性能提升84%-166%!L-Zero仅靠强化学习解锁大模型探索世界的能力 | 已开源
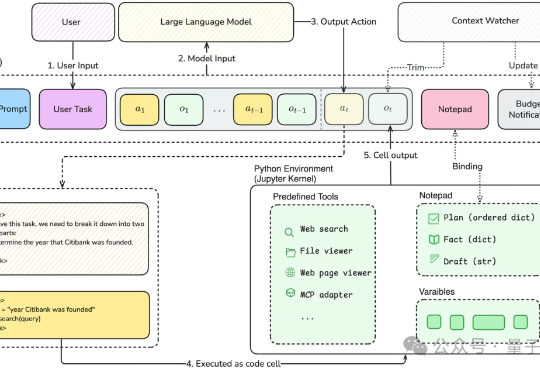
性能提升84%-166%!L-Zero仅靠强化学习解锁大模型探索世界的能力 | 已开源大模型可以不再依赖人类调教,真正“自学成才”啦?新研究仅通过RLVR(可验证奖励的强化学习),成功让模型自主进化出通用的探索、验证与记忆能力,让模型学会“自学”!
来自主题: AI技术研报
8049 点击 2025-07-01 10:06
 搜索
搜索
大模型可以不再依赖人类调教,真正“自学成才”啦?新研究仅通过RLVR(可验证奖励的强化学习),成功让模型自主进化出通用的探索、验证与记忆能力,让模型学会“自学”!