
一行代码Post-Train任意长序列!360智脑开源360-LLaMA-Factory
一行代码Post-Train任意长序列!360智脑开源360-LLaMA-Factory大模型长序列的处理能力已越来越重要,像复杂长文本任务、多帧视频理解任务、以及 OpenAI 近期发布的 o1、o3 系列模型的高计算量模式,需要处理的输入 + 输出总 token 数从几万量级上升到了几百万量级。
来自主题: AI技术研报
10052 点击 2025-01-11 13:45
 搜索
搜索
大模型长序列的处理能力已越来越重要,像复杂长文本任务、多帧视频理解任务、以及 OpenAI 近期发布的 o1、o3 系列模型的高计算量模式,需要处理的输入 + 输出总 token 数从几万量级上升到了几百万量级。
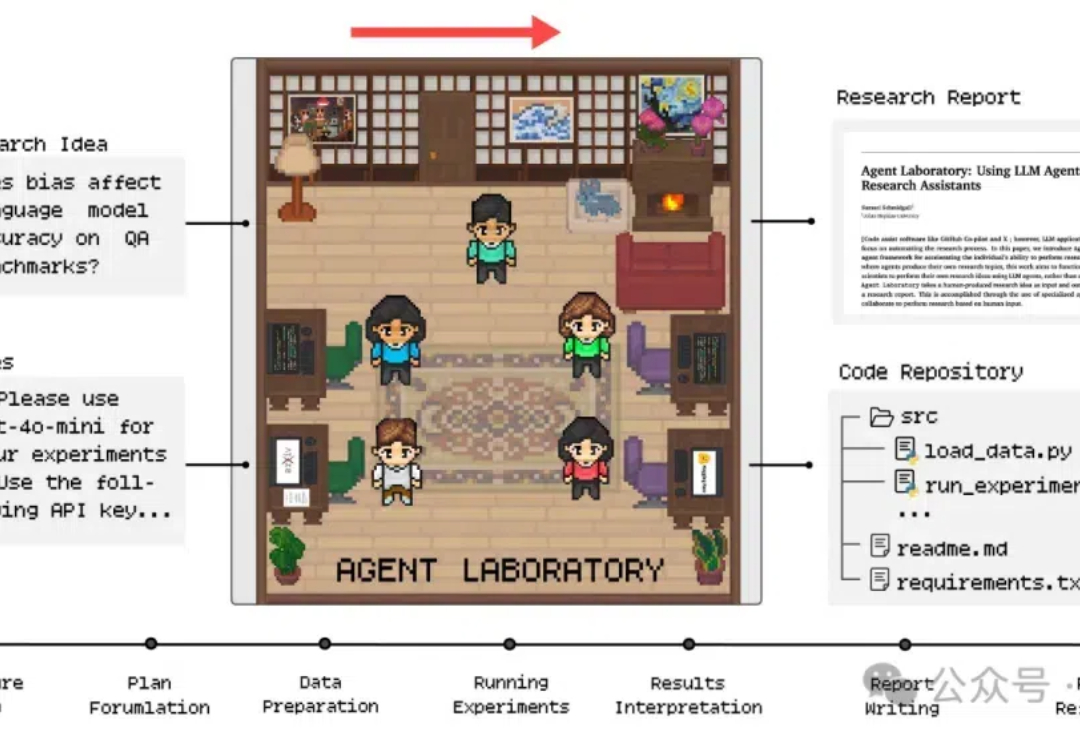
芯片强者AMD最新推出科研AI,o1-preview竟成天选打工人?! 注意看,只需将科研idea和相关笔记一股脑丢给AI,研究报告甚至是代码就能立马出炉了。

