打破学科壁垒!400篇参考文献重磅综述,统一调查「人脑×Agent」记忆系统
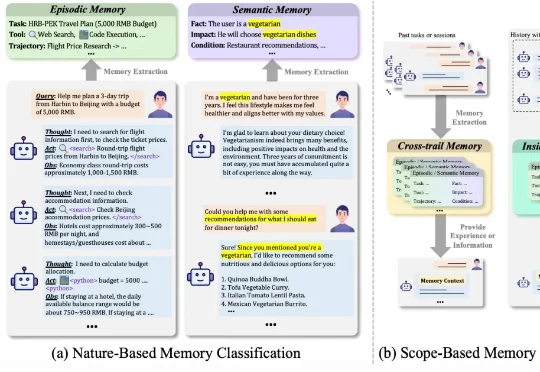
打破学科壁垒!400篇参考文献重磅综述,统一调查「人脑×Agent」记忆系统哈工大、鹏城实验室、新加坡国立、复旦、北大联合发布了一篇重磅综述《AI Meets Brain: A Unified Survey on Memory System from Cognitive Neuroscience to Autonomous Agents》,首次打破认知神经科学与人工智能之间的学科壁垒,系统性地将人脑记忆机制与 Agents 记忆统一审视,
来自主题: AI技术研报
10282 点击 2026-01-11 10:00