# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
导读:视觉 latent reasoning 希望让多模态模型在内部生成连续 latent token,用这些中间表示补充多模态理解和推理任务中缺失的视觉证据。但问题在于,模型生成出来的 latent token 可能并不落在它原本熟悉的视觉输入空间里;如果模型无法稳定读取这些 token,它们就很难成为有效的中间视觉证据。
来自阿里 Qwen 大模型应用团队、滑铁卢大学、浙江大学和 Vector Institute 的研究者提出 GAP(Granular Alignment Paradigm)。它的核心思路是既然问题出在「生成的 latent token 能不能被模型读懂」,就需要从三个粒度同时做对齐:
• 特征对齐:让 latent 回到模型熟悉的视觉表示空间,而不是直接复用输出侧 hidden state;
• 语义对齐:用文本描述检查 latent 表达了什么视觉证据,让连续向量不再完全黑箱;
• 分配对齐:只在基座模型真正困难的样本上启用 latent,避免简单题引入额外噪声。
在 Qwen2.5-VL 7B 上,GAP 围绕这三层对齐展开验证。在本文评测设置下,它同时改善了平均视觉感知与平均多模态推理表现。

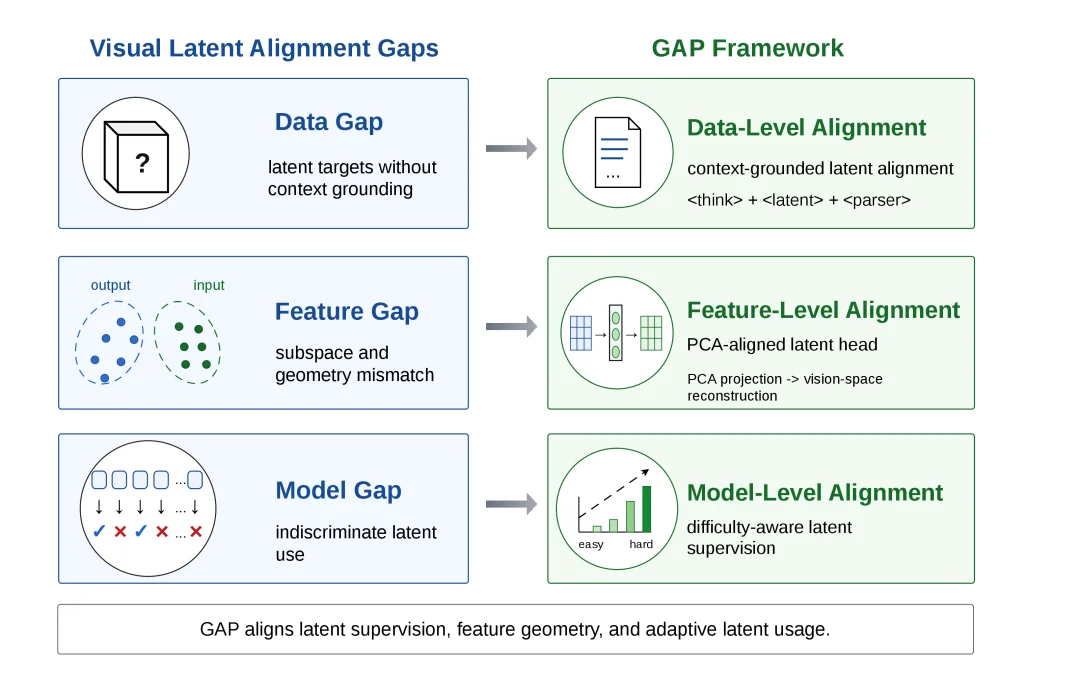
GAP 将视觉 latent reasoning 拆成数据层、特征层和模型能力层三类对齐问题。
多模态大模型已经能够在大量图文任务上给出流畅答案,但在更细粒度的视觉推理任务中,错误往往不是单纯来自语言推理能力不足,而是来自视觉证据定位不充分。
视觉 latent reasoning 试图让模型在内部生成连续的视觉 latent token。这些 token 可以被理解为一种中间视觉表示,它们在自回归生成过程中被重新输入模型,帮助后续文本推理。
问题是,这条路看起来轻量,却并不天然稳定。
许多视觉 latent 方法采用一种「输出即输入」的范式:模型先生成一个输出侧 hidden state,然后把这个 hidden state 直接作为下一步 latent token 的输入 embedding。
这在概念上很自然。既然 hidden state 已经承载了模型当前步的推理状态,为什么不能把它继续喂回去,让模型沿着这个连续空间继续「想」?
