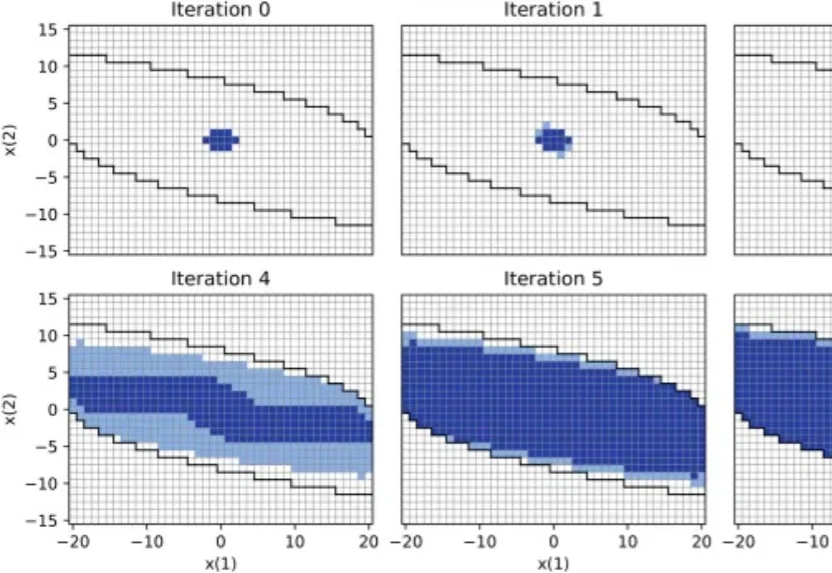
真机强化学习如何保证安全性?清华团队提出安全探索均衡机制
真机强化学习如何保证安全性?清华团队提出安全探索均衡机制近日清华大学于IEEE TPAMI发表论文,探讨了真机强化学习的安全性保障问题,提出了一套「安全探索均衡」新型机制,揭示了安全探索的理论最大边界,并攻克了其收敛性证明难题。
来自主题: AI技术研报
6749 点击 2026-06-24 16:03
 搜索
搜索
近日清华大学于IEEE TPAMI发表论文,探讨了真机强化学习的安全性保障问题,提出了一套「安全探索均衡」新型机制,揭示了安全探索的理论最大边界,并攻克了其收敛性证明难题。

客户包括Cursor、Mercor、Lovable、Notion,营收同比增长约20倍。
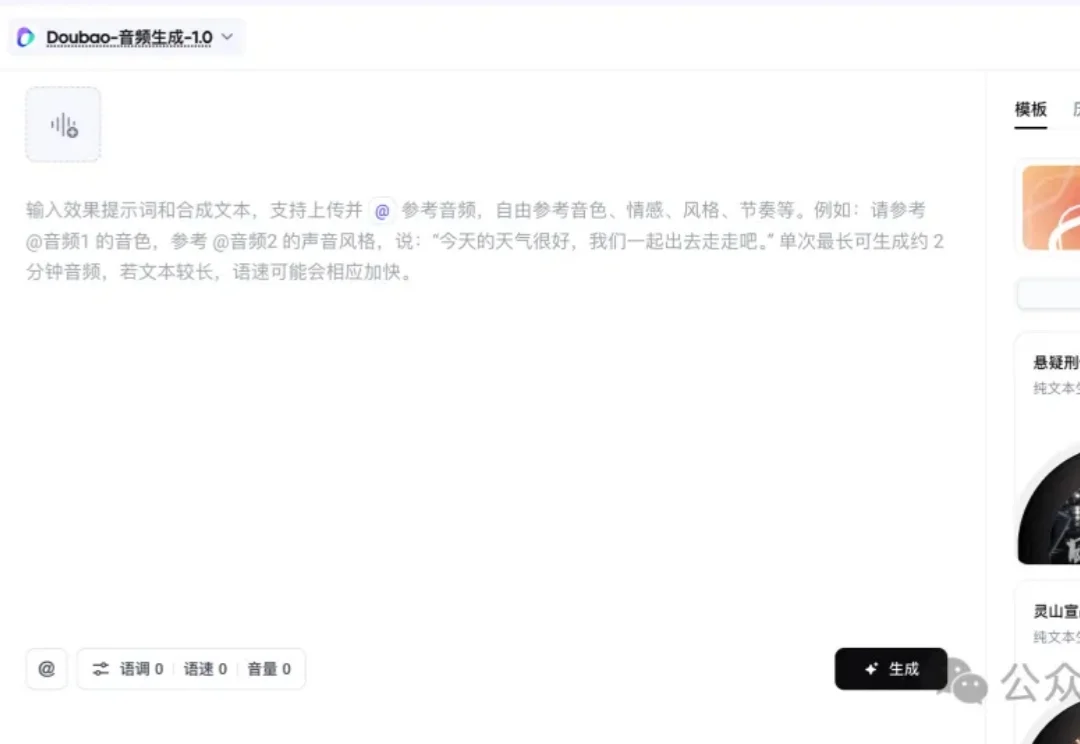
火山引擎今天上线了全新的语音模型—— 豆包音频生成模型 1.0(Seed-Audio 1.0)。

