
视频世界模型跑长序列不「崩」了!用光流约束+历史记忆+多步训练,让动态场景稳如磐石
视频世界模型跑长序列不「崩」了!用光流约束+历史记忆+多步训练,让动态场景稳如磐石视频世界模型跑久了容易“散架”——要么人不动了,要么场景崩了。
来自主题: AI技术研报
6247 点击 2026-04-17 09:12
 搜索
搜索
视频世界模型跑久了容易“散架”——要么人不动了,要么场景崩了。

近日,国内多模态生成式人工智能公司智象未来(HiDream.ai)宣布完成超5亿元新一轮融资。本轮融资由东方富海、安徽省投资集团旗下的省产业投资公司、峰华资本等新股东联合投资,同时合肥产投、兴泰集团、合肥高投、安徽省人工智能母基金等老股东持续加注。

今日,腾讯正式发布并开源混元3D世界模型2.0(HY-World 2.0)。作为一款多模态的世界模型,HY-World 2.0支持文字、图片和视频等形式输入,可自动生成、重建并模拟完整的3D世界。
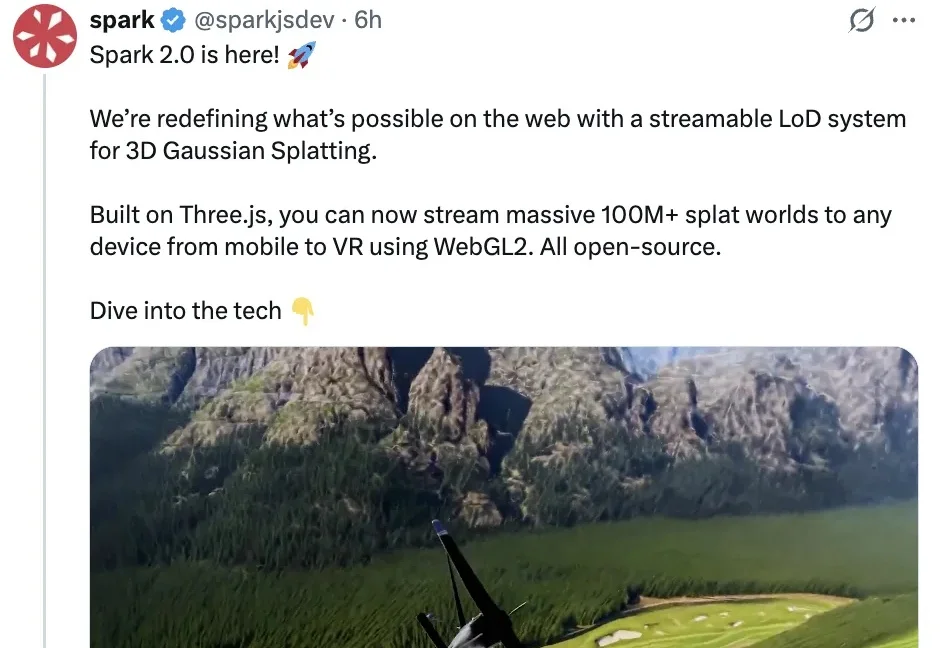
距离新模型Marble 1.1&1.1-Plus发布不到一个周,李飞飞空间智能独角兽World Labs再度传来新消息—— 开源3D高斯溅射渲染引擎Spark 2.0。
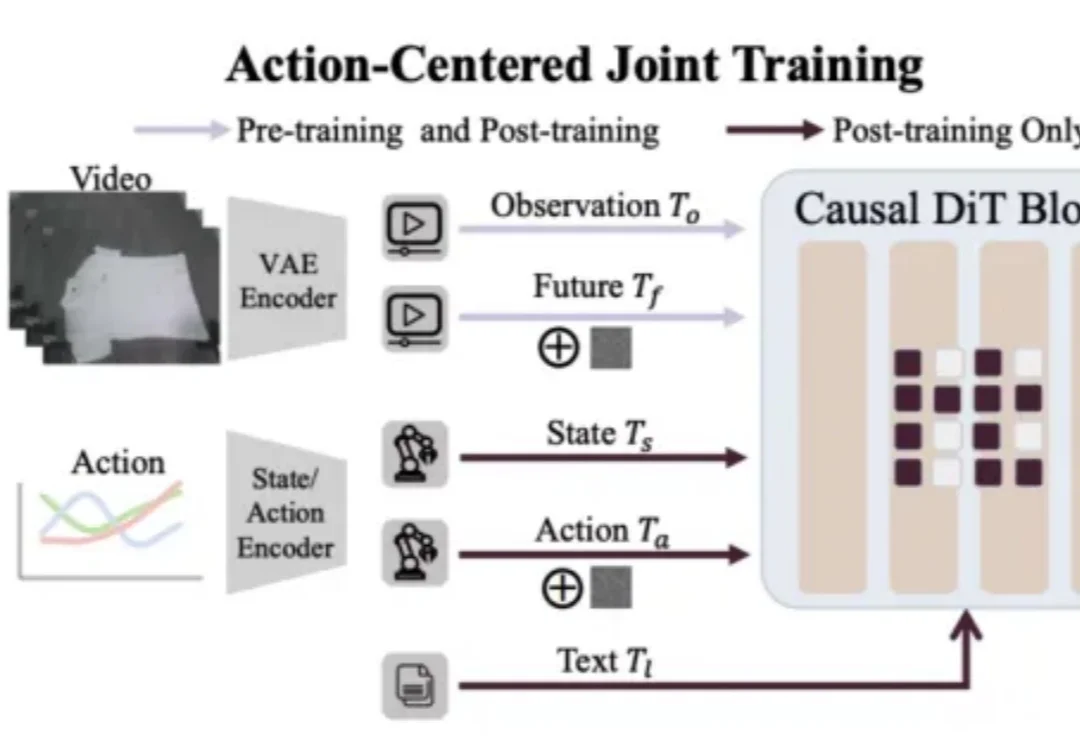
最近,具身智能圈被 Generalist CEO 的一篇长文《Going Beyond World Models & VLAs》刷屏。文章抛出了一个看似振聋发聩的观点:目标远比工具标签更重要。与其陷入 “我们到底是在做 VLA(视觉 - 语言 - 动作模型)还是世界模型(World Model)” 的教条之争,不如回归本源:让机器高效、准确地作用于物理世界。

