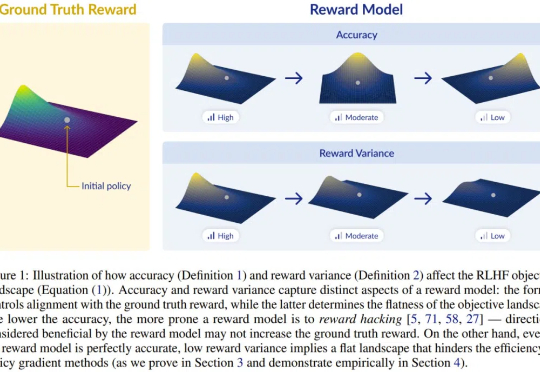
为什么明明很准,奖励模型就是不work?新研究:准确度 is not all you need
为什么明明很准,奖励模型就是不work?新研究:准确度 is not all you need训练狗时不仅要让它知对错,还要给予差异较大的、不同的奖励诱导,设计 RLHF 的奖励模型时也是一样。
来自主题: AI技术研报
11313 点击 2025-03-24 15:33
 搜索
搜索
训练狗时不仅要让它知对错,还要给予差异较大的、不同的奖励诱导,设计 RLHF 的奖励模型时也是一样。
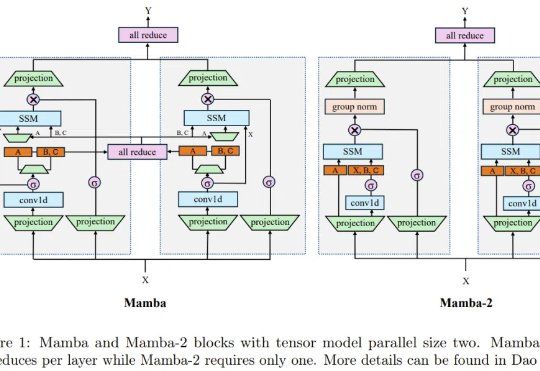
在过去的一两年中,Transformer 架构不断面临来自新兴架构的挑战。
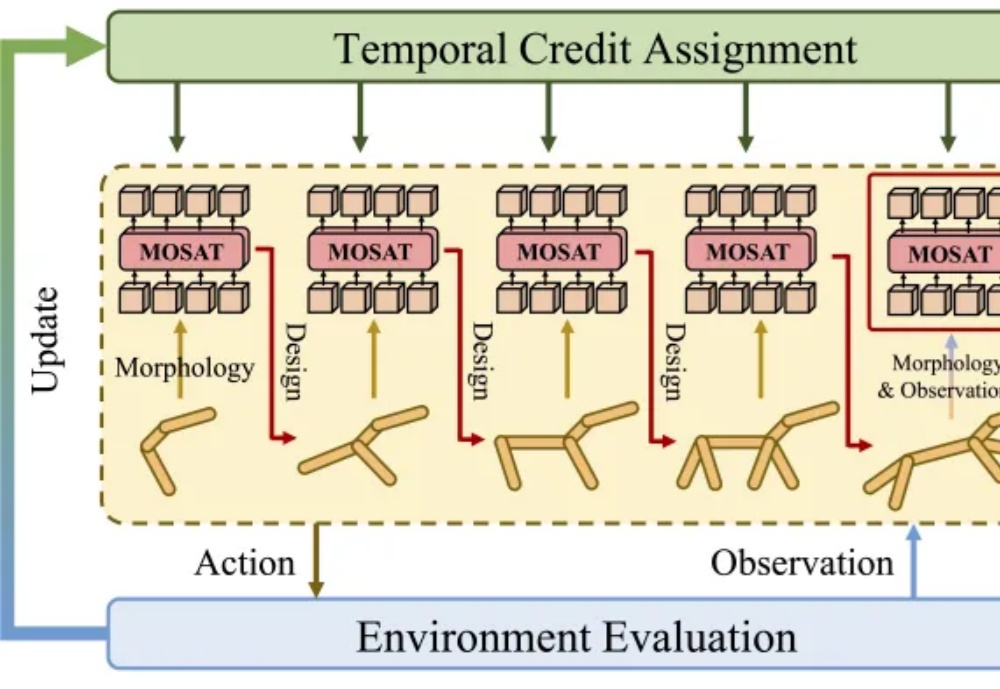
最近,全球 AI 和机器学习顶会 ICLR 2025 公布了论文录取结果:由蚂蚁数科与清华大学联合团队提出的全新具身协同框架 BodyGen 成功入选 Spotlight(聚光灯/特别关注)论文。
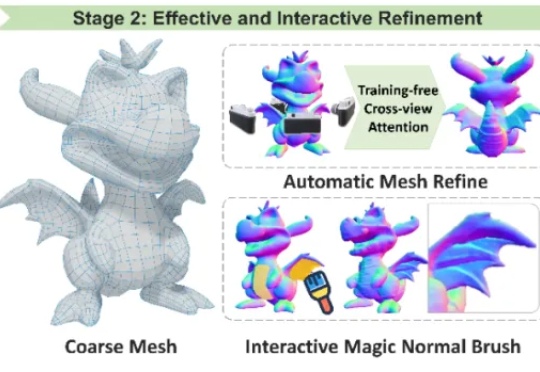
香港科技大学谭平教授团队在 CVPR 2025 发表两项三维生成技术框架,核心代码全部开源,助力三维生成技术的开放与进步。其中 Craftman3D 获得三个评委一致满分,并被全球多家知名企业如全球最大的多人在线游戏创作平台 Roblox, 腾讯混元 Hunyuan3D-2,XR 实验室的 XR-3DGen 和海外初创公司 CSM 的 3D 创作平台等重量级项目的引用与认可。
