
南大周志华团队最新力作:一个算法通吃所有,在线学习迎来新范式?
南大周志华团队最新力作:一个算法通吃所有,在线学习迎来新范式?世界是动态变化的。为了理解这个动态变化的世界并在其中运行,AI 模型必须具备在线学习能力。为此,该领域提出了一种新的性能指标 —— 适应性遗憾值(adaptive regret),其定义为任意区间内的最大静态遗憾值。
来自主题: AI技术研报
7529 点击 2025-08-05 16:29
 搜索
搜索
世界是动态变化的。为了理解这个动态变化的世界并在其中运行,AI 模型必须具备在线学习能力。为此,该领域提出了一种新的性能指标 —— 适应性遗憾值(adaptive regret),其定义为任意区间内的最大静态遗憾值。

OpenAI前研究员、Meta「AI梦之队员」毕书超在哥大指出:AGI就在眼前,突破需高质数据、好奇驱动探索与高效算法;Scaling Law依旧有效,规模决定智能,终身学习才是重点。

在AI飞速发展、智能硬件遍地开花的2025年,对普通用户来说,真正的门槛其实只有两个:我能不能即开即用?我能不能放心交互? 这一点,在2025世界人工智能大会(WAIC)7万平方米的展厅里格外清晰——人们对技术本身的好奇正在消退,新的侧重点是寻找值得托付的系统:用得起、连得通、不泄露隐私,也不被算法摆布。
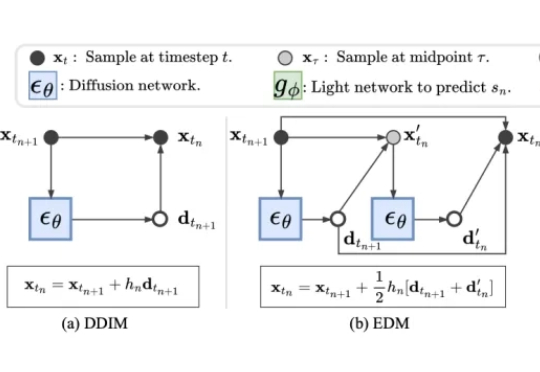
近年来,扩散模型(Diffusion Models)凭借出色的生成质量,迅速成为图像、视频、语音、3D 内容等生成任务中的主流技术。从文本生成图像(如 Stable Diffusion),到高质量人脸合成、音频生成,再到三维形状建模,扩散模型正在广泛应用于游戏、虚拟现实、数字内容创作、广告设计、医学影像以及新兴的 AI 原生生产工具中。
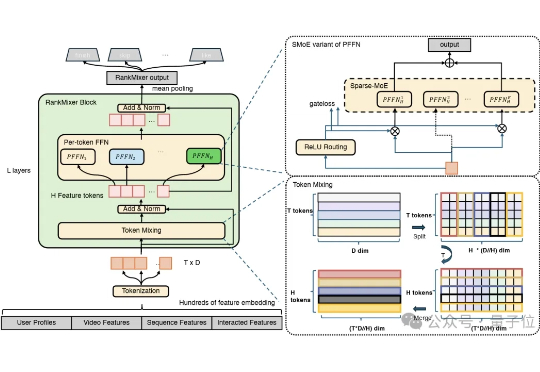
你刷的每一条短视频,背后都隐藏着推荐算法的迭代与革新。 作为最新成果,字节跳动的算法团队提出的全新推荐排序模型架构RankMixer,在兼顾算力利用率的同时,实现了模型效果的可扩展性。
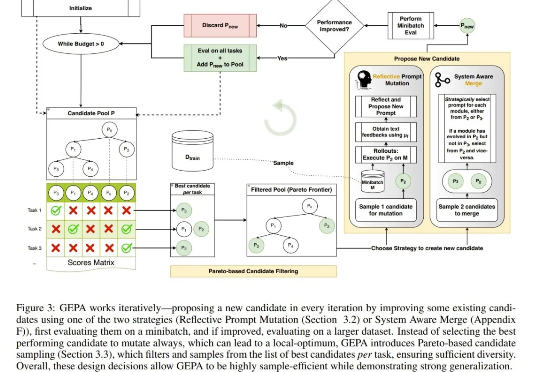
仅靠提示词优化就能超越 DeepSeek 开发的 GRPO 强化学习算法? 是的,你没有看错。近日上线 arXiv 的一篇论文正是凭此吸引了无数眼球。
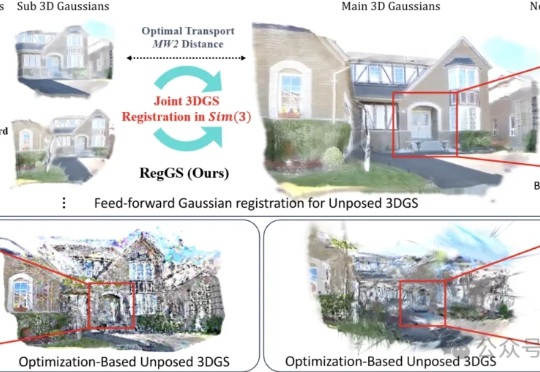
想象一下,你随便用手机拍了几张家里的照片,没有精确的相机位置,甚至照片之间重叠都很少。 现在,一个新算法能把这些零散的2D图片,“拼”成一个厘米级精度的3D数字模型,效果好到可以直接放进VR头显里“云旅游”。

零一万物2025年全面转向ToB战略,推出企业级Agent并升级万智平台2.0。通过高定制服务、算法工程师驻场深入解决客户需求,避开价格战。合作开放,聚焦为大型企业提供可量化业务提升的AI方案,当前服务周期长但回报高。

从病历、口味偏好到不堪回首的往事,AI正悄悄建立你的数字人格档案。但你真准备好让AI永远记住你的每一句话?AI算法背后,不止有温柔,还有社死和残酷。
你有没有想过,为什么硅谷的每个人都在想着用AI替代招聘官?风投们已经向那些承诺能完全自动化招聘过程的公司砸了数十亿美元,从AI简历筛选器到能独立面试的聊天机器人,再到声称能在无人干预情况下找到完美候选人的算法。