
LIama 3+Mamba强强联手!蒸馏到线性RNN,推理速度提升1.6倍
LIama 3+Mamba强强联手!蒸馏到线性RNN,推理速度提升1.6倍把Llama 3蒸馏到Mamba,推理速度最高可提升1.6倍!
来自主题: AI资讯
9033 点击 2024-09-10 14:10
 搜索
搜索
把Llama 3蒸馏到Mamba,推理速度最高可提升1.6倍!

本文作者来自于清华大学电子工程系,北京大学人工智能研究院、第四范式、腾讯和清华-伯克利深圳学院。其中第一作者张瑞泽为清华大学硕士,主要研究方向为博弈算法。通讯作者为清华大学电子工程系汪玉教授、于超博后和第四范式研究员黄世宇博士。
最近,国外的一份研究报告揭秘了 OpenAI、围绕和谷歌在 AI Infra 层的布局,我们将文章提炼出了核心观点,并进行精校翻译。

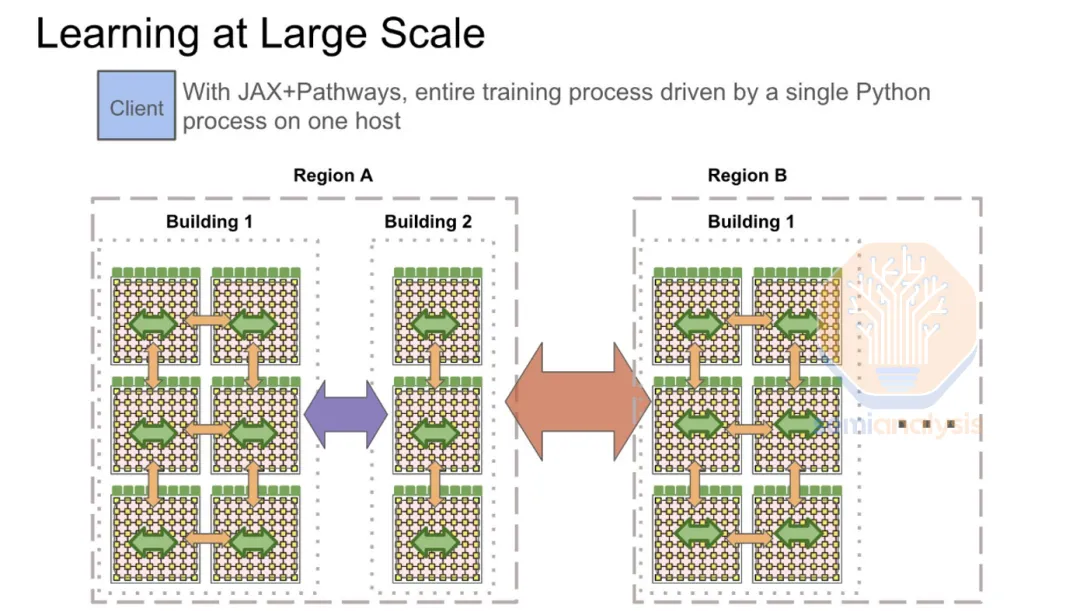
如果可以使用世界上所有的算力来训练AI模型,会怎么样?近日,凭借发布了开源的Hermes 3(基于Llama 3.1)而引起广泛关注的Nous Research,再次宣布了一项重大突破——DisTrO(分布式互联网训练)。

基于图神经网络的方法被广泛应用于不同问题并且显著推动了相关领域的进步,包括但不限于数据挖掘、计算机视觉和自然语言处理。考虑到图神经网络已经取得了丰硕的成果,一篇全面且详细的综述可以帮助相关研究人员掌握近年来计算机视觉中基于图神经网络的方法的进展,以及从现有论文中总结经验和产生新的想法。

