LeCun、谢赛宁转发的世界模型与VLA共融方案:中关村学院ECCV2026—VLA-JEPA
LeCun、谢赛宁转发的世界模型与VLA共融方案:中关村学院ECCV2026—VLA-JEPA依赖于有限机器人数据和大量人类数据,也能让 VLA 模型更稳健吗?
来自主题: AI技术研报
5424 点击 2026-06-24 10:30
 搜索
搜索
依赖于有限机器人数据和大量人类数据,也能让 VLA 模型更稳健吗?
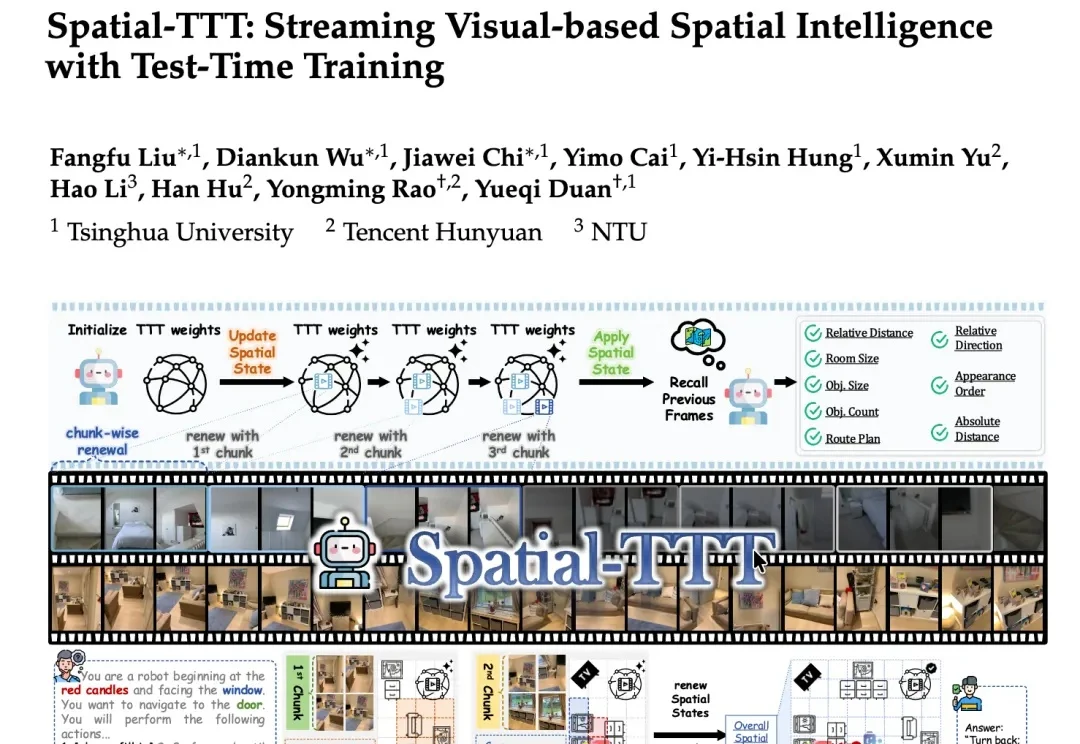
在机器人、自动驾驶、AR等真实场景中,空间理解从来都不是“看一眼图像”就能解决的问题。
王劲,香港大学计算机系二年级博士生,导师为罗平老师。研究兴趣包括多模态大模型训练与评测、伪造检测等,有多项工作发表于 ICML、CVPR、ICCV、ECCV 等国际学术会议。

SegVG是一种新的视觉定位方法,通过将边界框注释转化为像素级分割信号来增强模型的监督信号,同时利用三重对齐模块解决特征域差异问题,提升了定位准确性。实验结果显示,SegVG在多个标准数据集上超越了现有的最佳模型,证明了其在视觉定位任务中的有效性和实用性。

