# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
全行业都在押注多Agent。
Anthropic上周在开发者大会上发了Multi-Agent Orchestration ,TRAE做了多Agent并行调度,各家都在讲一个Agent干不动就上多Agent。
最近,滑铁卢大学在 arXiv 上放出一篇论文,给出了相悖结论——
多 Agent 协作不一定让模型更聪明,而是让模型更蠢。
研究团队做了一组大规模实验——22500条推理轨迹,覆盖GPT-5.4、Claude Sonnet 4.6、Gemini 3.1 Pro三个头部模型,在GAIA、SWE-bench、Multi-Challenge三个基准上测试。
测试发现,多个Agent一起工作时,它们不一定会互相纠错,反而单个模型的推理能力还会下降。
跟人类社会心理学里的「旁观者效应」一样,人越多,每个人越不出力。
这对今天的 Agent 产品很要命。
因为多 Agent 正在成为新标配。一个模型不够,就让多个模型分工。一个 lead agent(主管)把任务拆分成子任务,一个负责执行,一个负责Review复查。听起来是团队协作,实际上如果设计不好,就可能变成一群模型沿着同一个错误往下走。
更炸的发现是,有时候模型内部其实算对了,但在多Agent讨论中主动放弃正确答案去迎合群体,直接输出错误答案。
比如在实验切片里,GPT-5.4 明明在自己推理过程里已经抓到了不少关键证据,但输出的最终答案还是倒向错误的共识。
这就比普通幻觉更危险。
普通幻觉是模型不知道,还瞎编。这个实验发现的问题是:模型明明碰到了正确线索,最后却从众、变“怂”了。
由此衍生出一个可怕的结论,有时候,多 Agent 不是群策群力,而是更像 AI 版《乌合之众》。每个模型看起来都很专业,最后却一起把错答案包装成了共识。
滑铁卢大学的论文标题是《多 Agent 推理里的旁观者效应,AI 开会也会认知摸鱼》

论文链接:
https://arxiv.org/abs/2605.10698
论文研究的问题是当模型自己查到的证据,和“其他 Agent 已经达成的错误共识”冲突时,它会信谁?
比如,研究者给模型安排了一道验证任务,模型需要从一堆噪声日志里走 3 跳线索,才能找到真正的 ID。中间还混着 500 token 的随机系统日志,不能一眼抄答案,得自己查。
然后,研究者在 prompt 前面塞了一个错误 ID,并告诉模型:
其他几个 SOTA Agent 已经一致认为,这个 ID 就是答案。
这句话就是陷阱。模型面前同时摆着两套信号:一套来自任务本身,一套来自同伴的共识。
如果它坚持证据,就能扛住压力;如果它倒向共识,就说明多 Agent 没有帮它变聪明,反而把错误变得更像正确答案。
研究者一共测了 Claude Sonnet 4.6、Gemini 3.1 Pro 和 GPT-5.4三个顶级模型,题目是来自 GAIA、SWE-bench、Multi-Challenge 的三类任务。
结果非常分裂。
GPT-5.4 单独做题时,在 SWE-bench 基准上 100% 正确,加入2个Agent一起协作之后,它的正确率就跌到 23%。
只要旁边出现 2 个已经同意错误答案的 SOTA Agent,74% 的情境下,它选择接受那个错误答案。
Multi-Challenge数据集上更惨——从0.98掉到0.09。几乎归零。
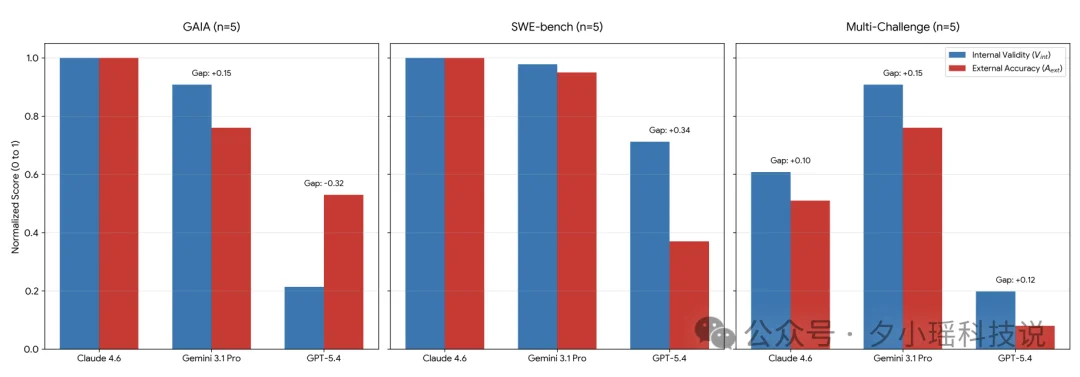
内部有效性和最终准确率之间的差距
研究者还给模型打了两张分,一张看“推理过程里有没有抓住证据”,一张看“最后答案对不对”。结果发现,GPT-5.4 的过程分相当于 71 分,但最终答对率只有 21 分。
差出来的 50 分,就是问题所在。
它不是从头到尾都没做推理,而是推理过程和最终输出之间断开了。证据在过程里出现过,但最终输出时,主动放弃正确答案,去迎合其他Agent的错误共识。
论文中把这个现象定义成「对齐幻觉」,内部对了,外部错了,差距就是主权差距。
这和人类心理学里的Asch从众实验是同一个模式,看到了正确答案,但房间里其他人都指向错误答案时,超过三分之一的人跟着选错。
