,特别是在考验框架时序建模与检索能力的时序推理任务上,提升比例更是达到了 159%,相当震撼!