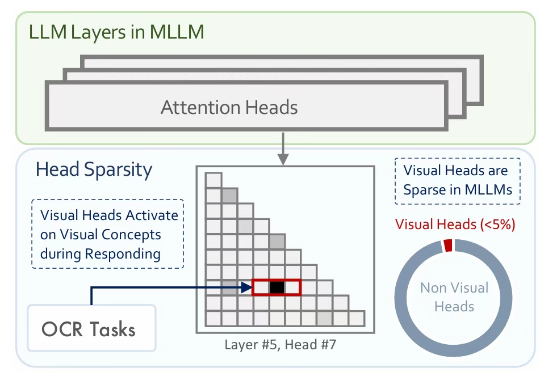
ICCV 2025 | 清华&腾讯混元X发现「视觉头」机制:仅5%注意力头负责多模态视觉理解
ICCV 2025 | 清华&腾讯混元X发现「视觉头」机制:仅5%注意力头负责多模态视觉理解多模态大模型通常是在大型预训练语言模型(LLM)的基础上扩展而来。尽管原始的 LLM 并不具备视觉理解能力,但经过多模态训练后,这些模型却能在各类视觉相关任务中展现出强大的表现。
来自主题: AI技术研报
8407 点击 2025-07-15 10:07
 搜索
搜索
多模态大模型通常是在大型预训练语言模型(LLM)的基础上扩展而来。尽管原始的 LLM 并不具备视觉理解能力,但经过多模态训练后,这些模型却能在各类视觉相关任务中展现出强大的表现。