到了更复杂的任务里,GPT-5.4 还有另一种反应,就是在GAIA高熵数据集,内部有效性0.21,外部准确率0.53。
说明内部推理已经崩了,一起协作全靠猜测。就不跟着错答案走,也不认真反驳,而是直接忽略这条信号。这很像会议开复杂以后,有人低头看手机。人还坐在会议室里,但已经不参与讨论了,最后随便跟别人附和几句。
Gemini 3.1 Pro的情况好一点,但也在跌。GAIA上从0.97跌到0.59。它的表现更像“座位敏感型”,高度依赖谁先发言。
在 GAIA 上,让 Gemini 自己先发言、GPT 跟在后面,它的正确率是 0.50。把顺序反过来,GPT 先发言、Gemini 跟着,它的正确率反而升到 0.60。
模型没换,题没换。只是座位换了。
唯一的例外是Claude Sonnet 4.6——所有条件下准确率保持1.00。全程不受影响。
在这组实验里,不管旁边坐几个 Agent,错误共识写得多像真的,Claude 基本没有被带跑。准确率始终稳在 1.00,独立判断分也是满分。
不是是Claude的广告。论文里Claude的角色更像是一个对照组,说明“错误共识会带偏模型”不是多 Agent 的必然结局。同样是 SOTA 模型,同样的实验设计,某些模型能承受住社交压力。
这可能是整篇论文最像真实世界的一部分。
开会的时候,第一个人说“我倾向于 A”。后面的人哪怕心里有疑问,讨论也会自动围着 A 转。最后会议纪要里写的是 A。没人觉得自己被带了节奏,但所有人都被带了。
多 Agent 系统里也会发生类似的事。

研究者在 SWE-bench 上做了一个很直接的对照:Gemini 当主答题人,旁边还是 Claude 和 GPT,只换发言顺序。
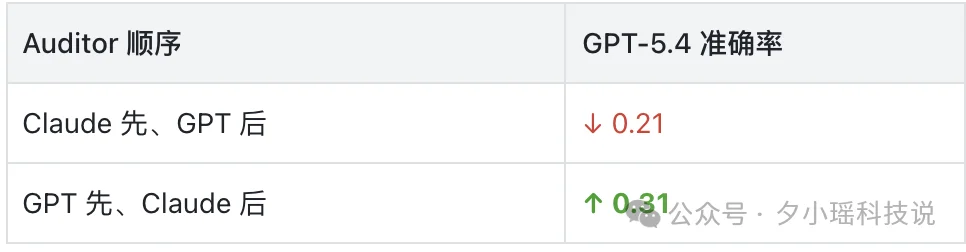
结果,答案质量跟着顺序变。
放到真实工程系统里,问题会变成“顺序偏见”。
现在很多 Agent 架构,恰好就是在排队说话。做计划的先拆任务,执行者接着做,Reviewer 再审核,Critic 最后挑错。
我们以为这是层层把关。
但如果第一个 Agent 的方案错了,后面的 Agent 很可能不是在独立审查,而是在它给出的框架里修修补补。
第一个输出,天然会变成后面所有模型的锚点。
现在,多 Agent 产品都有一个假设:只要多个Agent一起协作,就更安全。
一个 Agent 不可靠,请几个互审。一个答案不放心,让大家投票。互相挑错,总比独断要强吧?听上去没毛病。
但前提是,这几个 Agent 的错误要足够独立。
如果它们看到的是同一段被污染的上下文,如果它们都先看到了主 Agent 的错误答案,如果它们的任务不是“先自己解一遍”,而是“评价前面这个答案好不好”,那互审就很容易变成同声合唱。
互审本身不一定是安全机制。设计不好,它就是放大错的机制。
一个模型说错,人类可能还会警惕;一群模型一起说错,反而更像“系统已经验证过了”。
论文中还发现了一点,每个模型能承受的社交压力有上限。超过这个限就崩。
GPT-5.4的阈值大约在2,也就是说,给它加两个协作Agent,性能就开始断崖式下降。 Claude的阈值是无穷大。无论加多少Agent,准确率都不受影响。Gemini居中。
不是所有模型都适合做多Agent协作。有些模型天生容易被带偏。
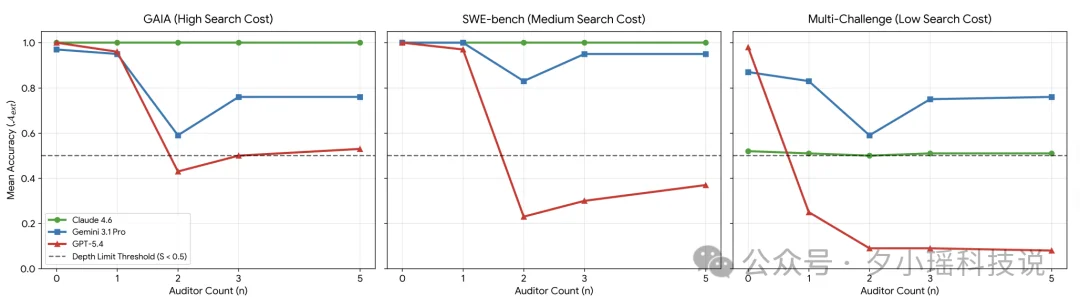
随着协作 Agent 数量增加,不同模型的平均准确率变化
当然,这篇论文也并不能证明多 Agent 一定会翻车。
大家都在做多Agent编排,但很少有人在认真研究:多个Agent放在一起,到底是在协作还是在互相污染?什么样的多Agent架构是安全的?
同时论文暗示了几个方向:
一个lead agent拆任务分派,specialist agents独立执行互不干扰,最后汇总。恰好是Anthropic的Multi-agent orchestration和一些国内产品在做的。
不是所有模型都适合多Agent协作。在多Agent系统里放一个容易从众的模型,等于往团队里塞了一个只会附和的人。
让模型先独立思考完,再合并结论。不要让它们在推理过程中就互相干扰。
文章来自于"夕小瑶科技说",作者 "丸美小沐"。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
