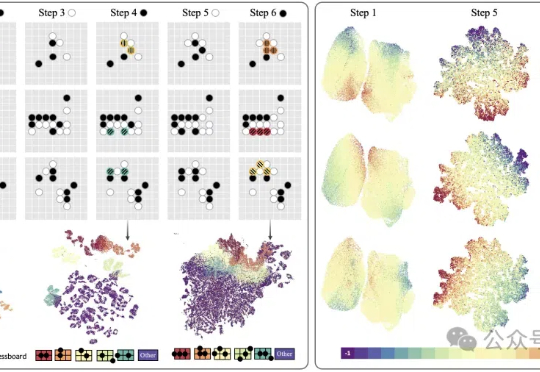
豆包团队视频生成新突破:无需语言模型,仅凭“视觉”就能学习复杂任务
豆包团队视频生成新突破:无需语言模型,仅凭“视觉”就能学习复杂任务现在,豆包大模型团队联合北京交通大学、中国科学技术大学提出了VideoWorld。
来自主题: AI技术研报
8817 点击 2025-01-31 13:53
 搜索
搜索
现在,豆包大模型团队联合北京交通大学、中国科学技术大学提出了VideoWorld。

当谷歌在 2018 年推出 BERT 模型时,恐怕没有料到这个 3.4 亿参数的模型会成为自然语言处理领域的奠基之作。

首个FP4精度的大模型训练框架来了,来自微软研究院!
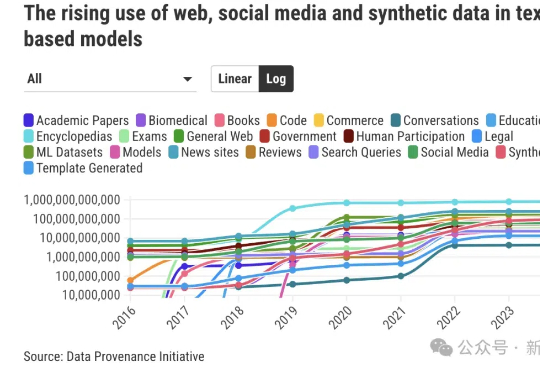
相比LLM和Agent领域日新月异、高度成熟的进展相比,数据收集方面的规范有明显滞后。由超过50名研究人员组成的「数据溯源计划」(DPI)旨在回答这样一个问题:AI训练所需的数据究竟来自何处?

基于一段文本提问时,人类和大模型会基于截然不同的思维模式给出问题。大模型喜欢那些需要详细解释才能回答的问题,而人类倾向于提出更直接、基于事实的问题。

「除了 Claude、豆包和 Gemini 之外,知名的闭源和开源 LLM 通常表现出很高的蒸馏度。」这是中国科学院深圳先进技术研究院、北大、零一万物等机构的研究者在一篇新论文中得出的结论。

VARGPT是一种新型多模态大模型,能够在单一框架内实现视觉理解和生成任务。通过预测下一个token完成视觉理解,预测下一个scale完成视觉生成,展现出强大的混合模态输入输出能力。
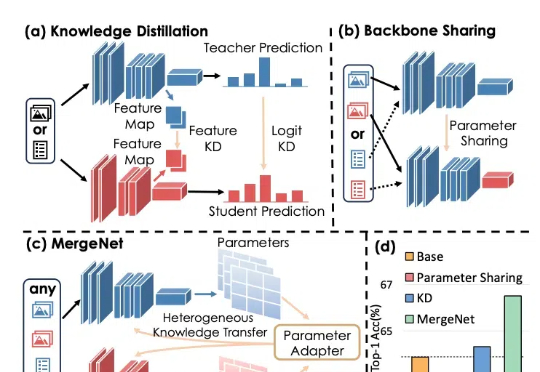
知识蒸馏通过训练一个紧凑的学生模型来模仿教师模型的 Logits 或 Feature Map,提高学生模型的准确性。迁移学习则通常通过预训练和微调,将预训练阶段在大规模数据集上学到的知识通过骨干网络共享应用于下游任务。

在美国发布AI禁令后,特朗普随即宣布了一项预算高达5000亿美元的AGI计划——星际之门,以保证其在AI领域的领先地位。而在大洋彼岸的中国,一家名为Deepseek的中国创业公司,只用了2048块显卡,就训练出了一个能与顶级模型相媲美的Deepseek-V3模型。

2028年,预计高质量数据将要耗尽,数据Scaling走向尽头。2025年,测试时计算将开始成为主导AI通向通用人工智能(AGI)的新一代Scaling Law。近日,CMU机器学习系博客发表新的技术文章,从元强化学习(meta RL)角度,详细解释了如何优化LLM测试时计算。