
从Sora说起,全面解读AI视频大模型的发展史
从Sora说起,全面解读AI视频大模型的发展史Sora,OpenAI的人工智能AI生成式视频大模型,在2024年2月15日一经发布,就引发了全球关注,硅谷AI视频论文作者(非Sora)这样评价:相当好,这是毋庸置疑的No.1。
来自主题: AI资讯
8004 点击 2024-04-03 09:40
 搜索
搜索
Sora,OpenAI的人工智能AI生成式视频大模型,在2024年2月15日一经发布,就引发了全球关注,硅谷AI视频论文作者(非Sora)这样评价:相当好,这是毋庸置疑的No.1。

从2023年至今,做大模型、做生成式AI到底能不能赚钱,其实一直是行业里热议的话题。正值财报季,商汤集团也在近日公布了2023年业绩。财报显示,2023年公司整体营业收入34亿元人民币,其中生成式AI收入达12亿元,占集团总收入比例升至35%,实现近200%增长。

解决最短路径算法,也能被扩散模型完成。

生成式AI狂奔的2023年,美国在各个细分领域涌现出了一批独角兽公司。

自从Grok-1公开发布后,越来越多的人坐不住了。比如这家成立了11年的数据公司Databricks,他们就在Grok-1公开后的一个多礼拜,发布了自己的大模型DBRX。
4 月 2 日,昆仑万维 AI 音乐生成大模型「天工 SkyMusic」即日起面向社会开启免费邀测。

【新智元导读】Zoom AI通过独创的「联邦AI」的技术路线,联合多个大模型,在特定任务上超越GPT-4,体现出了多个大模型互帮互助的强大能力,而且成本也能控制在GPT-4一半的水品。
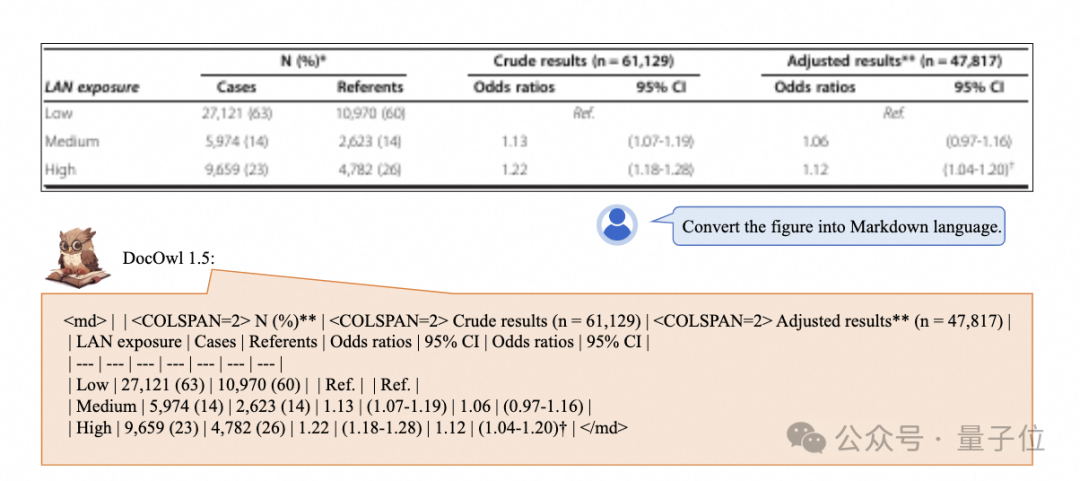
多模态文档理解能力新SOTA!阿里mPLUG团队发布最新开源工作mPLUG-DocOwl 1.5,针对高分辨率图片文字识别、通用文档结构理解、指令遵循、外部知识引入四大挑战,提出了一系列解决方案。

大模型长文本能力测试,又有新方法了!

作为 Meta 的前 CTO,Quora CEO Adam D'Angelo 目前还是 OpenAI 的董事会成员,在 Quora 之外推出的 Poe,成为当下接入大模型最多的 Chatbot 平台:GPT-4、Claude3、Mistral 等模型都有,用户也可以在上面搭建自己的 Chatbot 机器人,如果有别的用户使用,还可以产生收益。