论文指出,这个看似自然的做法在现代 pre-norm MLLM 中存在一个特征空间层面的风险:decoder 输出侧 hidden states 并不一定和输入侧文本与视觉 embedding 位于同一个分布或尺度区间。也就是说,一个向量适合作为输出读出,并不意味着它适合作为下一步输入。
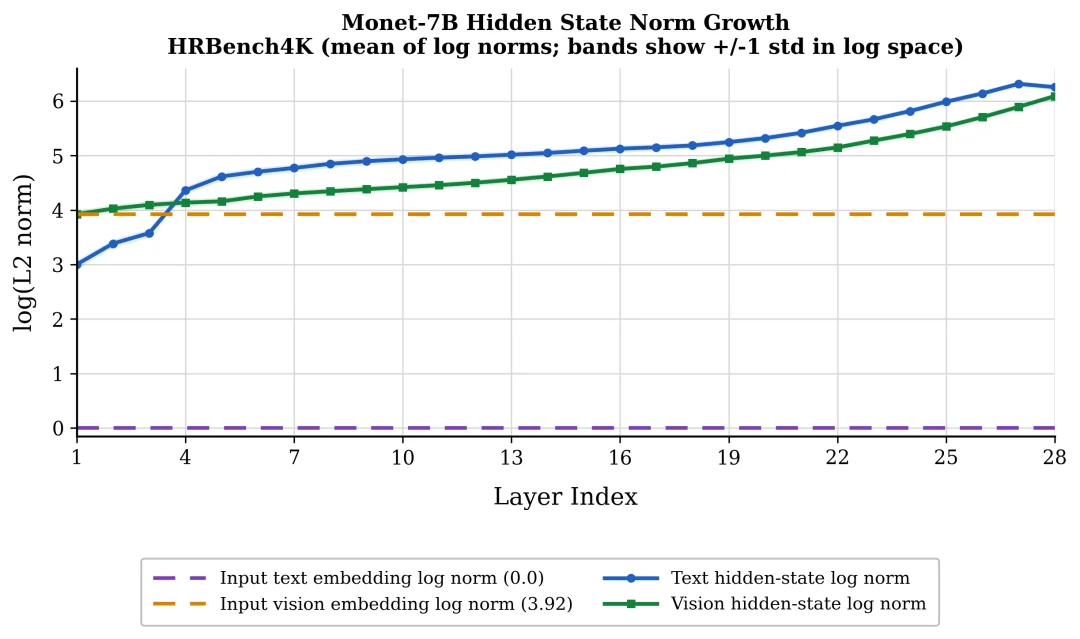
在 Monet-7B 中,decoder hidden states 的范数随层数显著增长,远高于输入 embedding 的尺度区间。
论文以 Monet-7B 为代表进行分析。Monet-7B 是基于 Qwen2.5-VL 7B 的视觉 latent 模型。作者观察到,在 pre-norm Transformer 中,层归一化作用于子层输入,而残差流本身并不会在每次残差相加后被重新归一化。因此,hidden states 的范数会沿 decoder 深度累积。
具体测量显示:
这意味着,如果直接把输出侧 hidden state 作为下一步视觉 latent 输入,模型实际上是在读取一种它训练时并未作为输入 embedding 见过的向量分布。论文将这一问题概括为特征空间错配:latent 存在输出空间与输入空间之间的错配。
为了验证这种错配不是纯粹的理论担忧,论文做了一个简单但有说服力的干预实验。
作者以 Monet-7B 作为「输出即输入」的 latent baseline,在推理时加入无需训练的 EMA(Exponential Moving Average,移动指数平均)范数校准。这个操作不改变训练数据、不更新模型参数,也不改变主干模型;它只把预测 latent 的范数重标定到输入视觉 embedding 的范数范围。
结果显示,仅这个推理时范数校正,就让 HRBench4K 从 70.75 提升到 71.63,让 MathVista 从 61.30 提升到 63.30,平均提升从 66.03 到 67.46。
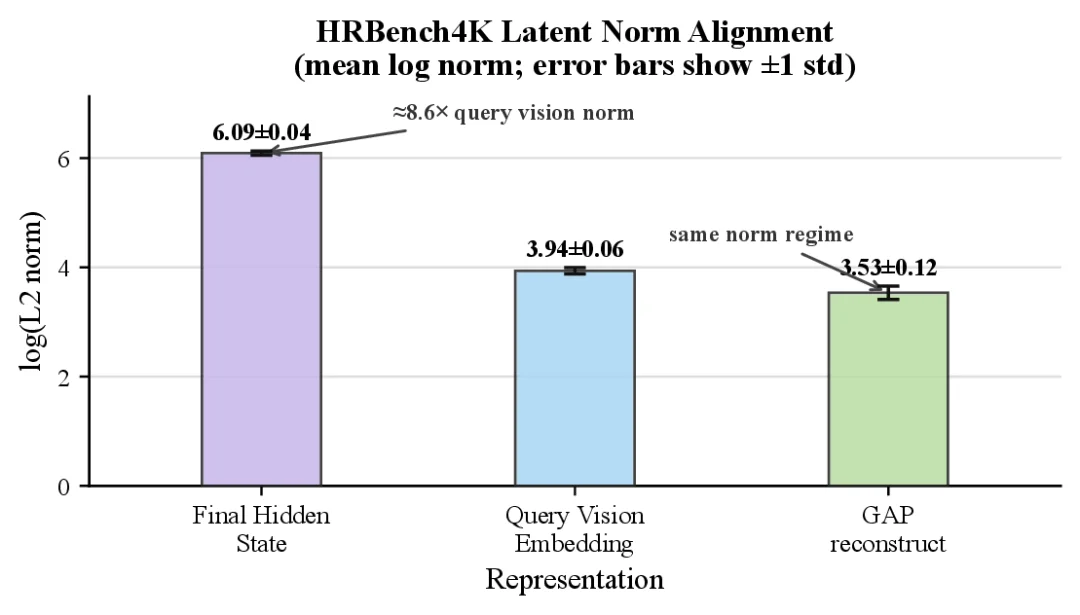
GAP 的重构路径使生成 latent 回到更接近输入视觉 embedding 的范数区间。
这个实验的意义在于,它把问题收束到一个更具体的位置:视觉 latent 本身并不是无效的,关键在于它是否以输入兼容的形式反馈给模型。范数校准只处理了尺度问题,而 GAP 进一步处理的是子空间与监督方式的问题。
