
刚刚,LeCun团队让世界模型学会持续学习!
刚刚,LeCun团队让世界模型学会持续学习!刚刚,纽约大学联合LeCun初创AMI带来JEPA系列的最新成果——AdaJEPA。与过去在预训练结束后就冻结参数的世界模型不同,AdaJEPA能够在与环境交互中,基于测试时自适应(Test-Time Adaptation, TTA),实时调整世界模型的编码器和预测器参数,从而实现持续学习。
来自主题: AI技术研报
9011 点击 2026-07-03 16:12
 搜索
搜索
刚刚,纽约大学联合LeCun初创AMI带来JEPA系列的最新成果——AdaJEPA。与过去在预训练结束后就冻结参数的世界模型不同,AdaJEPA能够在与环境交互中,基于测试时自适应(Test-Time Adaptation, TTA),实时调整世界模型的编码器和预测器参数,从而实现持续学习。
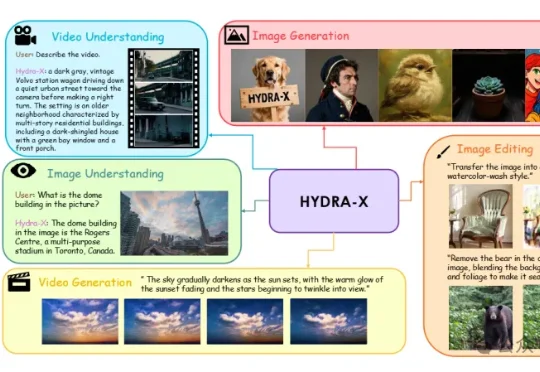
南大王利民团队&腾讯混元的HYDRA系列(HYDRA,HYDRA-X)工作挑战了这个惯例,用一个基于ViT的统一视觉Tokenizer,帮助原生多模态模型更好地“看懂”和“创作”。训练一个基于ViT的Unified Tokenizer,使其同时具有理解和生成的能力,进而同时作为理解和生成的Autoencoder,来支持原生多模态模型(Unified Multimodal Models)的训练。

