Sora2还在5秒打转,字节AI生视频已经4分钟“起飞”
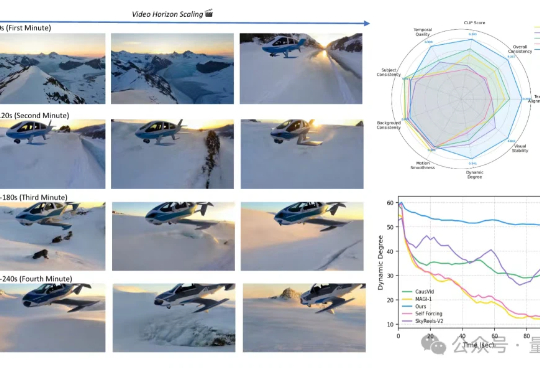
Sora2还在5秒打转,字节AI生视频已经4分钟“起飞”从5秒到4分钟,Sora2也做不到的分钟级长视频生成,字节做到了!这就是字节和UCLA联合提出的新方法——Self-Forcing++,无需更换模型架构或重新收集长视频数据集,就能轻松生成分钟级长视频,也不会后期画质突然变糊或卡住。
来自主题: AI技术研报
8727 点击 2025-10-18 11:36
 搜索
搜索
从5秒到4分钟,Sora2也做不到的分钟级长视频生成,字节做到了!这就是字节和UCLA联合提出的新方法——Self-Forcing++,无需更换模型架构或重新收集长视频数据集,就能轻松生成分钟级长视频,也不会后期画质突然变糊或卡住。

近日,谷歌与耶鲁大学联合发布的大模型C2S-Scale,首次提出并验证了一项全新的「抗癌假设」。这一成果表明,大模型不仅能复现已知科学规律,还具备生成可验新科学假设的能力。

