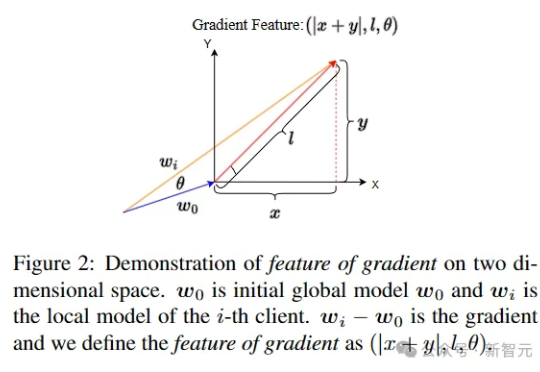
攻克「恶意投毒」攻击!华南理工联合霍普金斯和UCSD,连登TPAMI、TIFS顶刊
攻克「恶意投毒」攻击!华南理工联合霍普金斯和UCSD,连登TPAMI、TIFS顶刊华南理工大学计算机学院AI安全团队长期深耕于人工智能安全,近期联合约翰霍普金斯大学和加州大学圣地亚戈分校聚焦于联邦学习中防范恶意投毒攻击,产出工作连续发表于AI顶刊TPAMI 2025和网络安全顶刊TIFS 2025。
来自主题: AI技术研报
8558 点击 2025-07-13 11:45
 搜索
搜索
华南理工大学计算机学院AI安全团队长期深耕于人工智能安全,近期联合约翰霍普金斯大学和加州大学圣地亚戈分校聚焦于联邦学习中防范恶意投毒攻击,产出工作连续发表于AI顶刊TPAMI 2025和网络安全顶刊TIFS 2025。
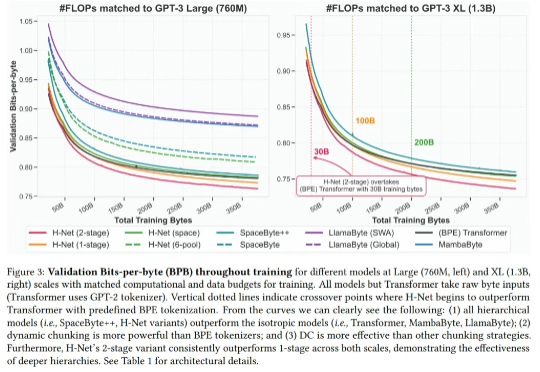
最近,Mamba 作者之一 Albert Gu 又发新研究,他参与的一篇论文《 Dynamic Chunking for End-to-End Hierarchical Sequence Modeling 》提出了一个分层网络 H-Net,其用模型内部的动态分块过程取代 tokenization,从而自动发现和操作有意义的数据单元。
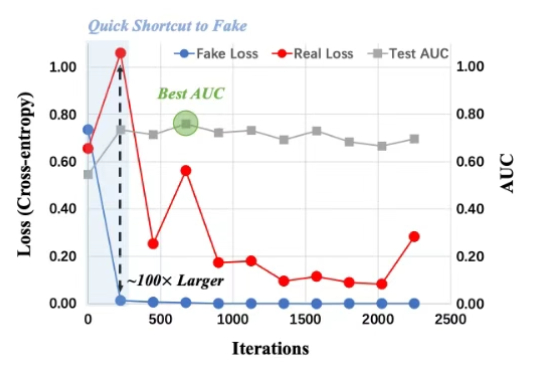
随着 OpenAI 推出 GPT-4o 的图像生成功能,AI 生图能力被拉上了一个新的高度,但你有没有想过,这光鲜亮丽的背后也隐藏着严峻的安全挑战:如何区分生成图像和真实图像?