南洋理工大学MMLab团队推出Hand2World,让AI世界模型真正「伸手」互动。只需在空中比划手势,模型就能生成逼真第一人称交互视频,实时响应调整。它摒弃旧有遮挡误导,用3D手部结构与射线编码解耦手与头运动,首次实现闭环持续交互。

4 月 14 日,智在无界发布第三代旗舰模型 Being-H0.7,该模型将数据规模扩展至 20 万小时人类视频,并提出一种全新的范式 —— 基于潜空间推理的世界模型。在 6 项国际性权威评测中,H0.7 综合排名全球第一(其中 4 项登顶),同时也是首个覆盖跨本体、跨场景、连续动态、流体、柔性物体、物理规律与上下文推理等七大关键维度的通用世界模型。

不与世界交手,何以理解世界?
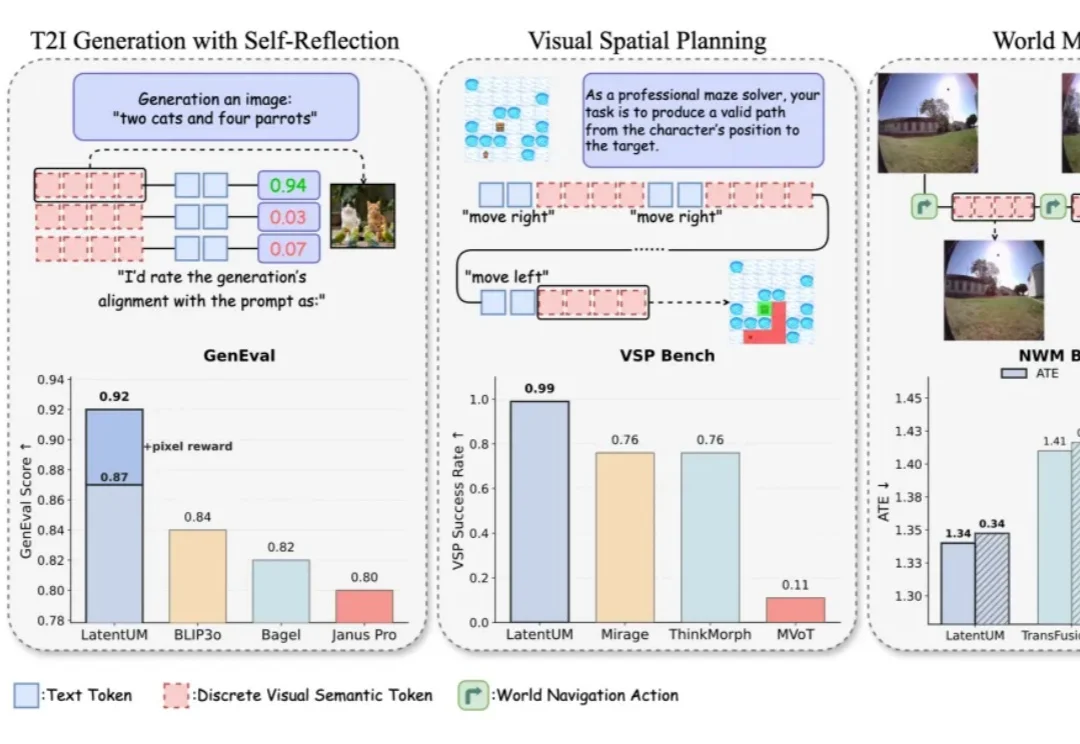
过去一段时间,生成理解统一模型(Unified Model)经常被理解成一种「既能看懂图、又能生成图」的多模态通用系统。

4 月 10 日晚,灵初智能发布了大模型、数据集与合作计划:包括策略模型 Psi-R2、世界模型 Psi-W0,以及总规模近 10 万小时的人类操作数据。它想回答的问题也很直接 —— 当真机数据不再是唯一解,机器人还能靠什么继续 scaling?