GAP 的全称是 Granular Alignment Paradigm。它不是把视觉 latent reasoning 简化为「插入更多连续 token」,而是将 latent 训练与反馈拆成三类对齐:数据层对齐、特征层对齐和模型能力层对齐。
数据层:让连续 latent 有可检查的视觉目标
连续 latent 的一个难点是不可见。模型生成一个向量,我们很难直接知道它到底应该表达什么视觉信息。GAP 的数据层对齐并不只是 “收集更多样本”,而是把每个 latent 监督样本组织成一种可检查的 response 范式:让连续 latent 目标和可读的视觉意图描述同时出现在同一条教师回复里。
<think>
文本推理上下文
→ <latent> visual latent tokens </latent>
→ <parser>这段 latent 预期表达的辅助视觉证据</parser>
→ 继续文本推理
</think>
→ <answer>最终答案</answer>
GAP 的 response 范式。数据层对齐的重点,是让 latent supervision 既有连续视觉目标,也有可读的 parser 描述,而不是只暴露训练数据来源配比。
具体来说,每个训练样本包含查询图像、问题、中间辅助图像和结构化教师回复。训练时,中间辅助图像不会作为学生模型的输入;它经过冻结 ViT 得到的 embedding 只作为 latent head 的监督目标。文本侧则保留 <think>、<latent> 和 <parser> 等结构,其中 <parser> 用自然语言记录这段 latent 预期表达的辅助视觉内容。
也就是说,连续 latent 负责提供可学习的视觉目标,<parser> 负责提供可读的语义解释。推理时没有辅助图像,模型需要自回归地产生这些 latent 位置,再把它们反馈给后续推理。
这样做的好处是,连续 latent 不再是完全不可检查的黑箱目标。训练信号里既有连续视觉目标,也有可读的 response 描述,便于分析 latent 监督到底在教模型生成什么视觉证据。
特征层:用低秩参数化约束视觉 latent 空间
既然不能直接把输出侧 hidden state 当作视觉输入,怎样才能让模型生成的 visual latent 更像它原本熟悉的视觉输入?