大连理工大学的研究人员提出了一种基于Wasserstein距离的知识蒸馏方法,克服了传统KL散度在Logit和Feature知识迁移中的局限性,在图像分类和目标检测任务上表现更好。
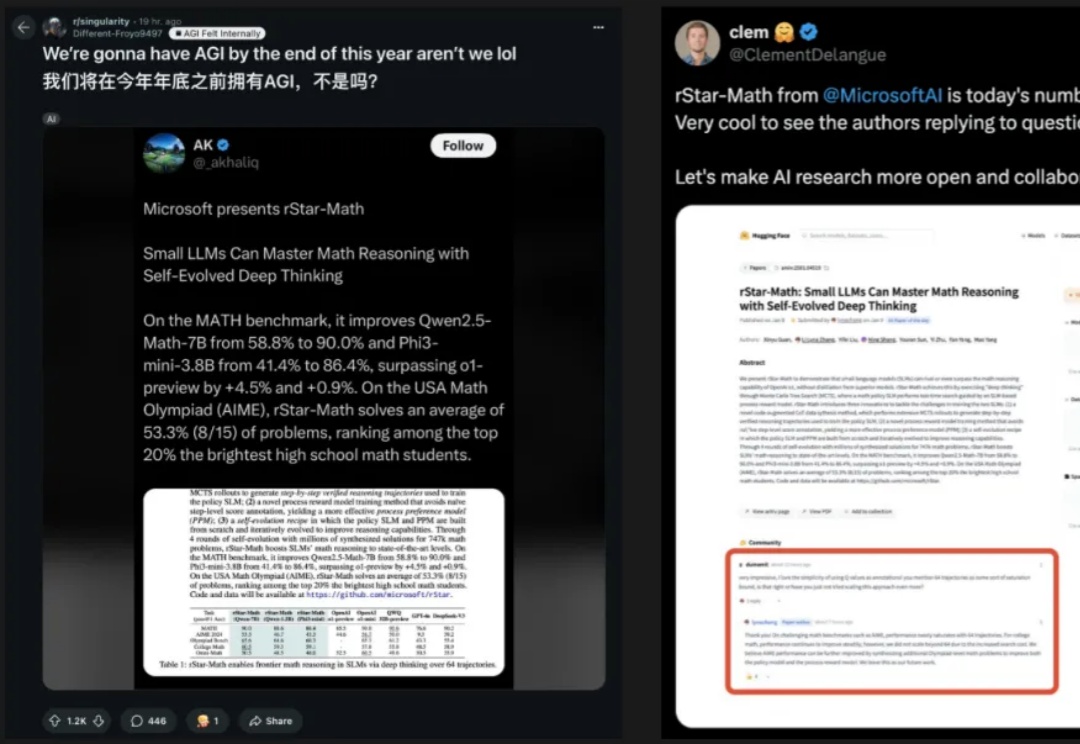
小模型也能击败o1?微软全华人团队提出rStar-Math算法,三大革命性技术突破,不仅让SLM在数学推理能力上刷新SOTA,更是挤进了全美20%顶尖高中生榜单。

最新综述论文探讨了知识蒸馏在持续学习中的应用,重点研究如何通过模仿旧模型的输出来减缓灾难性遗忘问题。通过在多个数据集上的实验,验证了知识蒸馏在巩固记忆方面的有效性,并指出结合数据回放和使用separated softmax损失函数可进一步提升其效果。
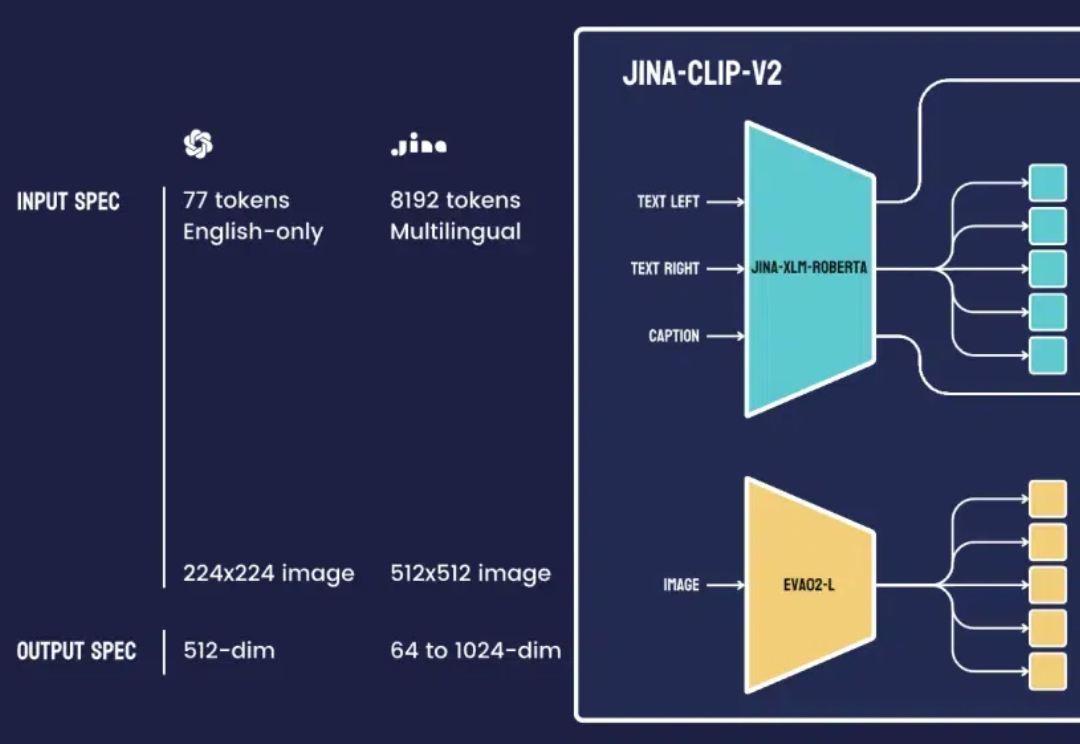
最近,我们团队的一位工程师在研究类 ColPali 模型时,受到启发,用新近发布的 jina-clip-v2 模型做了个颇具洞察力的可视化实验。