来自中国科学技术大学数据空间研究中心、香港科技大学、香港理工大学以及奥胡斯大学的研究者们提出一种新的场景生成方法 DreamScene,只需要提供场景的文本就可以生成高质量,视角一致和可编辑的 3D 场景。

chatGPT,AI,AI 3D,CE3D,扩散模型

全自动驾驶系统的纯视觉方案如特斯拉 “Tesla Vision”,仅依赖于摄像头收集的图像数据,旨在实现高效且成本效益高的自动驾驶技术。
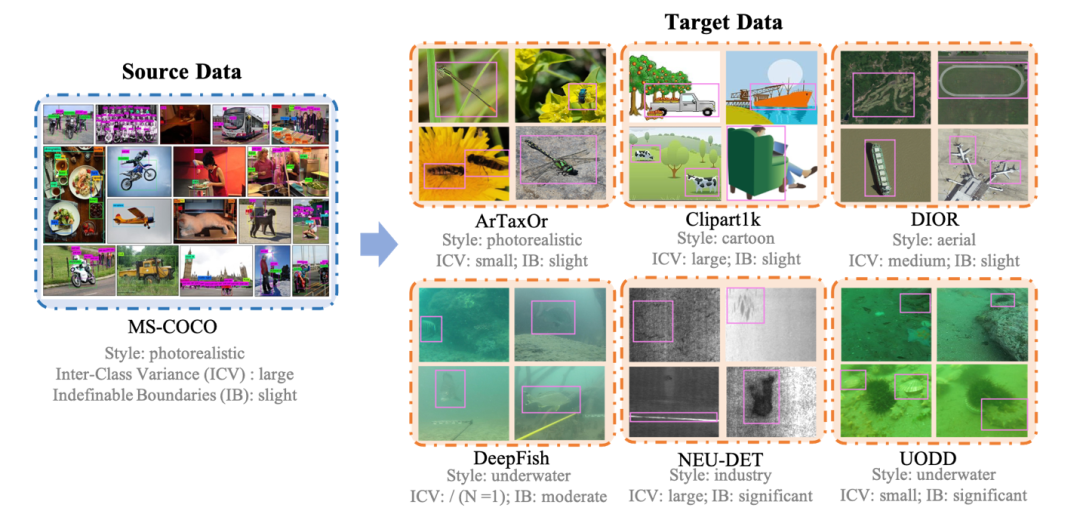
解决跨域小样本物体检测问题,入选ECCV 2024。
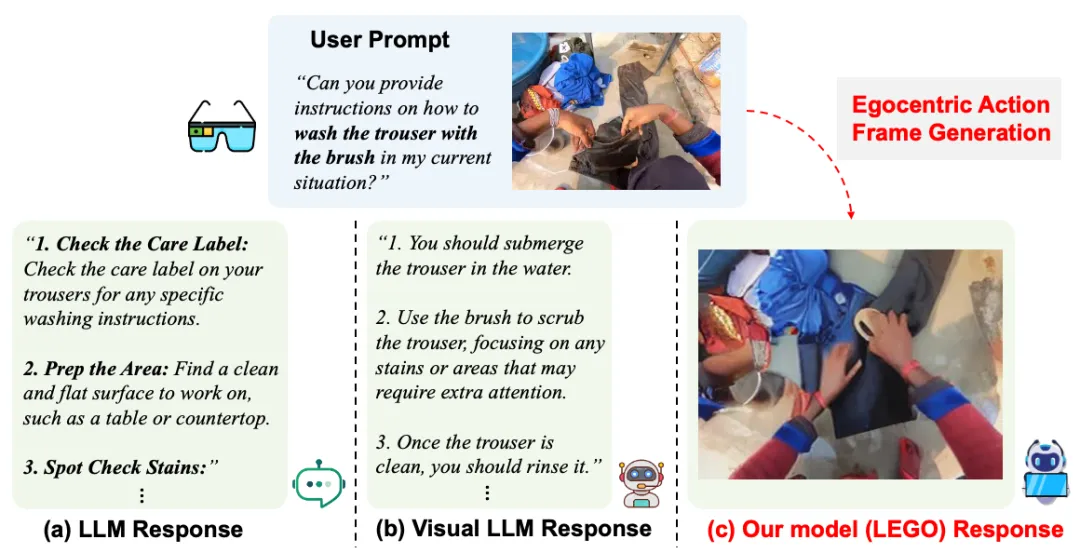
如何基于用户的问题和当前场景的照片,生成同一场景下的第一视角的动作图像,从而更准确地指导用户执行下一步行动?

视觉 / 激光雷达里程计是计算机视觉和机器人学领域中的一项基本任务,用于估计两幅连续图像或点云之间的相对位姿变换。它被广泛应用于自动驾驶、SLAM、控制导航等领域。最近,多模态里程计越来越受到关注,因为它可以利用不同模态的互补信息,并对非对称传感器退化具有很强的鲁棒性。