
担心蒸馏问题,Meta限用Claude Code、Codex
担心蒸馏问题,Meta限用Claude Code、Codex据外媒 The Information 报道:Meta 正在限制员工在 AI 模型构建中使用 Claude Code 和 Codex,原因是担心涉及模型蒸馏。 Meta 担心这些外部模型生成的内容,可能进入自家的训练数据或评测体系,从而引发所谓的模型蒸馏争议。
来自主题: AI资讯
9363 点击 2026-06-30 12:15
 搜索
搜索
据外媒 The Information 报道:Meta 正在限制员工在 AI 模型构建中使用 Claude Code 和 Codex,原因是担心涉及模型蒸馏。 Meta 担心这些外部模型生成的内容,可能进入自家的训练数据或评测体系,从而引发所谓的模型蒸馏争议。
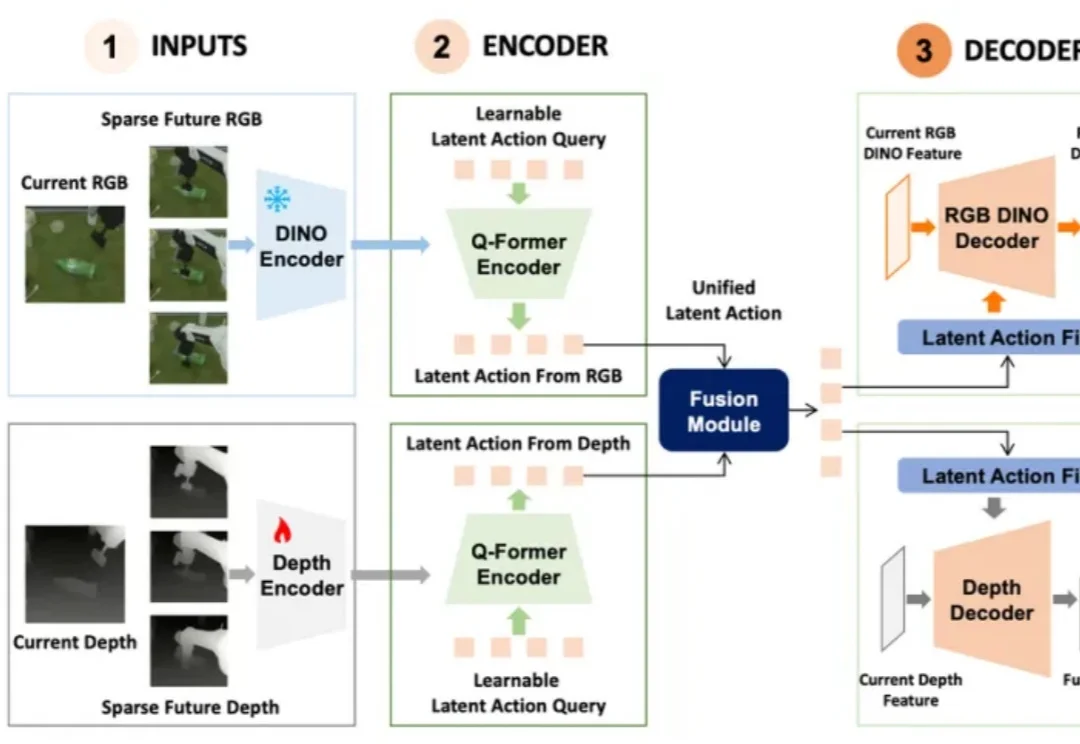
当前,物理 AI 正面临着关于泛化能力的普遍质疑。当模型缺乏对真实物理规律的深度认知、难以跨越复杂多变的开放场景时,如何让机器人真正理解物理世界并精准规划决策,已成为具身智能破局的关键。

6月22日Claude全家桶集体宕机,只是冰山一角。当最强大模型被丢进真实机房直面「幽灵故障」,AISHPerf-智算运维智能体评测基准给出残酷答案:全军覆没,无一过50分。这道鸿沟,第一次被量化。

2026 年 6 月,大模型行业正在经历一场前所未有的「开源海啸」:英伟达放出了 550B 参数的混合架构模型,谷歌送出多模态的 Gemma 新版本,智谱用最宽松的协议全量开源了自家旗舰模型。

独家获悉,清华系初创公司「厘清智能」宣布完成数亿元种子轮融资,投资方阵容堪称豪华:由顺为资本、红杉中国、高瓴创投、峰瑞资本、星连资本、水木清华校友种子基金、SEE FUND等一线基金,与智元机器人、灵心巧手、世纪金源等产业资本共同投资。其中,顺为资本与红杉中国更是连续多轮追加投资。

如今,大模型越来越擅长回答问题了,但当 AI 不再只停留在聊天窗口,而是走向智能眼镜、可穿戴设备乃至家庭机器人时,问题会随之改变。用户未必有时间把需求完整说出来,也未必希望助手随时插话。更理想的助手,应该能在现场真正理解人,在用户需要的时候出现,在不合适的时候保持安静。

你有没有想过一个问题: 我们平时选模型,到底有多少是因为它真的好用,又有多少是因为它便宜?

2026年6月23日,字节跳动CEO梁汝波罕见地出现在火山引擎FORCE原动力大会的视频画面中。他没有选择现场登台,但视频透露了一个关键:“攀登AI高峰是字节当下最重要的事情”。紧接着,他补了一句更关键的判词:过去几年,字节一直在“聚焦收缩业务宽度”,把精力重点放到AI,在AI领域聚焦到提升模型能力。

随着全球智能体加速落地,算力需求呈指数级爆发,以 GPU 为核心的 AI 基础设施正变得愈发关键。据摩根士丹利报告预测,2028 年全球 AI 基础设施累计总投资将达 2.9 万亿美元。

你从桌上端起一杯水,大脑用了不到一秒,同时完成三件事: 估算杯子的重量,预判水面晃动的幅度,顺便绕开了旁边那个玻璃杯。