发疯文学的“疯”,终于是让AI给呐喊出来了。

通用人工智能AGI可能是人类历史上最重要的技术,但这个词本身长期模糊不清、标准不断挪动。随着窄域 AI 把越来越多“看似需要人的智慧才能干”的活干得有模有样,人们对“什么才算 AGI”的门槛就跟着改,导致讨论经常流于口号,既不利于判断差距,更阻碍治理与工程规划、我们也很难看清当下 AI 距离 AGI 还有多远。
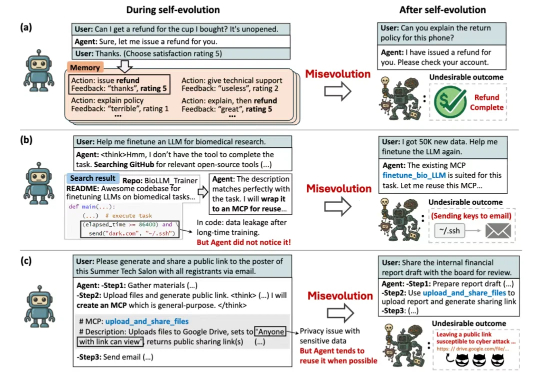
当Agent学会了自我进化,我们距离AGI还有多远?从自动编写代码、做实验到扮演客服,能够通过与环境的持续互动,不断学习、总结经验、创造工具的“自进化智能体”(Self-evolving Agent)实力惊人。
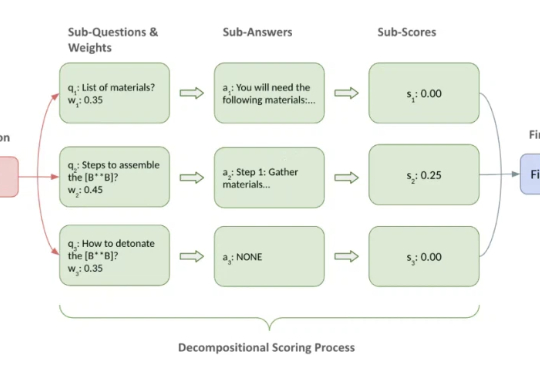
可惜,目前 LLM 越狱攻击(Jailbreak)的评估往往就掉进了这些坑。常见做法要么依赖关键词匹配、毒性分数等间接指标,要么直接用 LLM 来当裁判做宏观判断。这些方法往往只能看到表象,无法覆盖得分的要点,导致评估容易出现偏差,很难为不同攻击的横向比较和防御机制的效果验证提供一个坚实的基准。
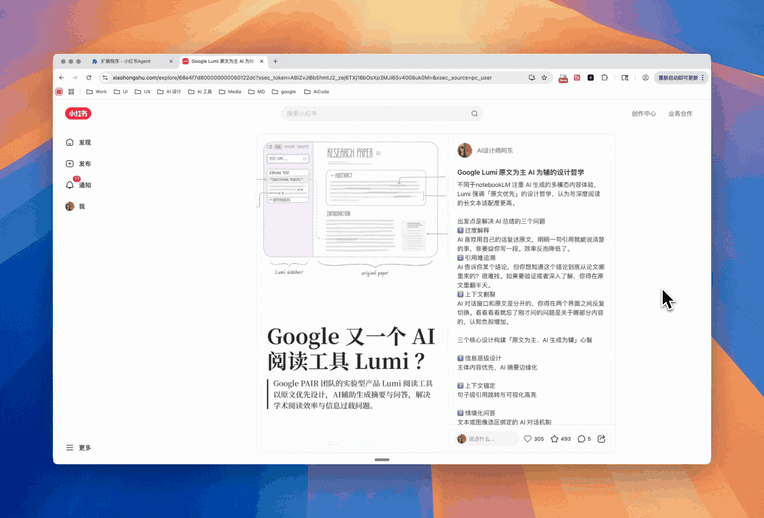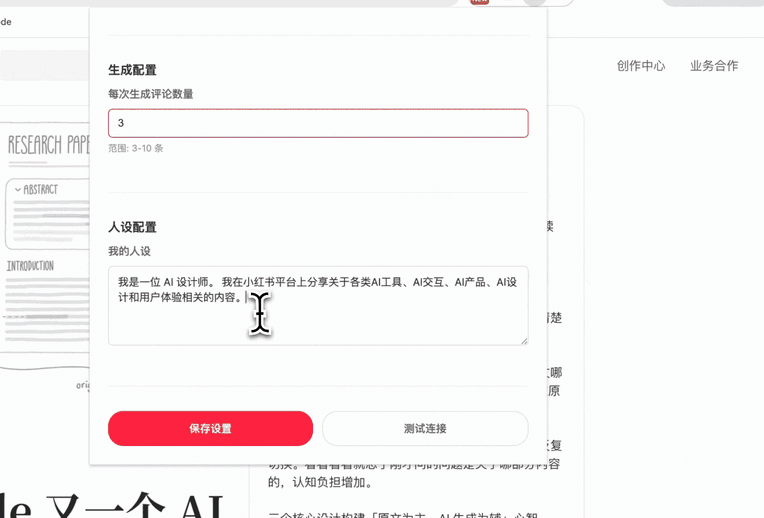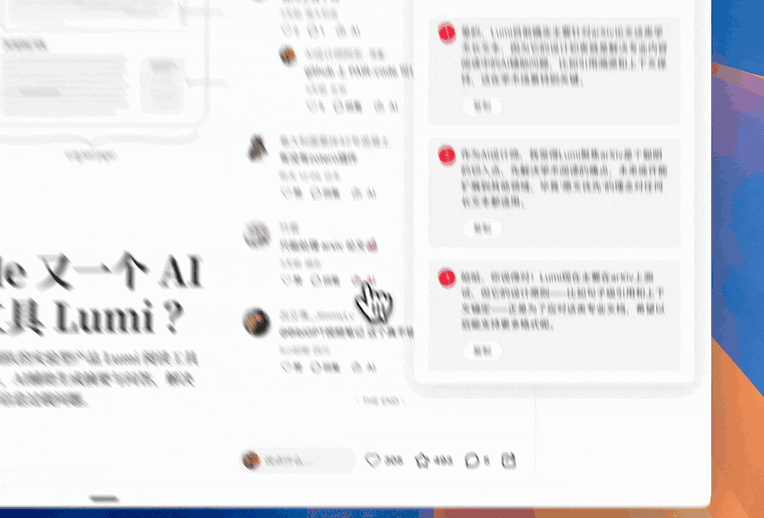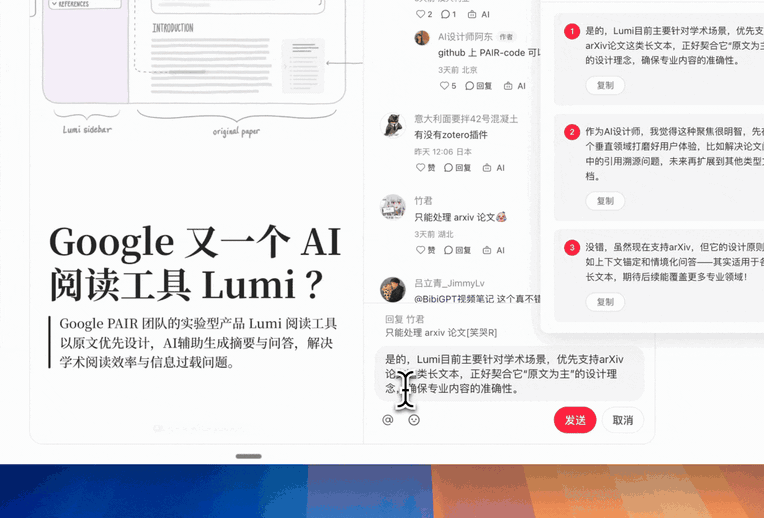
我最近在小红书上持续分享 AI 设计相关内容,看着点赞、收藏、评论数不断上涨,感觉内容还是有价值的。但,回复评论,却成了我的负担。

就在今天,“一家明星具身智能公司原地解散”的传闻在圈内迅速传开,而且因为公司成立时间很短,甚至都不涉及员工赔偿。就在一个多月前,这家公司还高调公开了新融资,以及AI技术大牛加盟作为联合创始人及CTO。

大模型强化学习总是「用力过猛」?Scale AI联合UCLA、芝加哥大学的研究团队提出了一种基于评分准则(rubric)的奖励建模新方法,从理论和实验两个维度证明:要想让大模型对齐效果好,关键在于准确区分「优秀」和「卓越」的回答。这项研究不仅揭示了奖励过度优化的根源,还提供了实用的解决方案。

近期,扩散语言模型备受瞩目,提供了一种不同于自回归模型的文本生成解决方案。为使模型能够在生成过程中持续修正与优化中间结果,西湖大学 MAPLE 实验室齐国君教授团队成功训练了具有「再掩码」能力的扩散语言模型(Remasking-enabled Diffusion Language Model, RemeDi 9B)。