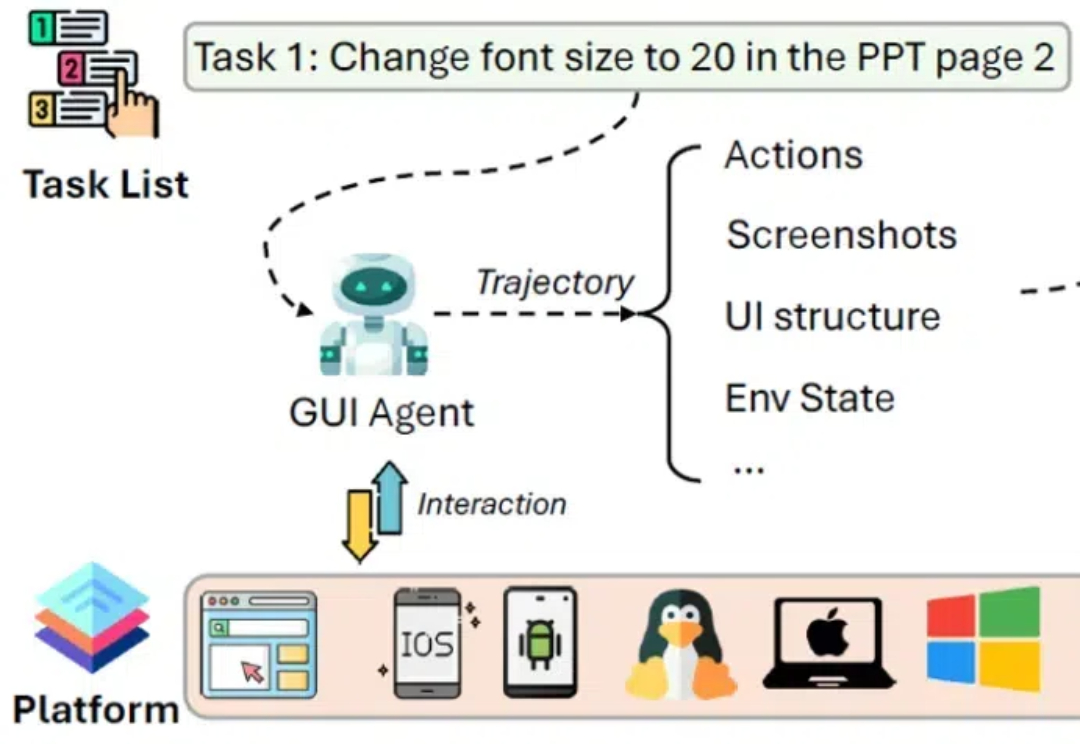
图形用户界面(Graphical User Interface, GUI)作为数字时代最具代表性的创新之一,大幅简化了人机交互的复杂度。
不知这是极大地提高了网站的安全性,还是成功地把人类拒绝于网站“门外”? 在使用 App、网页应用时,你有没有遇到过这样的情况:一个验证窗口突然跳出来,要求你完成某个任务,证明“你是人类,而不是机器人”?
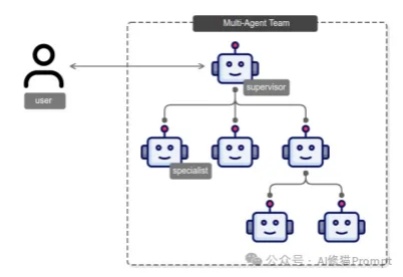
随着大语言模型(LLM)技术的快速发展,单一AI智能体已经展现出强大的问题解决能力。然而,在面对复杂的企业级应用场景时,单一智能体的能力往往显得捉襟见肘。

老婆饼里没有老婆,夫妻肺片里没有夫妻,RLHF 里也没有真正的 RL。在最近的一篇博客中,德克萨斯大学奥斯汀分校助理教授 Atlas Wang 分享了这样一个观点。