
刚刚,豆包宣布收费
刚刚,豆包宣布收费今天,字节跳动旗下AI应用豆包正式推出专业版以及对应收费方案。豆包专业版基于最新的豆包2.1系列大模型,将提供更高的生产力场景使用额度,以及接入豆包2.1 Pro模型的全新“办公任务”模式。免费用户可以体验接入豆包2.1 Turbo模型的办公任务模式。
来自主题: AI资讯
9234 点击 2026-06-24 13:19
 搜索
搜索
今天,字节跳动旗下AI应用豆包正式推出专业版以及对应收费方案。豆包专业版基于最新的豆包2.1系列大模型,将提供更高的生产力场景使用额度,以及接入豆包2.1 Pro模型的全新“办公任务”模式。免费用户可以体验接入豆包2.1 Turbo模型的办公任务模式。

不用训练,不改权重,只动词表就能给大模型“消毒”?

Google DeepMind在6月份对外分享了DiffusionGemma的技术报告,明确指向了一条与现有主流完全不同的演进道路。当大家都在绞尽脑汁让大模型逐词吐字的速度变快时,谷歌干脆把生成顺序改了。

180 万亿。这是截至今年 6 月,豆包大模型的日均 token 调用量。
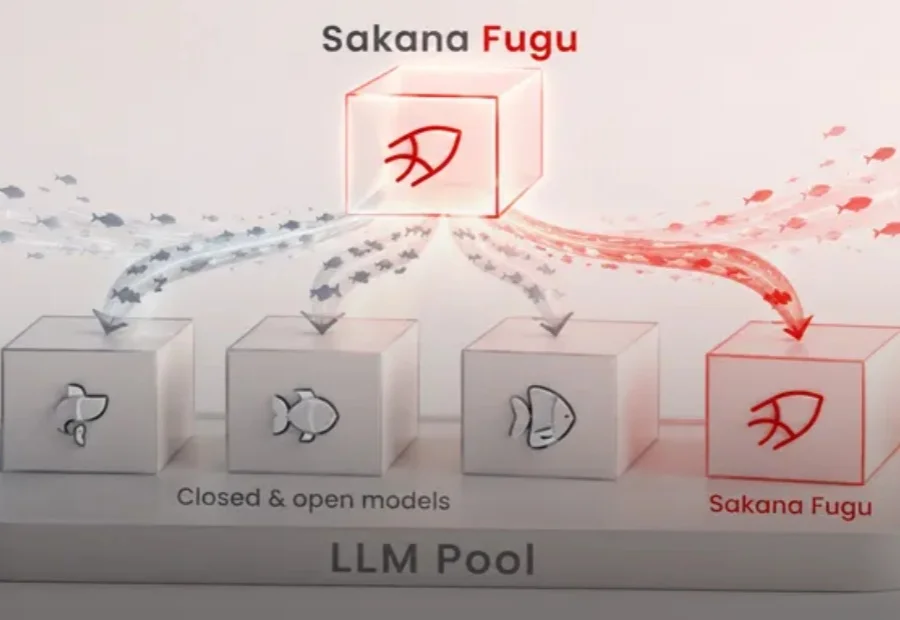

豆包大模型2.1 Pro正式发布。但字节这次没有像某些厂商那样疯狂堆参数、刷榜单,而是把刀锋对准了一个更硬核的方向:让AI真正能“干活” 。作为本次大会发布的主力模型,豆包2.1 Pro 在 Coding(编程)、Agent(智能体)、VLM(视觉语言模型)三大核心方向实现能力跃升,多项评测表现优于Claude Opus 4.6
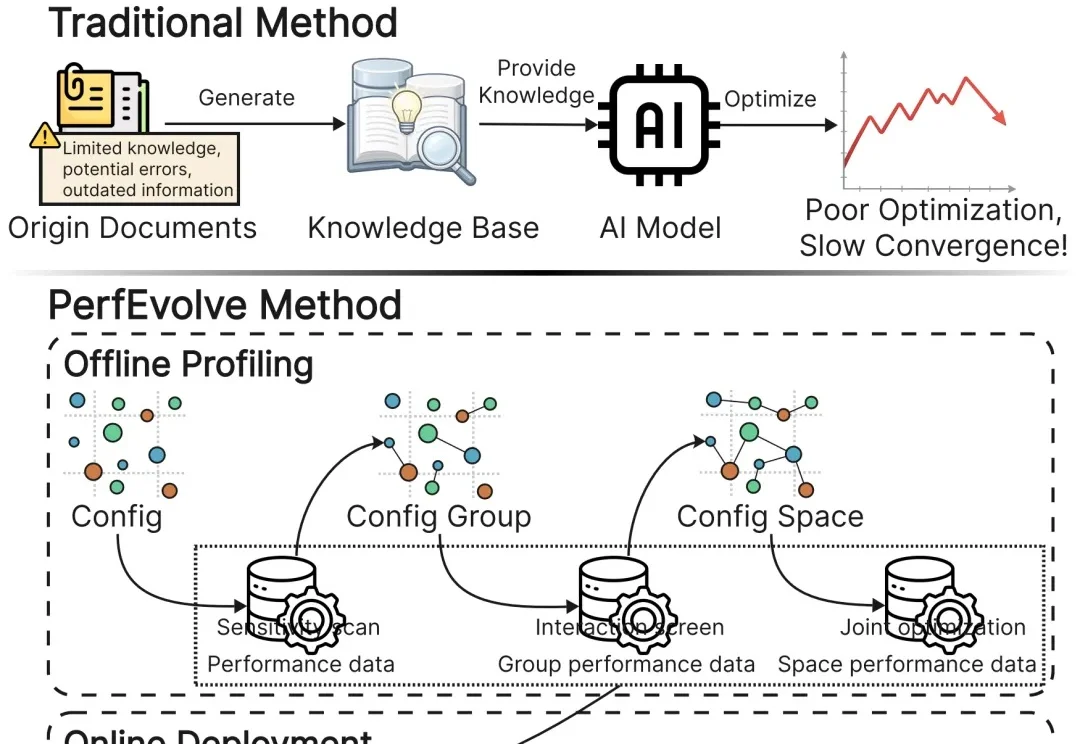
数据库自动调参,一直是大模型Agent的“看似完美、实则翻车”名场面。

好你个微软,当起大模型“倒爷”来了?!
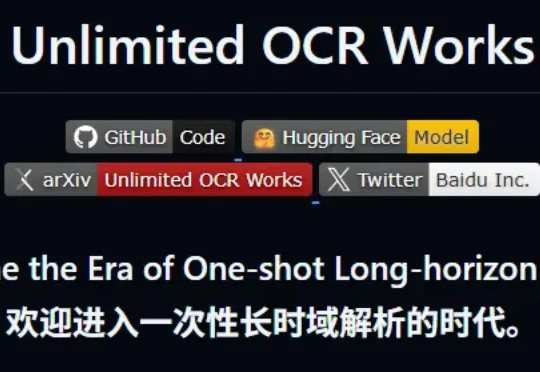
最新开源的Unlimited OCR,总参数3B,实际激活仅500M——放在大模型时代几乎是个零头。但就是这个小到离谱的模型,在OmniDocBench v1.5上拿下93.23%的综合分,v1.6更是达到93.92%,直接刷新了端到端SOTA。

当AI神话被账本照亮,最刺眼的真相终于浮出水面。退潮时刻,狂欢结束。探照灯打过来,谁在裸泳,一目了然。