由AI生成的内容渐渐充斥了互联网。

所有模型都是通过在来自互联网的海量数据上进行训练来工作的,然而,随着人工智能越来越多地被用来生成充满垃圾信息的网页,这一过程可能会受到威胁。
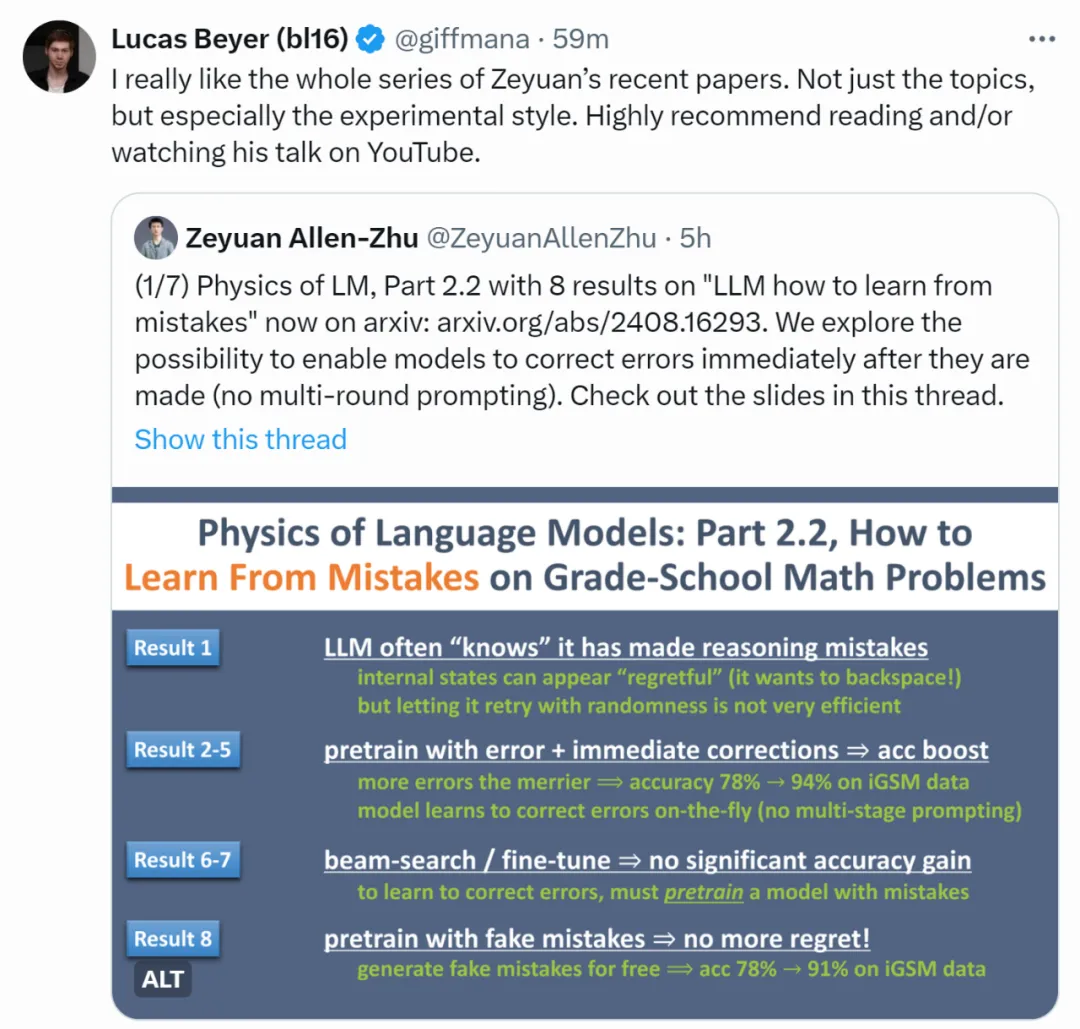
即便是最强大的语言模型(LLM),仍会偶尔出现推理错误。除了通过提示词让模型进行不太可靠的多轮自我纠错外,有没有更系统的方法解决这一问题呢?