万字长文,对多模态LLM中对齐算法进行全面系统性回顾!

华人学者、斯坦福大学副教授 James Zou 领导的团队提出了 TextGrad ,通过文本自动化“微分”反向传播大语言模型(LLM)文本反馈来优化 AI 系统。只需几行代码,你就可以自动将用于分类数据的“逐步推理”提示转换为一个更复杂的、针对特定应用的提示。

虽然大多数强化学习(RL)方法都在使用浅层多层感知器(MLP),但普林斯顿大学和华沙理工的新研究表明,将对比 RL(CRL)扩展到 1000 层可以显著提高性能,在各种机器人任务中,性能可以提高最多 50 倍。
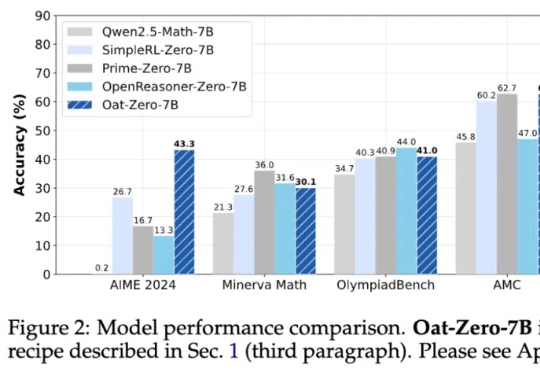
其实大模型在DeepSeek-V3时期就已经「顿悟」了?
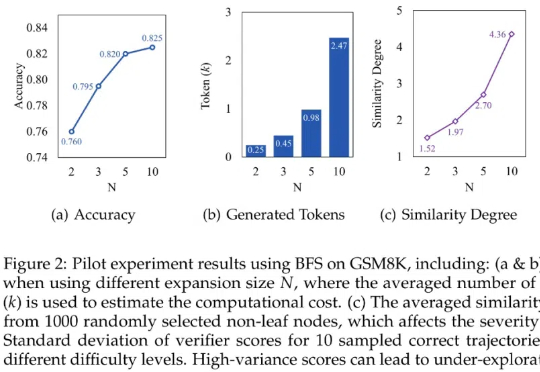
本文探讨基于树搜索的大语言模型推理过程中存在的「过思考」与「欠思考」问题,并提出高效树搜索框架——Fetch。本研究由腾讯 AI Lab 与厦门大学、苏州大学研究团队合作完成。
来自清华大学、哈佛大学等机构的研究团队提出了一种创新方法——4D LangSplat。该方法基于动态三维高斯泼溅技术,成功重建了动态语义场,能够高效且精准地完成动态场景下的开放文本查询任务。这一突破为相关领域的研究与应用提供了新的可能性, 该工作目前已经被CVPR2025接收。