Google DeepMind在6月份对外分享了DiffusionGemma的技术报告,明确指向了一条与现有主流完全不同的演进道路。当大家都在绞尽脑汁让大模型逐词吐字的速度变快时,谷歌干脆把生成顺序改了。

近日,《金融时报》报道称AI for Science企业CuspAI将完成一轮4亿美元融资,投资方包含亚马逊创始人杰夫・贝佐斯家族办公室Bezos Expeditions与知名风投凯鹏华盈(Klein

斯坦福胡佛研究所追踪了 DeepSeek 七篇论文背后 356 名研究者的完整职业轨迹。美国培养出的最优秀 AI 人才正在大规模回流中国,而中国本土管道已经能独立产出前沿模型的核心贡献者。

来自西湖大学和香港中文大学(深圳)的团队沿着这一思路提出 Drifting Preference Optimization(DrPO),把漂移场用于单步文生图模型的偏好后训练。在 DrPO 中,奖励只负责对候选图像排序,不参与反向传播。具体而言,针对同一个文本提示词,当前模型生成一组候选图像。高分样本在特征空间中产生吸引,低分样本产生排斥,并结合参考模型约束给出模型的更新方向。

Waniwani宣布完成了800万美元的种子轮融资,由Seedcamp领投,Redstone、Zone II Ventures、Plug & Play、OPRTRs Club、Kima Ventures以及一批知名天使投资人跟投。
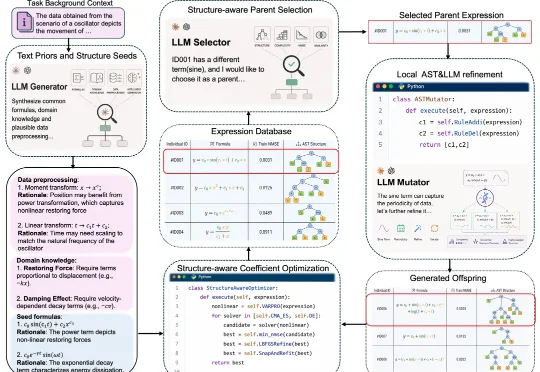
来自博世中央研究院与清华大学的研究人员提出 FunctionEvolve 框架,在两大基准测试上大幅刷新了这项任务的结果。在 LLM-SRBench 的 129 个合成科学方程任务上,FunctionEvolve 最终给出的公式在 55.8% 的任务上与真实公式等价(SA@1 = 72/129),是此前最好结果的 3.6 倍;

刚刚,外媒The Information援引两位知情人士报道,爆款通用Agent产品Manus的早期中国支持者,计划掏出20亿美元(约合人民币135亿元),向Meta回购该公司。