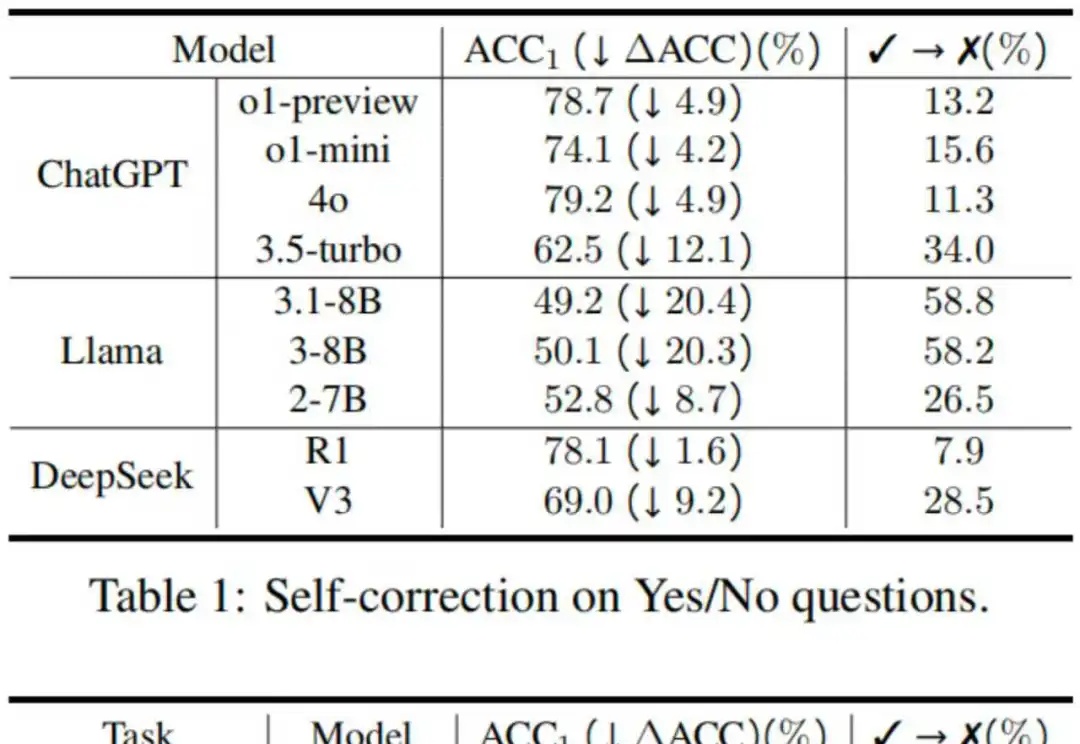
反思技术因其简单性和有效性受到了广泛的研究和应用,具体表现为在大语言模型遇到障碍或困难时,提示其“再想一下”,可以显著提升性能 [1]。然而,2024 年谷歌 DeepMind 的研究人员在一项研究中指出,大模型其实分不清对与错,如果不是仅仅提示模型反思那些它回答错误的问题,这样的提示策略反而可能让模型更倾向于把回答正确的答案改错 [2]。
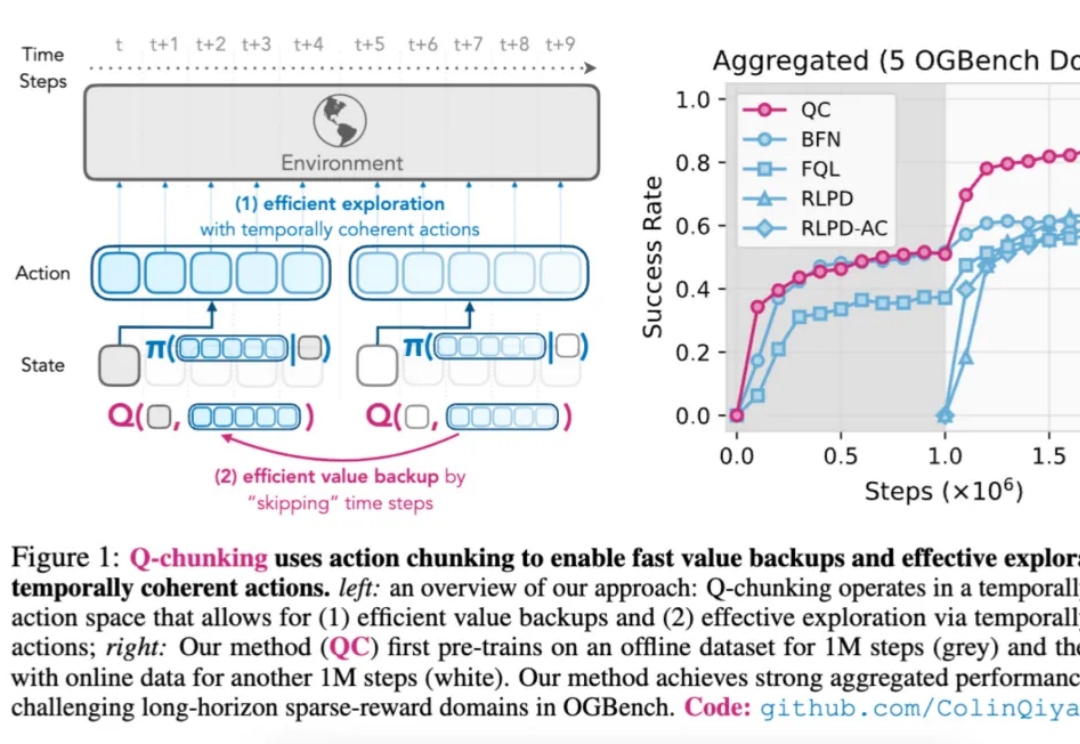
如今,强化学习(Reinforcement Learning,RL)在多个领域已取得显著成果。
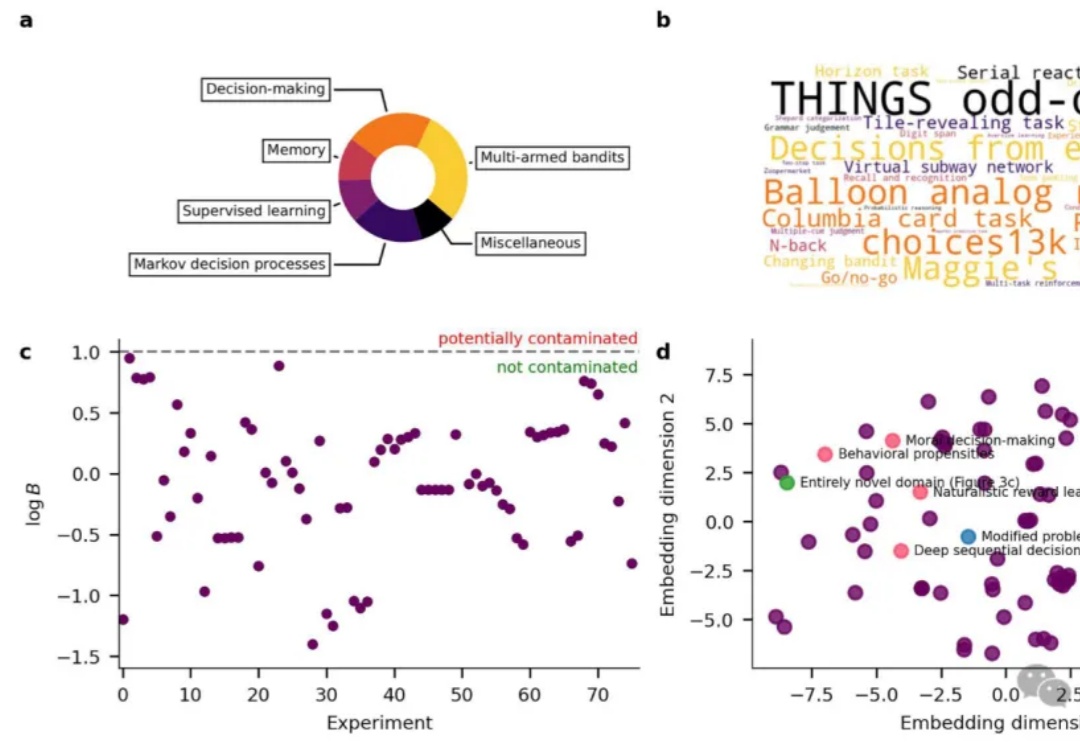
首个能跨领域精准预测人类认知的基础模型诞生!