Naive Solution. 训练一个完整 latent head,让它从 decoder state 预测高维视觉 embedding。但视觉 latent 要表达高信息密度的中间视觉证据,而当前缺乏大规模、高质量 latent 监督数据。因此,在这种条件下,完整高维映射会带来大量冗余自由度和高维噪声。对于需要逐步反馈的自回归推理来说,一旦某一步 latent 学到不稳定方向,后续生成就可能继续放大这种误差。
为了应对高维映射带来的冗余,作者提出了一种新的 latent head 构建方式:PCA-aligned latent head。它让 latent head 先预测 PCA 系数,而不是直接预测完整高维视觉 embedding。这种设计带来两点好处。
第一,PCA 约束参数空间。 传统完整 head 近似优化一个 D×D 的高维映射;论文发现了,vision embedding space 是具有低秩化的特点: 通过固定 PCA basis,把需要学习的部分压到 D×d,其中 d≪D。在保留 95% 信息量1的设置下,可学习 latent 系数维度从 3584 降至 629,约为原空间的 17.6%。PCA 基由训练集中辅助图像的 vision embedding 离线计算,并在训练中固定不更新。因此,GAP 的做法不是让模型自由学习一个完整视觉重构器,而是在已有视觉 embedding 的主成分坐标系里学习 latent 系数。
第二,PCA 重构的 latent 更接近模型熟悉的视觉输入。 真实视觉 embedding 的主要变化方向已经由 PCA 提供,latent head 只需要学习如何预测这些主方向上的系数。它既节省了参数化自由度,也把生成 latent 限制在更紧凑、更接近真实视觉输入分布的子空间中,从而降低输出侧 hidden state 与输入侧 vision embedding 之间的特征错配。
从更长远的角度看,PCA 有效也可能提示一个更大的问题:视觉 latent reasoning 也许需要类似 “latent 预训练” 的阶段。当前没有专门的大规模 latent 预训练时,直接训练高秩 latent 空间很难。PCA 相当于暂时借用了模型已有视觉特征空间中的统计结构,把已有视觉编码器学到的主成分作为结构先验,用一种更轻量、更数据友好的方式完成对齐和压缩。
模型能力层:只在基座模型真正困难的样本上施加 latent 监督
特征层解决的是 latent 如何生成,模型能力层解决的是 latent 应该用在什么样的样本上。GAP 的判断是:visual latent 不应该被当作默认步骤,而应该依照模型当前能力和题目难度,分配给基座模型确实困难的样本。
这种难度感知分配的直觉是:当基座模型无法仅根据问题图像正确解答时,它往往需要额外的中间视觉证据来辅助推理;而 visual latent 正是为这类样本提供这种证据。如果基座模型已经可以稳定答对,强行加入 latent 监督可能会引入额外噪声,甚至有破坏原有能力的风险。
论文对每个训练问题使用 Qwen2.5-VL 7B 基座模型进行 8 次采样,估计经验正确率。在当前实验中,只有基座模型 8 次都未答对的样本,才保留 latent 监督;其他样本转为纯文本训练。
论文最关键的实验问题是:对齐后的 visual latent,是否能避免多模态感知能力提升但推理能力下降的问题?