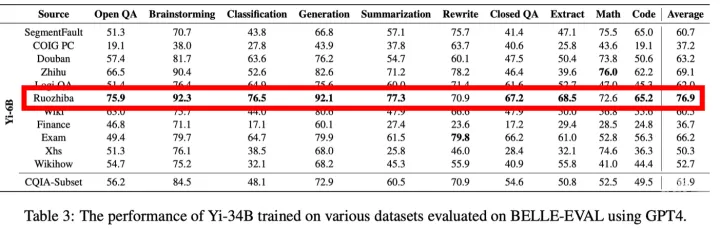
今年4月,中科院、滑铁卢大学等机构联合发表了一篇AI行业论文,让互联网上的“乐子人”直呼离谱。
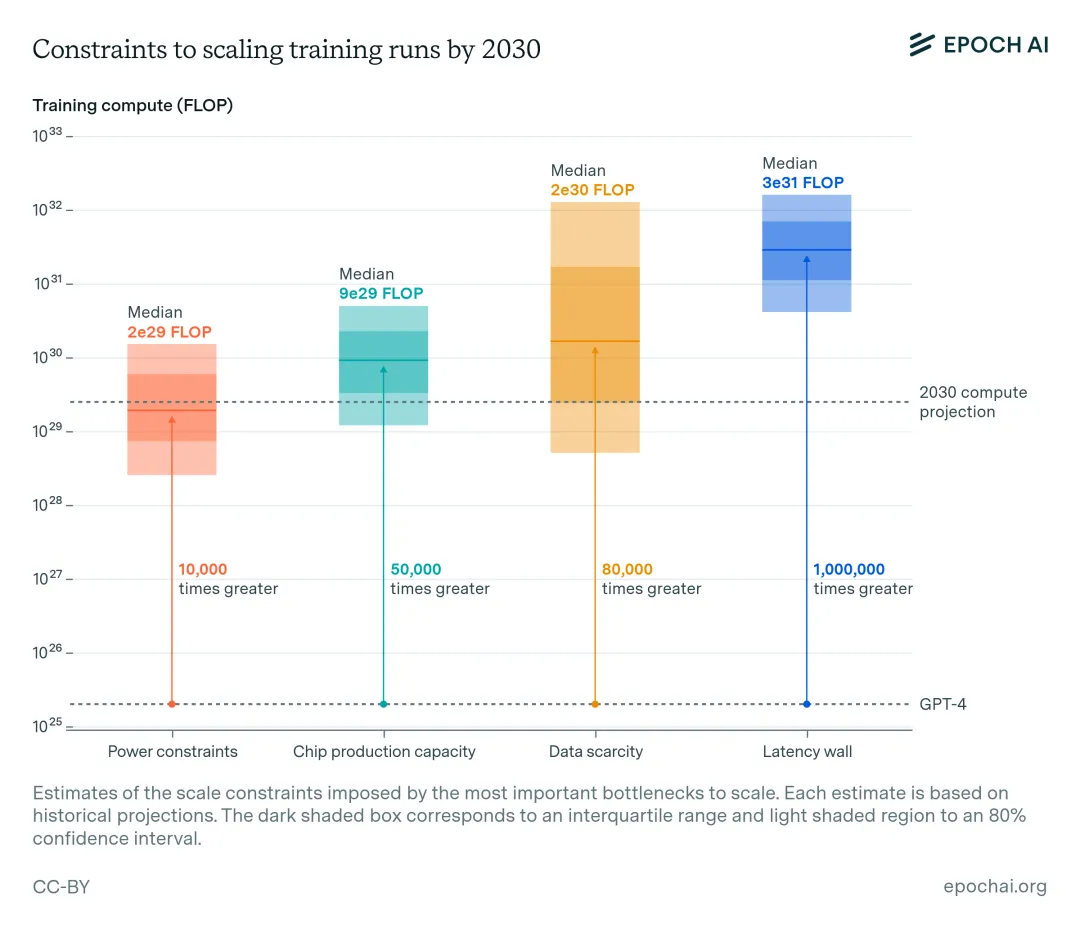
9 月 2 日,马斯克发文称,其人工智能公司 xAI 的团队上线了一台被称为「Colossus」的训练集群,总共有 100000 个英伟达的 H100 GPU。