
o3崛起,但推理模型离「撞墙」只剩一年?
o3崛起,但推理模型离「撞墙」只剩一年?OpenAI的o3推理模型席卷AI界,算力暴增10倍,能力突飞猛进!但专家警告:最多一年,推理模型可能一年内撞上算力资源极限。OpenAI还能否带来惊喜?
来自主题: AI技术研报
10230 点击 2025-05-31 15:36
 搜索
搜索
OpenAI的o3推理模型席卷AI界,算力暴增10倍,能力突飞猛进!但专家警告:最多一年,推理模型可能一年内撞上算力资源极限。OpenAI还能否带来惊喜?
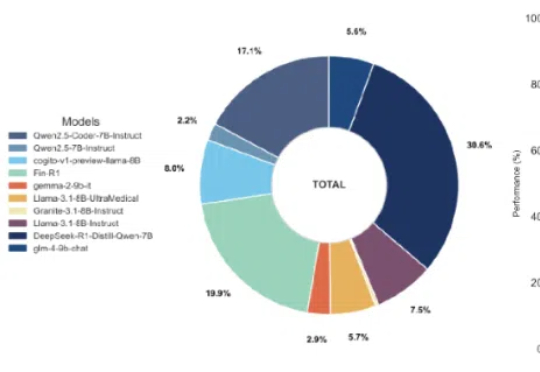
近年来,语言模型技术迅速发展,然而代表性成果如Gemini 2.5Pro和GPT-4.1,逐渐被谷歌、OpenAI等科技巨头所垄断。
在今年 ICLR 会议上,我们被问到最多且最有意思的问题是:像 Jina AI 这样的向量搜索模型提供商,除了在 MTEB 上做基准测试,会不会做些氛围测试 (Vibe-testing)?

好家伙,AI意外生成的内核(kernel),性能比人类专家专门优化过的还要好!
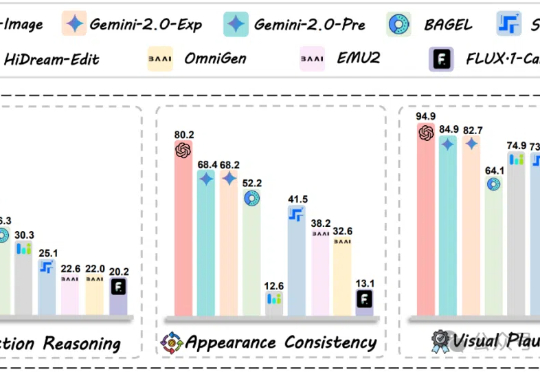
GPT-4o-Image也只能完成28.9%的任务,图像编辑评测新基准来了!360个全部由人类专家仔细思考并校对的高质量测试案例,暴露多模态模型在结合推理能力进行图像编辑时的短板。

现在,请大家一起数一下“1”、“2”。OK,短短2秒钟时间,一个准万亿MoE大模型就已经吃透如何解一道高等数学大题了!而且啊,这个大模型还是不用GPU来训练,全流程都是大写的“国产”的那种。

多模态大模型(MLLM)在静态图像上已经展现出卓越的 OCR 能力,能准确识别和理解图像中的文字内容。MME-VideoOCR 致力于系统评估并推动MLLM在视频OCR中的感知、理解和推理能力。

来和机器狗一起运动不?你的羽毛球搭子来了!无需人工协助,仅靠强化学习,机器狗子就学会了羽毛球哐哐对打。基于强化学习,研究人员开发了机器狗的全身视觉运动控制策略,同步控制腿部(18个自由度)移动,和手臂挥拍动作。

多AI智能体系统的复杂构建与优化,长期以来是用智能体解决科研问题和场景落地的瓶颈。来自英国格拉斯哥大学的研究团队发布了全球首个AI智能体自进化开源框架EvoAgentX,通过引入自我进化机制,打破了传统多智能体系统在构建和优化中的限制!
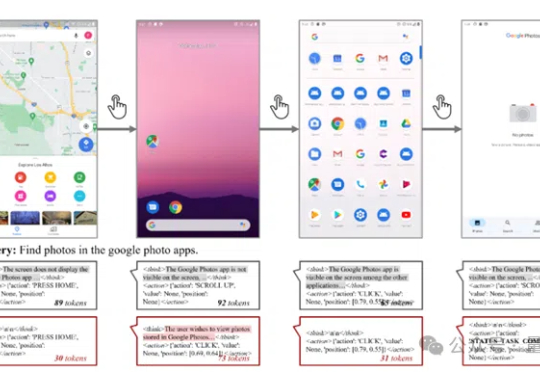
人类在面对简单提问时常常不假思索直接回答,只有遇到复杂难题才会认真推理。