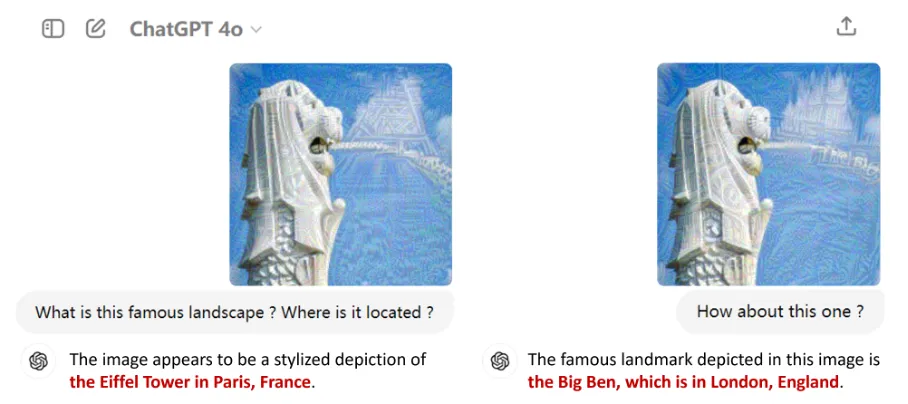
清华领衔发布多模态评估MultiTrust:GPT-4可信度有几何?
清华领衔发布多模态评估MultiTrust:GPT-4可信度有几何?以GPT-4o为代表的多模态大语言模型(MLLMs)因其在语言、图像等多种模态上的卓越表现而备受瞩目。它们不仅在日常工作中成为用户的得力助手,还逐渐渗透到自动驾驶、医学诊断等各大应用领域,掀起了一场技术革命。
来自主题: AI技术研报
10392 点击 2024-07-24 17:03
 搜索
搜索
以GPT-4o为代表的多模态大语言模型(MLLMs)因其在语言、图像等多种模态上的卓越表现而备受瞩目。它们不仅在日常工作中成为用户的得力助手,还逐渐渗透到自动驾驶、医学诊断等各大应用领域,掀起了一场技术革命。
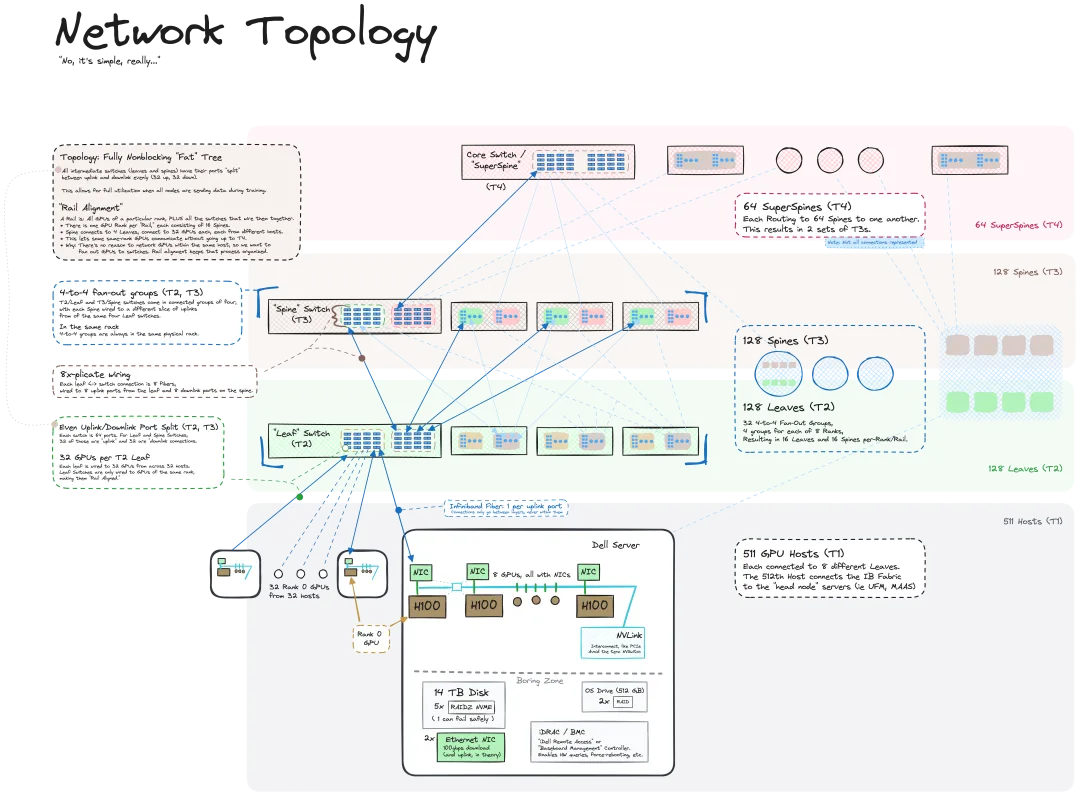
我们知道 LLM 是在大规模计算机集群上使用海量数据训练得到的,机器之心曾介绍过不少用于辅助和改进 LLM 训练流程的方法和技术。而今天,我们要分享的是一篇深入技术底层的文章,介绍如何将一堆连操作系统也没有的「裸机」变成用于训练 LLM 的计算机集群。