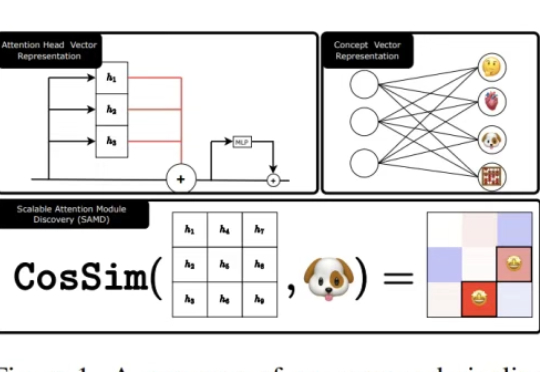
AI也能选择性失忆?Meta联合NYU发布新作,轻松操控缩放Transformer注意头,让大模型「忘掉狗会叫」。记忆可删、偏见可调、安全可破,掀开大模型「可编辑时代」,安全边界何去何从。

现在人工智能领域面临的最大挑战是广义的具身智能,即使你并不特别关心大脑本身……
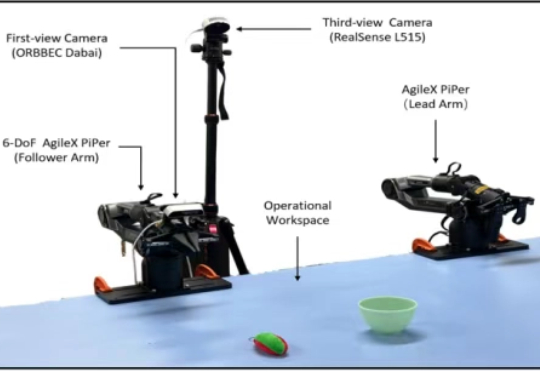
近年来,视觉 - 语言 - 动作(Vision-Language-Action, VLA)模型因其出色的多模态理解与泛化能力,已成为机器人领域的重要研究方向。尽管相关技术取得了显著进展,但在实际部署中,尤其是在高频率和精细操作等任务中,VLA 模型仍受到推理速度瓶颈的严重制约。
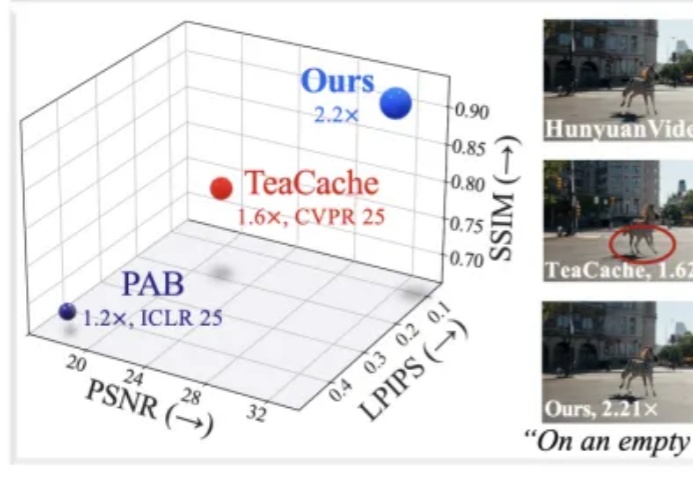