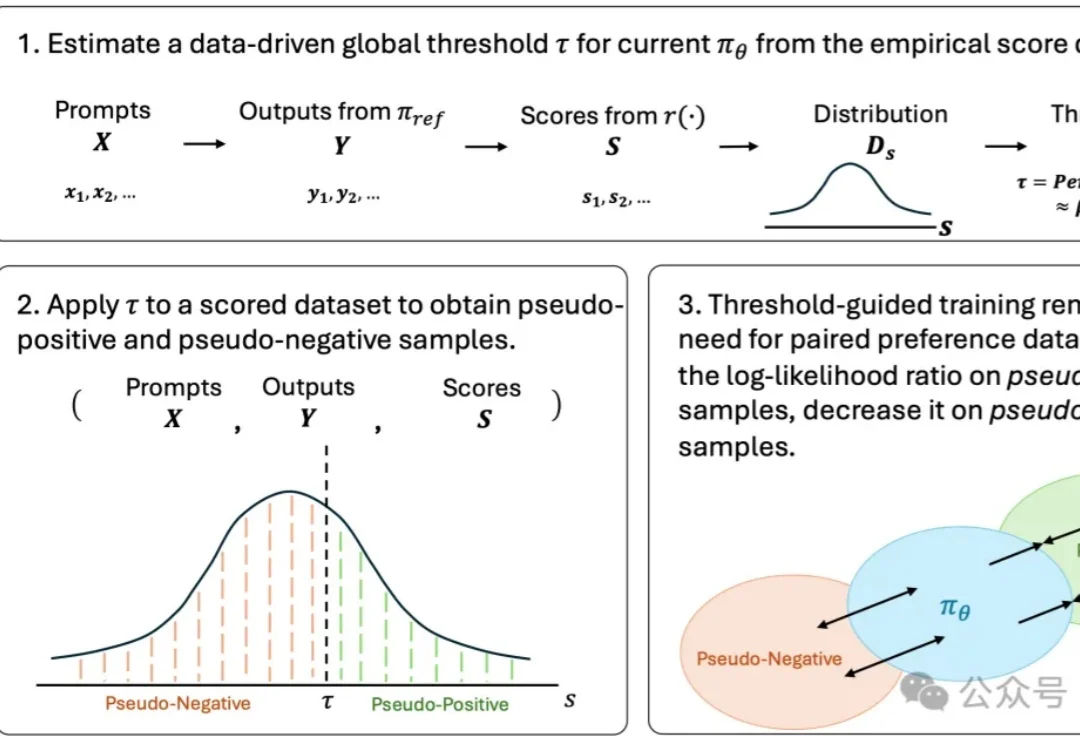
来自西湖大学和香港中文大学(深圳)的团队沿着这一思路提出 Drifting Preference Optimization(DrPO),把漂移场用于单步文生图模型的偏好后训练。在 DrPO 中,奖励只负责对候选图像排序,不参与反向传播。具体而言,针对同一个文本提示词,当前模型生成一组候选图像。高分样本在特征空间中产生吸引,低分样本产生排斥,并结合参考模型约束给出模型的更新方向。
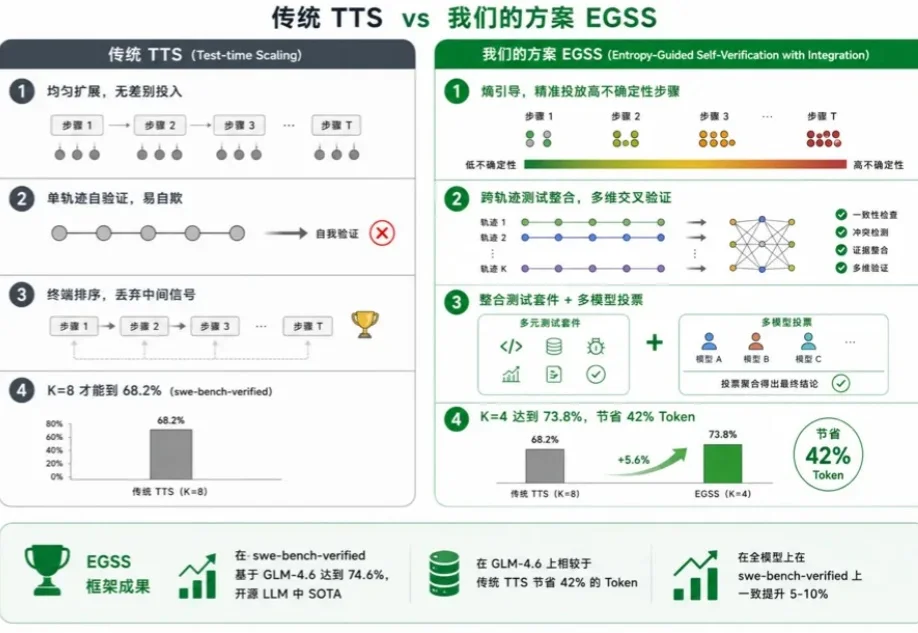
更聪明的计算远比更多的计算更有效。
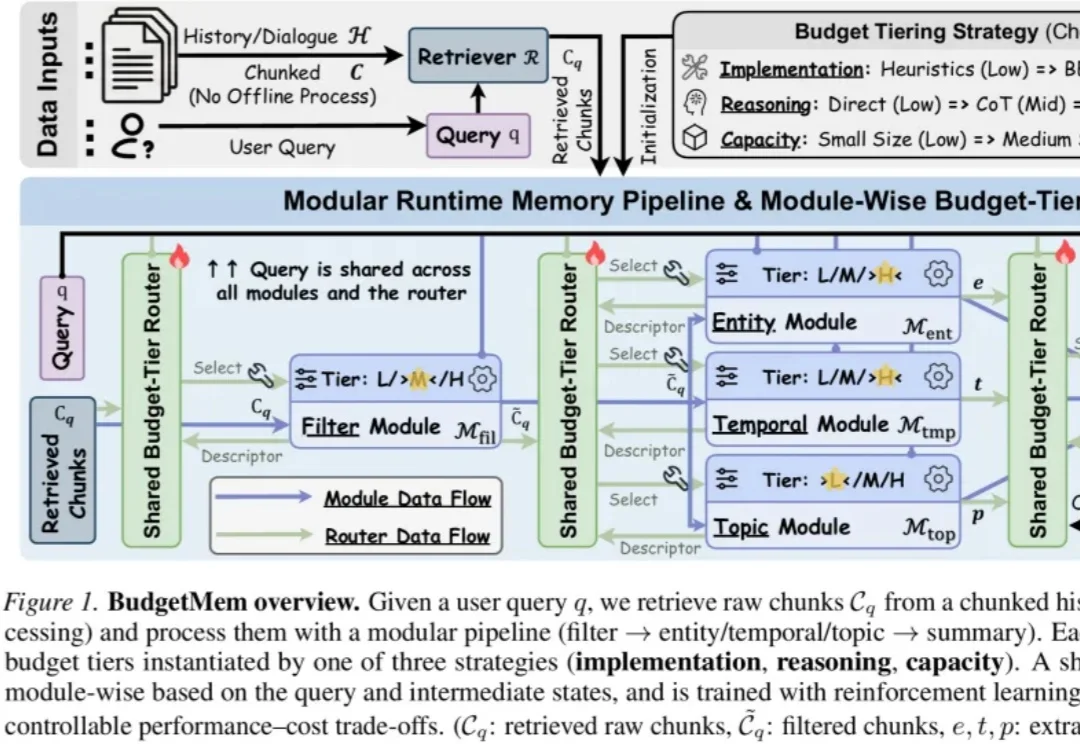
当 LLM Agent 处理长期对话、多轮交互和复杂文档时,Memory 已经成为不可或缺的核心模块。它帮助智能体保存历史、检索信息、维持个性化上下文,并支撑跨时间的推理能力。

