
AI厂商拿Robots协议当草纸,互联网秩序“礼乐崩坏”
AI厂商拿Robots协议当草纸,互联网秩序“礼乐崩坏”当数据拥有者不想给、AI厂商偏偏又很想要的情况下,结果就这样了。
来自主题: AI资讯
10312 点击 2024-06-29 11:20
 搜索
搜索
当数据拥有者不想给、AI厂商偏偏又很想要的情况下,结果就这样了。

在这个数据为王的时代,数据是人工智能的三大支柱之一,其重要性不言而喻。最近,OpenAI 收购了数据库初创公司 Rockset,迅速引起了业内外的广泛关注。OpenAI 早已在算法和计算能力方面遥遥领先,通过这次战略性的收购,OpenAI 将在其产品中融合 Rockset 的先进数据索引和查询技术,帮助 OpenAI 将数据转化为 “可操作智能”。

在当今的多模态大模型的发展中,模型的性能和训练数据的质量关系十分紧密,可以说是 “数据赋予了模型的绝大多数能力”。

近日,LeCun和谢赛宁等大佬,共同提出了这一种全新的SOTA MLLM——Cambrian-1。开创了以视觉为中心的方法来设计多模态模型,同时全面开源了模型权重、代码、数据集,以及详细的指令微调和评估方法。

自从ChatGPT出现以来,所有人都认为,未来很多工作都会被AI取代。

1981年,对冲基金传奇人物雷·达利欧提出,若存在一台存储世上所有事实数据并运行完美程序的计算机,未来即可被准确预测。 尽管我们尚未达到这一水平,但技术进步迅猛,以ChatGPT为代表的大型语言模型,已展现出预测未来的潜力。

AI 和数据库真正的大一统时代要来了?

是时候把数据Scale Down了!Llama 3揭示了这个可怕的事实:数据量从2T增加到15T,就能大力出奇迹,所以要想要有GPT-3到GPT-4的提升,下一代模型至少还要150T的数据。好在,最近有团队从CommonCrawl里洗出了240T数据——现在数据已经不缺了,但你有卡吗?

上周,不少人发现微软官网忽然更新了一条“GPT Builder 即将停用”的通知。宣布将从7月10日起终止对Copilot GPT的支持,并会在四天内把平台上所有已创建的GPT连同相关数据全部删除。
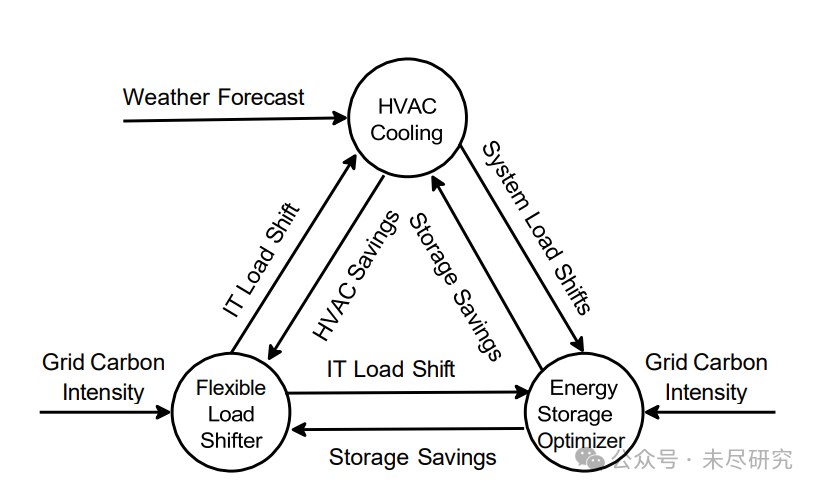
AI的终点是电力。因为数据中心最终要实现可持续发展,净零碳排放,AI的真正的终点是清洁电力。