近年来,随着扩散模型(Diffusion Models)和扩散 Transformer(DiT)在视频生成领域的广泛应用,AI 合成视频的质量和连贯性有了飞跃式提升。像 OpenAI Sora、HunyuanVideo、Wan2.1 等大模型,已经能够生成结构清晰、细节丰富且高度连贯的长视频内容,为数字内容创作、虚拟世界和多媒体娱乐带来了巨大变革。
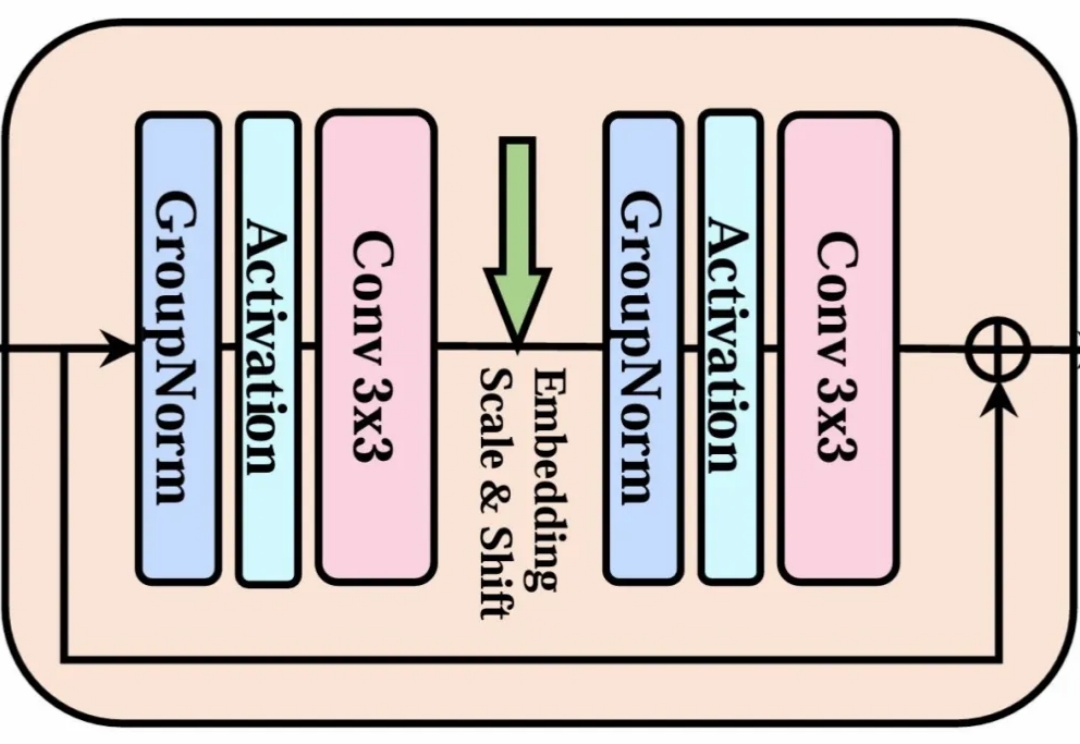
当整个 AI 视觉生成领域都在 Transformer 架构上「卷生卷死」时,一项来自北大、北邮和华为的最新研究却反其道而行之,重新审视了深度学习中最基础、最经典的模块——3x3 卷积。

近年来,多模态大模型(MLLMs)发展迅猛,从看图说话到视频理解,似乎无所不能。