
强化学习没作用?人大DelTA精准识别关键token,推理正确率大幅上升
强化学习没作用?人大DelTA精准识别关键token,推理正确率大幅上升做大模型RL微调,你是不是也踩过这些坑?
来自主题: AI技术研报
9811 点击 2026-07-03 09:49
 搜索
搜索
做大模型RL微调,你是不是也踩过这些坑?
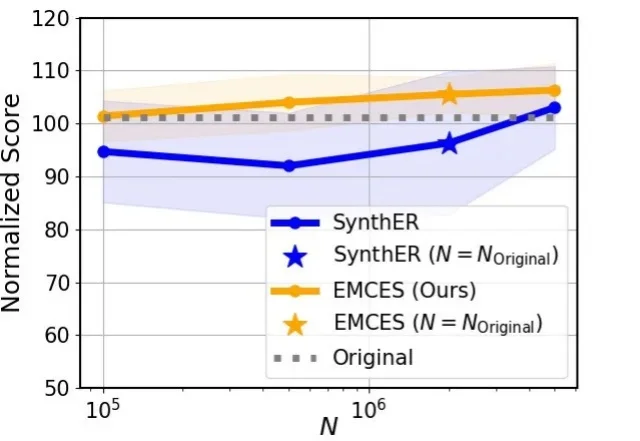
近年来,强化学习在游戏智能体、具身智能、大语言模型等领域取得了显著进展。然而,在真实世界中,强化学习仍面临一个核心难题:高质量样本的获取不仅成本高昂,还可能带来多种风险。因此,样本增强成为缓解强化学习中样本获取成本高、风险大等问题的重要途径之一。

公司由姚颂联合正大集团、清华青年学者于超共同发起,定位为物理智能系统公司,通过世界动作模型(WAM)与强化学习技术,推动机器人在真实商业与工业场景中落地,最终成为一个可信赖的机器人服务提供商。目前已完成近亿美元天使轮系列融资,投资方包括正大集团、华勤技术、九安医疗等多家上市企业,多位国内与国际知名企业家,以及多家一线投资机构。
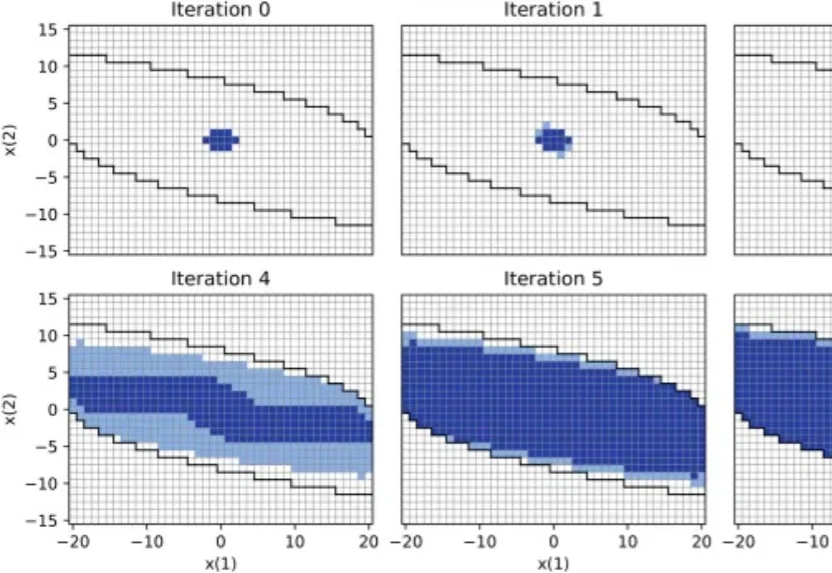
近日清华大学于IEEE TPAMI发表论文,探讨了真机强化学习的安全性保障问题,提出了一套「安全探索均衡」新型机制,揭示了安全探索的理论最大边界,并攻克了其收敛性证明难题。
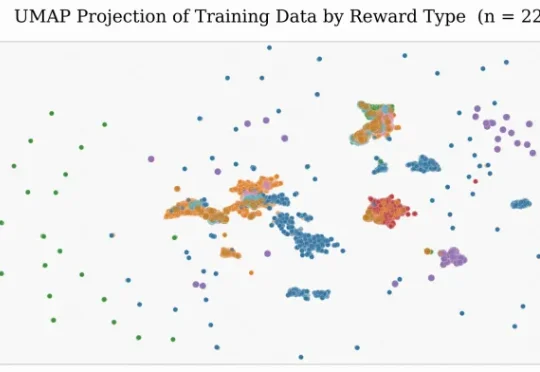
本研究由快手科技语言大模型团队完成,核心作者吕民轩、梅铁桦、杜坦隆等。快手科技与中国科学院大学联合提出 GoLongRL,一套完全开源的长上下文强化学习后训练方案,包含 23K 样本 RLVR 数据集

大语言模型的RL技术已日趋成熟,多模态生成模型的强化学习训练却仍在“各自为战”——图像扩散模型一套流程、视频生成另一套标准、VLM和LLM又有不同的技术栈。

随着大语言模型逐步从「单轮问答」走向「真实环境中的持续交互」,LLM agents 正在被用于越来越复杂的 agentic applications:deep research、coding、computer use、customer service、medical inquiry、troubleshooting 等等。

从 LLM 的超长文本处理、视频生成模型的以假乱真、Agent 自主规划与执行的日趋成熟,到 VLA、世界模型等开始进入物理世界,AI 正在不断拓宽其能力边界。

Mindverse 完成由美团领投的 A 轮融资,元禾璞华、韶音、变量资本和老股东追加跟投。Mindverse (心洲科技) 是少数把赌注押在模型「内部」的一家创企,它在通用大模型的基础上,用强化学习让它从复杂、多步骤的真实任务中学会如何把事做成,让模型从「知道很多」变为「能办好事」。
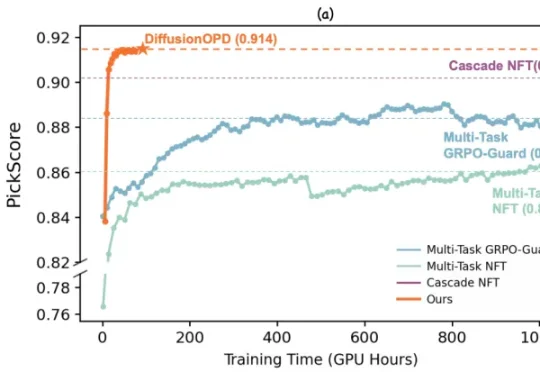
近期,来自复旦大学与阿里巴巴通义万相的研究团队对此提出了新的思考。他们认为,多任务强化学习不应被视为一个统一优化问题,而应该解耦为两个彼此独立的过程:单任务的在线策略探索 & 多任务能力整合。