Codex自我蒸馏玩法火了!OpenAI员工亲授:复制粘贴就能让AI消灭重复劳动
Codex自我蒸馏玩法火了!OpenAI员工亲授:复制粘贴就能让AI消灭重复劳动Codex自家程序员,直接把Codex「自我蒸馏」的秘籍给爆出来了…
来自主题: AI资讯
6771 点击 2026-05-26 10:27
 搜索
搜索
Codex自家程序员,直接把Codex「自我蒸馏」的秘籍给爆出来了…

今年以来,在线策略蒸馏 OPD(On-Policy Distillation)已经逐渐成为大厂 LLM 后训练中的重要组件,例如 DeepSeek-V4,GLM5 就使用了多教师 OPD 来整合不同领域专家模型的能力,相比混合奖励强化学习收敛更快、效果更好。

最近,来自上海创智学院、复旦大学等机构的研究者提出了 Hallo-Live,试图正面解决这个矛盾。论文于 2026 年 4 月 26 日 发布在 arXiv。该方法将 异步双流扩散(Asynchronous Dual-Stream Diffusion) 与 人类偏好引导蒸馏(Human-Centric Preference-Guided DMD) 结合起来

阿里巴巴 Z-Image 团队联合香港科技大学、加州大学圣地亚哥分校、香港中文大学等机构提出 D-OPSD(On-Policy Self-Distillation),首个针对少步扩散模型的在线策略自蒸馏框架。D-OPSD 无需奖励模型、无需成对偏好数据,

当下的大模型后训练(Post-training)pipeline 中,On-Policy Distillation(OPD)已经成为了明星技术。从 Qwen3、MiMo 到 GLM-5,业界纷纷采用 OPD 并报告了巨大的性能提升。相比于强化学习(RL)稀疏的结果奖励,OPD 提供了密集的 Token 级别监督信号,看起来就像是一顿「免费的午餐」。

在多模态大模型(MLLM)快速发展的浪潮中,融合多模型 “集体智慧” 已成为提升模型性能的关键路径,并催生了多教师知识蒸馏这一主流范式。然而,不同来源的教师模型在架构与优化上的差异,其在相似推理过程中呈现出不稳定甚至偏移的认知轨迹,即 “概念漂移”(Concept Drift)。
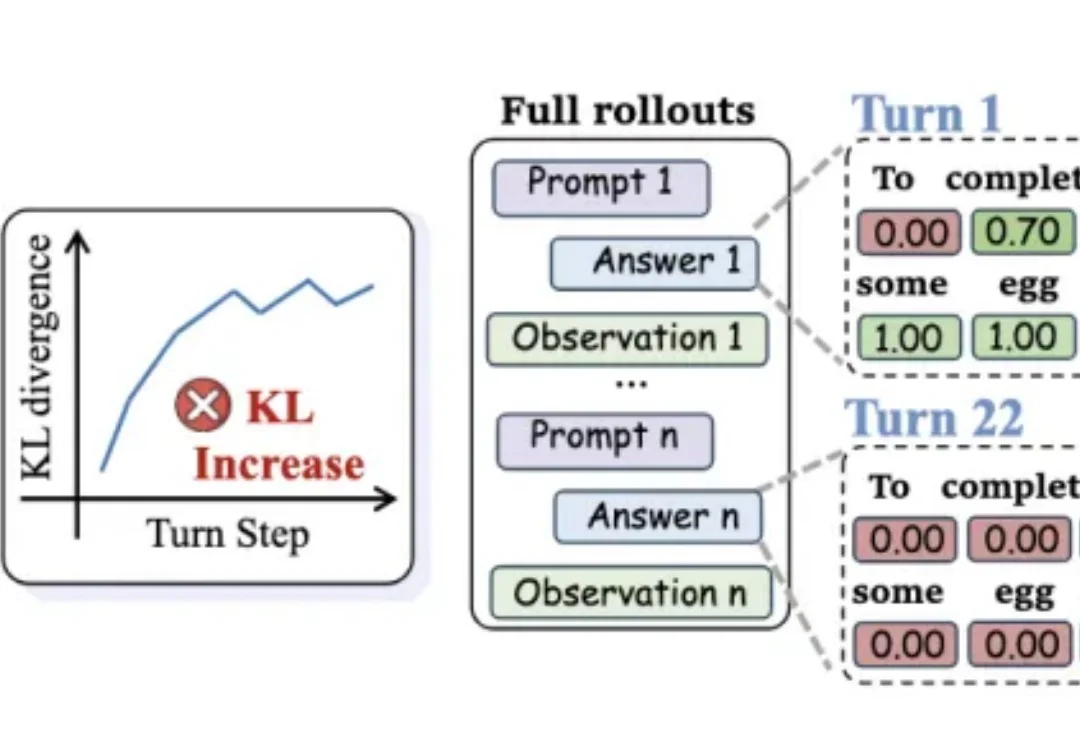
把强大模型的能力“蒸馏”给小模型,听起来很美—— 但放到多轮对话Agent场景里,效果往往一塌糊涂。

2026 年初,浙江大学发表了一篇系统性的 SoK 论文《Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward》,给Skill下了一个正式定义。

你或许刷到了一段来自印度南部服装厂的视频。 工厂工人佩戴头戴摄像头,记录手部动作以训练人工智能系统。 这是因为随着特斯拉、Figure AI 等公司竞相开发人形机器人,训练它们所需的真实世界动作数据变

一个毫无代码的文本,竟连霸GitHub热榜第一。Karpathy的编程神技被化作「AI紧箍咒」,让乱写Bug的大模型瞬间老实!