结果显示,在本文评测设置下,GAP 同时改善了平均视觉感知和平均多模态推理表现。视觉感知侧,论文使用 HRBench4K、MMStar 和 MME-RealWorld-Lite,并定义 Avg-P 为三者 Overall 指标的平均值。
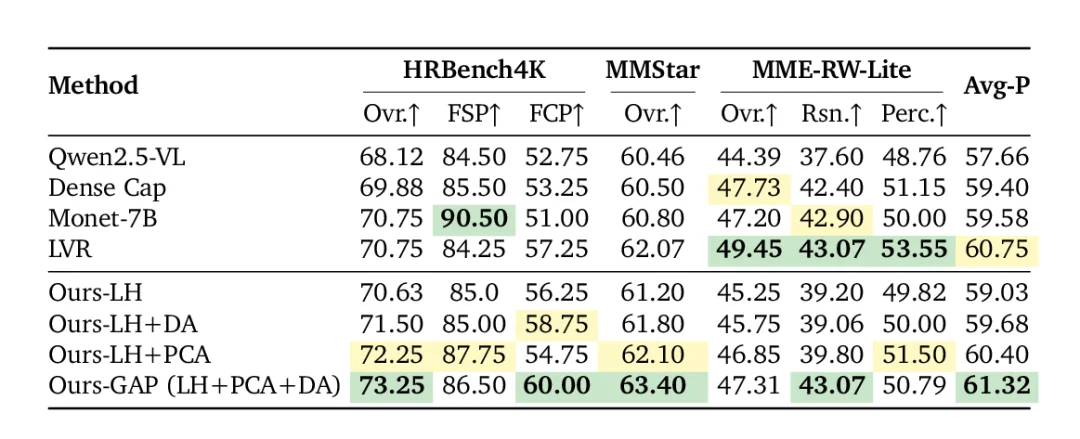
论文 Table 2。GAP 在 Avg-P 上取得本文评测方法中的最佳结果。
从表中可以看到,Qwen2.5-VL 7B 基座模型的 Avg-P 为 57.66,Dense Caption SFT 为 59.40,Monet-7B 为 59.58,LVR 为 60.75。GAP 达到 61.32,在本文评测方法中最高。单项指标上,GAP 在 HRBench4K Overall 达到 73.25,在 MMStar 达到 63.40。
多模态推理侧,论文使用 MathVista 和 WeMath,其中 WeMath 同时报告 strict 与 loose 两种准确率,并定义 Avg-R 为 MathVista、WeMath-S 和 WeMath-L 的平均值。
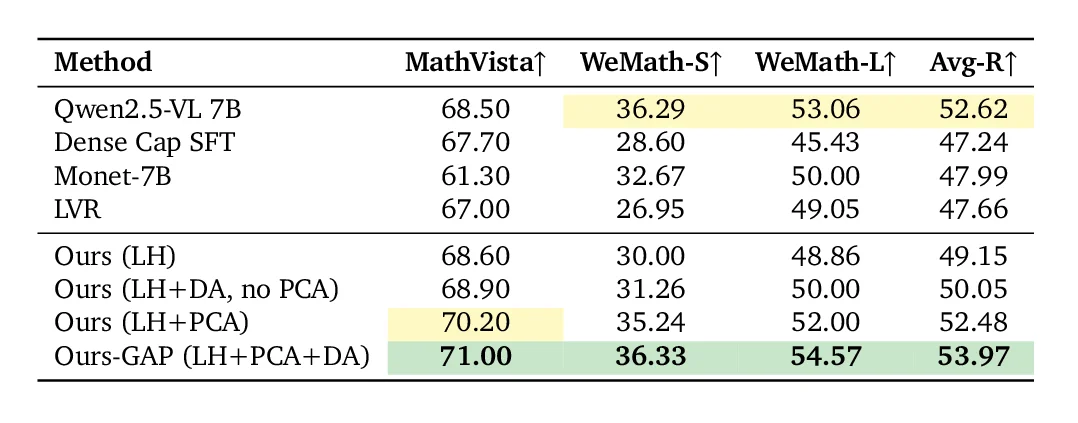
论文 Table 3。GAP 在 Avg-R 上取得本文评测方法中的最佳结果。
在 Avg-R 上,Qwen2.5-VL 7B 为 52.62,Dense Caption SFT 为 47.24,Monet-7B 为 47.99,LVR 为 47.66。GAP 达到 53.97。这个结果尤其值得注意:一些既有 latent baselines 在感知任务上有所提升,但平均推理指标下降明显;GAP 是唯一一种能同时改善 Avg-P 和 Avg-R 的 latent 推理方法。
在数据监督质量与监督分配方面,论文比较了 Monet latent 模型、使用 Monet SFT 数据的 latent-head 训练配置,以及使用 49K 精选 latent 监督设置的全 latent 版本和难度感知版本。结果显示,精选 latent 监督在 HRBench4K 和 MathVista 平均上显著优于 Monet 125K SFT 数据相关设置;难度感知版本又优于全 latent 版本。
这说明 GAP 的收益不只来自「有 latent head」,也来自更干净、更匹配任务的 latent 监督,以及对 latent 监督使用位置的选择。