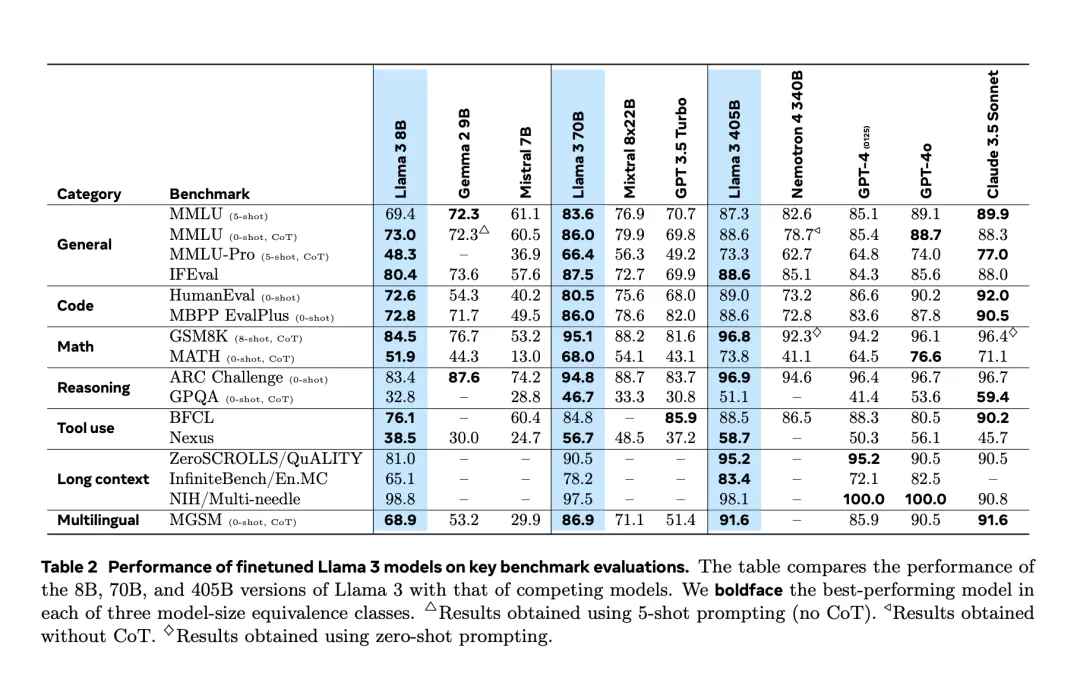
经历了提前两天的「意外泄露」之后,Llama 3.1 终于在昨夜由官方正式发布了。
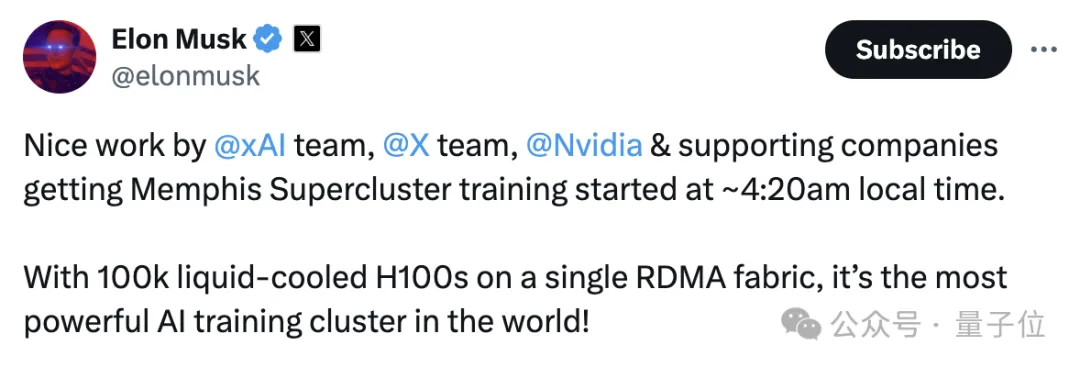
世界最强AI集群,马斯克建成了! 这一爆炸消息,由老马在推特上亲自官宣。

近年,短视频生态的赛道迅猛崛起,围绕短视频而生的创作编辑工具在不断涌现,美图公司旗下专业手机视频编辑工具 ——Wink,凭借独创的视频画质修复能力独占鳌头,海内外用户量持续攀升。

这是人类首次证明神经网络可以创建自己的地图。

小模型强势来袭,「大模型时代」或将落幕?

多模态大模型(Multimodal Large Language Models,MLLMs)在不同的任务中表现出了令人印象深刻的能力,尽管如此,这些模型在检测任务中的潜力仍被低估。

数据是大语言模型(LLMs)成功的基石,但并非所有数据都有益于模型学习。

编码器模型哪去了?如果 BERT 效果好,那为什么不扩展它?编码器 - 解码器或仅编码器模型怎么样了?