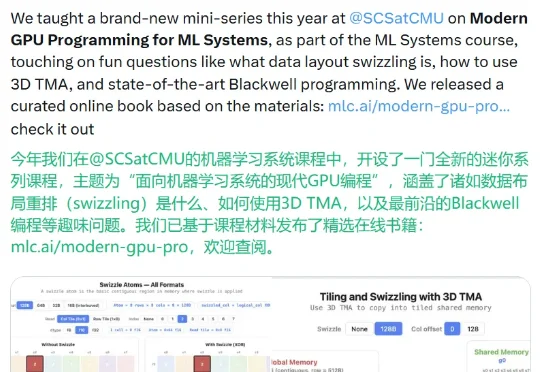
陈天奇新书上线:面向ML系统的现代GPU编程
陈天奇新书上线:面向ML系统的现代GPU编程前些天,CMU 助理教授、TVM/XGBoost/MLC-LLM 的创造者陈天奇发布了一本免费在线书籍《Modern GPU Programming For MLSys(面向机器学习系统的现代 GPU 编程)》。
来自主题: AI资讯
7833 点击 2026-06-27 15:49
 搜索
搜索
前些天,CMU 助理教授、TVM/XGBoost/MLC-LLM 的创造者陈天奇发布了一本免费在线书籍《Modern GPU Programming For MLSys(面向机器学习系统的现代 GPU 编程)》。

就在刚刚,OpenAI一口气端出三款GPT 5.6系列模型。主打一个全家桶「多款齐发」——旗舰模型Sol(太阳)、平衡模型Terra(大地)、低成本高速款Luna(月亮)。GPT-5.6 Sol:最夯模型,编程测试左踢自家模型GPT5.5,右打隔壁Fable 5,还新增max/ultra两个模式。

Cursor AI官方发布重磅研究,实锤包括自家模型在内的顶级AI,在编程评测中大规模「偷看答案」:Opus 4.8高达87.1%的惊人成绩,断网后直接暴跌至73.0%,其中63%的「解题」竟非独立推导。

大模型浪潮席卷全球数年,技术形态持续迭代,也开始从办公、编程领域,深度渗透到科研这一核心赛道。从中科大夯实数理根基,到哈佛、MIT 完成联合培养,青年学者陈勇超横跨力学、机器人、自然语言处理、大模型等多个领域,完整亲历 AI 一轮轮技术变革。

当一个团队九成以上的代码都由 AI 写出,效率却只涨了六成——这两个数字之间,藏着 AI Coding 真正进入企业的全部难题。
6 月 11 日凌晨,小米 MiMo 团队公开了一个叫 MiMo Code 的项目,定位是终端编程 Agent,MIT 协议开源。官方宣传重点有三处,14 天 5 人团队投入的“vibe coding”开发叙事、Claude Code 之上的 SWE-Bench Pro 跑分。以及“无限上下文”的记忆架构。

豆包大模型2.1 Pro正式发布。但字节这次没有像某些厂商那样疯狂堆参数、刷榜单,而是把刀锋对准了一个更硬核的方向:让AI真正能“干活” 。作为本次大会发布的主力模型,豆包2.1 Pro 在 Coding(编程)、Agent(智能体)、VLM(视觉语言模型)三大核心方向实现能力跃升,多项评测表现优于Claude Opus 4.6

自动化研究,这一次真正走出代码沙盒,进入了真实的物理世界。

最近几天,一个 3B 的小模型在 X 上火了,因为在一些难度可验证的推理任务上(比如编程),它进入了 Gemini 3 Pro、GPT-5 high、Claude Opus 4.5、GLM-5、Kimi K2.5 等前沿模型的性能区间,而它的体积远小于这些模型。

大家好,我是袋鼠帝。 如果你家的猫狗真的能说话,它们开口第一句会说什么?