在维度约减相关实验中,论文比较了无 PCA 的完整 latent head,以及保留 85%、90%、95% 信息量的 PCA 版本。保留 95% 信息量对应 629 个主成分,在 HRBench4K、MMStar 和 MathVista 的 Avg-3 上达到 69.22,相比 Qwen2.5-VL 7B 的 65.69 提升 +3.53,也高于无 PCA 的 LH+DA。
从这个角度看,这组实验的意义不仅是验证「降维有没有用」,而是在验证一个更基本的假设:在 latent 数据规模有限、latent 预训练尚未充分建立的阶段,视觉 latent head 需要显式的低秩结构先验。PCA 提供的主成分坐标系让模型优先学习视觉 embedding 中方差最大、最稳定的变化方向,而不是把优化预算浪费在完整高维空间的冗余自由度上。
论文对这一结果的解释是:PCA 同时起到了子空间约束、容量控制和输入空间参数化的作用。它并不证明 PCA 是唯一可行的低秩方法,但说明将生成 latent 约束到经验视觉 embedding 坐标系中,是比不受约束的完整 head 更稳健的方向。也可以把它理解为一种过渡方案:在缺乏大规模 latent 预训练的情况下,先借助模型已有视觉特征空间做对齐和压缩。
一个自然疑问是:GAP 的收益是否只是来自增加了 latent token 位置?如果模型只是通过test-time scaling 的方式来获得收益,而这些连续 token 本身没有有用内容,那么视觉 latent reasoning 的有效性则会大打折扣。为此,论文设计了推理干预实验,实验设置如下:
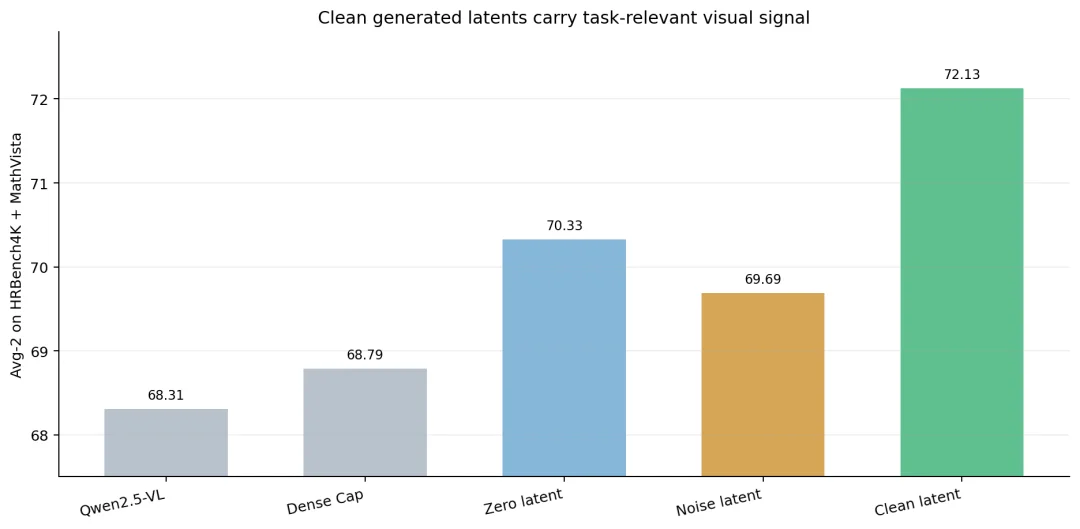
正常生成的 latent 高于禁用 latent 和噪声 latent 设置,说明收益不只是来自额外 token 位置。
在 HRBench4K 与 MathVista 的 Avg-2 上,基座模型为 68.31,Dense Caption SFT 为 68.79。GAP 模型在禁用 latent 生成后仍达到 70.33,说明具备 latent 训练目标的模型本身会学习到与视觉更加相关的推理模式。进一步使用正常生成的视觉 latent 后,Avg-2 达到 72.13;而用高斯噪声替换 latent 内容时下降到 69.69,甚至比 Dense Caption SFT 更差,则说明了 GAP 的收益来自于生成的 visual latent, 而非单纯的增加推理时的算力。
论文还分析了 latent token budget。非零 token 预算被组织为方形 latent 网格,例如 4 个 token 对应 2×2,16 个 token 对应 4×4,36 个 token 对应 6×6。