「停止研究 RL 吧,研究者更应该将精力投入到产品开发中,真正推动人工智能大规模发展的关键技术是互联网,而不是像 Transformer 这样的模型架构。」
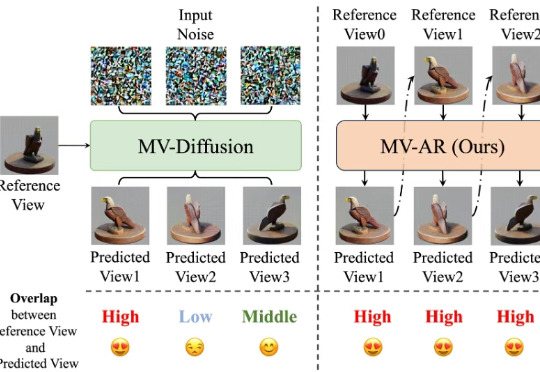
本文介绍并开发了一种自回归生成多视图图像的方法 MVAR 。其目的是确保在生成当前视图的过程中,模型能够从所有先前的视图中提取有效的引导信息,从而增强多视图的一致性。

在机器人操控领域,实现高频响应与复杂推理的统一,一直是一个重大技术挑战。近期,北京大学与香港中文大学的研究团队联合发布了名为 Fast-in-Slow(FiS-VLA) 的全新双系统视觉 - 语言 - 动作模型。
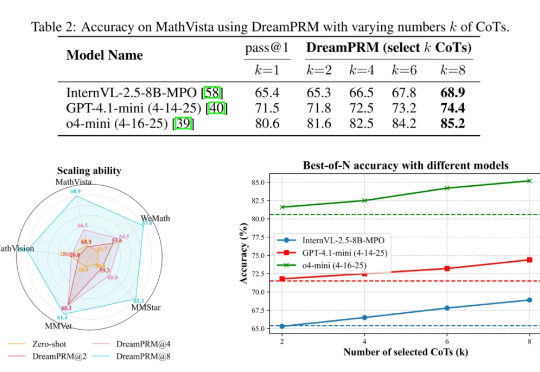
使用过程奖励模型(PRM)强化大语言模型的推理能力已在纯文本任务中取得显著成果,但将过程奖励模型扩展至多模态大语言模型(MLLMs)时,面临两大难题:
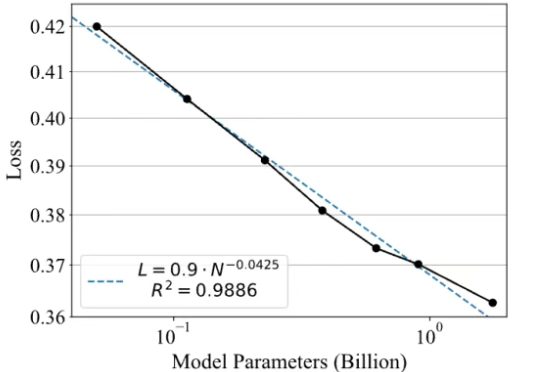
强化学习改变了大语言模型的后训练范式,可以说,已成为AI迈向AGI进程中的关键技术节点。然而,其中奖励模型的设计与训练,始终是制约后训练效果、模型能力进一步提升的瓶颈所在。
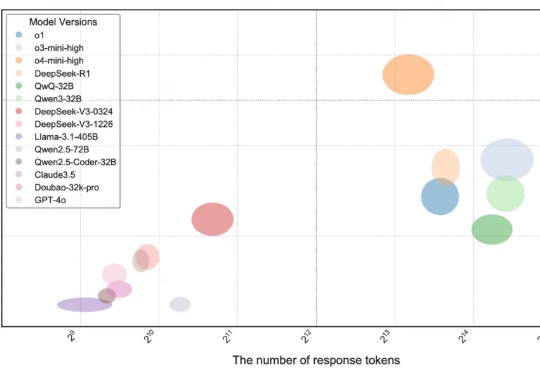
当前,大语言模型(LLMs)在编程领域的能力受到广泛关注,相关论断在市场中普遍存在,例如 DeepMind 的 AlphaCode 曾宣称达到人类竞技编程选手的水平
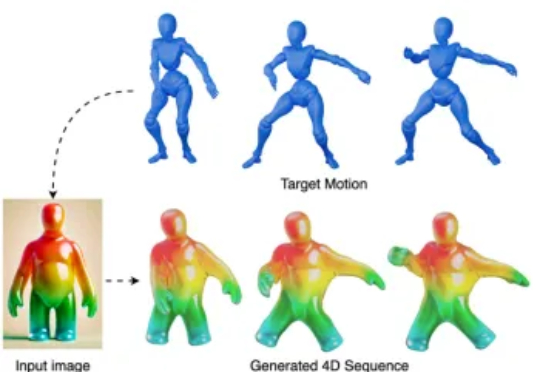
作者:张昊,伊利诺伊大学香槟分校博士生,研究方向为 3D/4D 重建、生成建模与物理驱动动画。