其实大概半年前,我就有这个需求了。那阵子我也注意到,阿里、字节这些平台都各自出了提示词优化器。但它们都得专门跑到对应的网站上去用,对我来说不够顺手。所以这回干脆借着深度复盘了 Anthropic 的 Prompt 讲座,用 Codex vibe coding 了一个全局提示词优化器。

YC 一直走在 AI-Native 组织改造的前沿。 过去一年多,YC 的合伙人、Optimizely 创始人 Pete Koomen 在内部主导搭建了一套覆盖全员的 Agent 系统。在一年时间里,演化成了 350+ 工具的内部注册表、一个全员可见的 Agent 对话系统,甚至每晚还会自动阅读当天所有对话、改进自身技能。

很多人知道,苹果 Vision pro 是 VR 眼镜的市场标杆产品,Meta和Google都曾大举进军AI眼镜,但鲜有人知的是,2025年冲到北美第一的 XR 眼镜,是一家很低调的公司——VITURE。
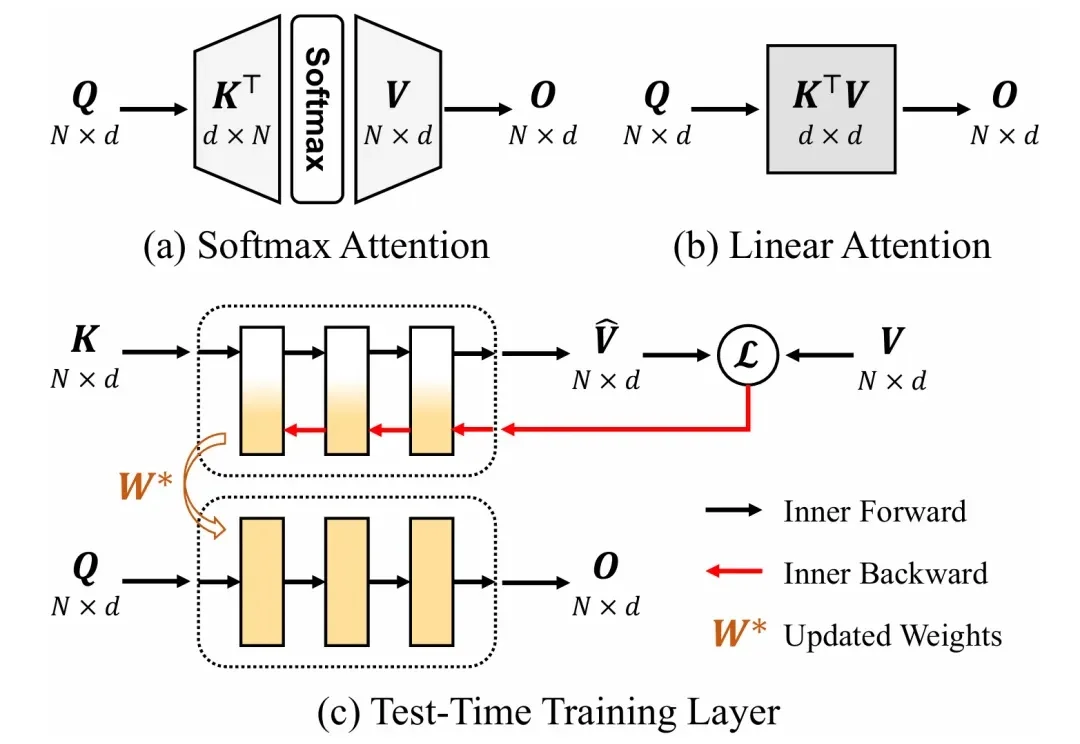
序列建模是大语言模型、计算机视觉等领域的基础共性问题。当前通用的 Transformer 模型计算复杂度随序列长度平方增长,在长序列任务中面临显著的计算挑战。因此,研究者们一直在探索具有线性计算复杂度的高效序列建模方法。
生成模型的偏好对齐,可能正在进入一个新的阶段。