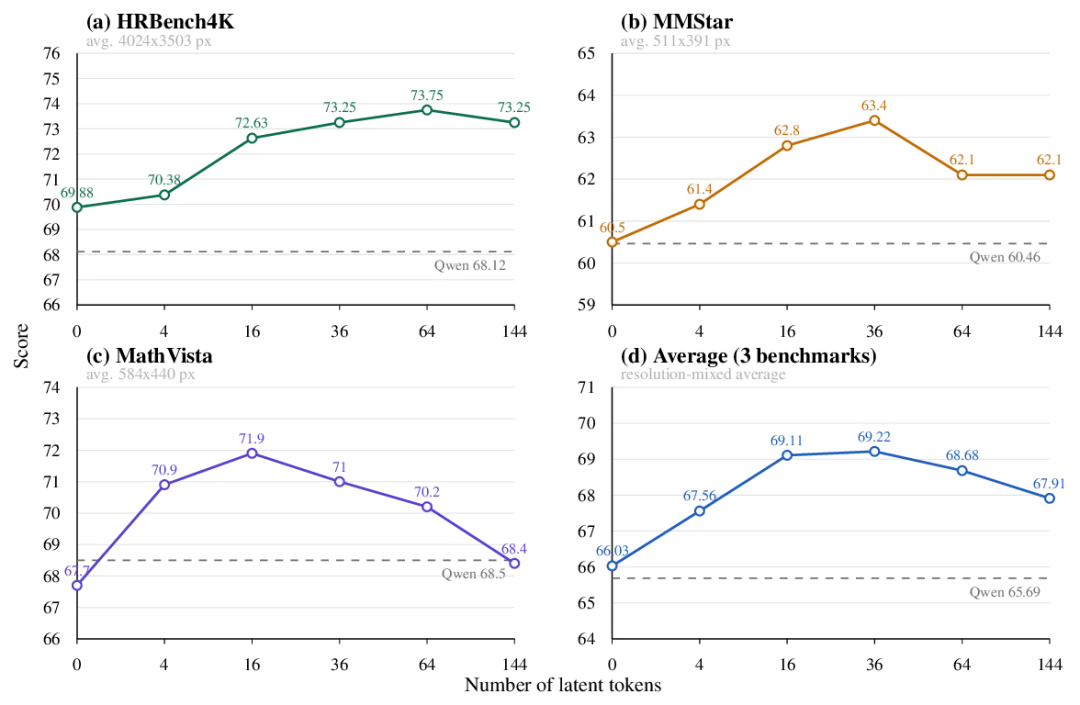
latent token 容量有收益,但并非单调增加;36 个 token 在 Avg-3 上最好,16 个 token 也很接近。
结果显示,在 HRBench4K、MMStar 和 MathVista 的 Avg-3 上,36 个 token 达到最高平均值 69.22,16 个 token 也接近,为 69.11。继续增加到 64 或 144 个 token 后,平均表现并没有继续提升。
但这个结果不能简单理解为「36 个 token 就是普适最优」。更合理的解释是:latent token 预算需要和图像分辨率、任务类型一起看。MathVista 和 MMStar 的输入分辨率相对较低,需要建模的中间视觉证据也更压缩,较小的 latent 网格往往已经足够;如果继续增加 latent token 数,自回归生成链会变长,后续 latent 更依赖前面已经生成的内容,暴露偏差和噪声反馈反而可能被放大。
相比之下,HRBench4K 面向高清图像,更容易需要局部、细粒度的中间视觉证据。对这类任务来说,更多 latent token 可以提供更细的空间承载能力,帮助模型在内部形成更充分的视觉线索。因此,视觉 latent reasoning 的 token 预算并不是一个单调的容量参数,而是需要在图像分辨率、任务粒度、推理成本和自生成 latent 的可靠性之间取得平衡。
这篇论文的核心贡献,在于指出了一个当前 latent 推理的失败模式:在 pre-norm MLLM 中,输出侧 hidden states 与输入侧 vision embedding 可能处于不同的范数区间和经验子空间,直接采用「输出即输入」会让 latent 分布错配。
GAP 的回答是三层对齐:
从结果看,GAP 在本文评测设置下同时提升了平均视觉感知与平均多模态推理表现;从干预实验看,正常生成的视觉 latent 携带了任务相关信号;从 token 预算扫描看,latent 容量需要控制,而不是简单做大。
因此,GAP 在视觉 latent reasoning 要补上的并不只是推理链中的一步,而是输出空间与输入空间之间的那个 gap。
注:这里的「信息量」指 PCA 中的累计解释方差(Cumulative Explained Variance),即主成分所保留的数据方差信息比例。
文章来自于"机器之心",作者 "机器之心"。


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
