航空发动机用上大模型:解决复杂时序问题,性能超越ChatGPT-4o实现SOTA|上交创智复旦
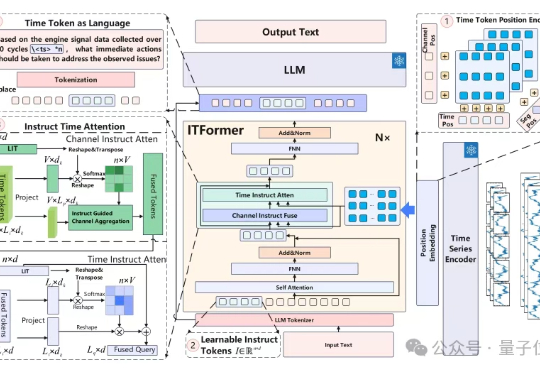
航空发动机用上大模型:解决复杂时序问题,性能超越ChatGPT-4o实现SOTA|上交创智复旦时序数据分析在工业监控、医疗诊断等领域至关重要。比如航空发动机监控这个复杂工业场景中,工程师需分析海量多通道传感器数据,以判断设备状态并制定维护决策。
来自主题: AI技术研报
8117 点击 2025-06-28 17:00
 搜索
搜索
时序数据分析在工业监控、医疗诊断等领域至关重要。比如航空发动机监控这个复杂工业场景中,工程师需分析海量多通道传感器数据,以判断设备状态并制定维护决策。
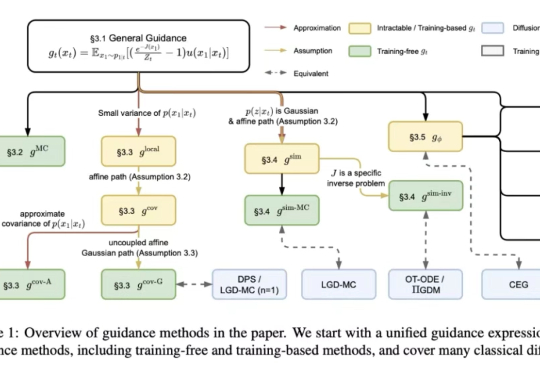
在解决离线强化学习、图片逆问题等任务中,对生成模型的能量引导(energy guidance)是一种可控的生成方法,它构造灵活,适用于各种任务,且允许无额外训练条件生成模型。同时流匹配(flow matching)框架作为一种生成模型,近期在分子生成、图片生成等领域中已经展现出巨大潜力。
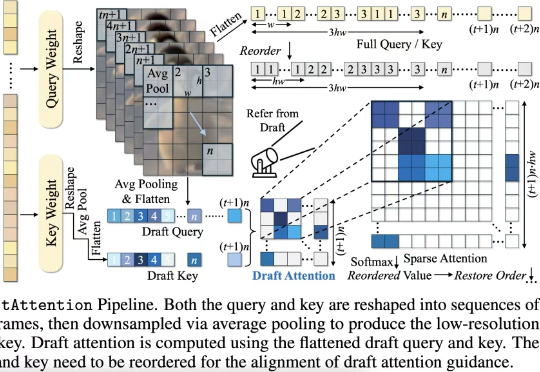
在高质量视频生成任务中,扩散模型(Diffusion Models)已经成为主流。然而,随着视频长度和分辨率的提升,Diffusion Transformer(DiT)模型中的注意力机制计算量急剧增加,成为推理效率的最大瓶颈。
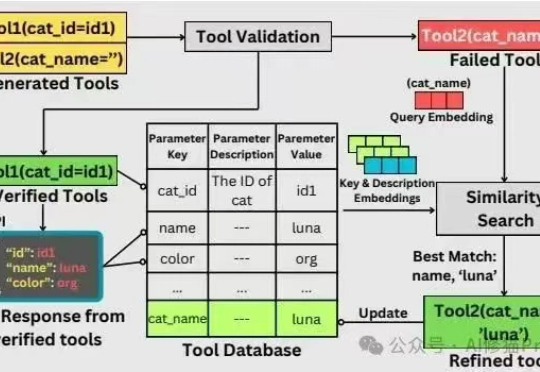
我想问您一个问题:上次为了让AI代理调用某个第三方API,您花了多长时间写包装代码?一天?三天?还是一周?不过现在,Brandeis大学的研究者们带来了一个让人眼前一亮的解决方案——Doc2Agent,它能从API文档直接生成可执行,MCP可调用的Python工具,而且成功率还挺不错。
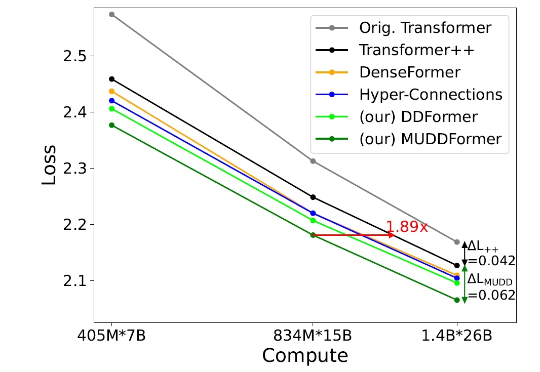
但在当今的深度 Transformer LLMs 中仍有其局限性,限制了信息在跨层间的高效传递。 彩云科技与北京邮电大学近期联合提出了一个简单有效的残差连接替代:多路动态稠密连接(MUltiway Dynamic Dense (MUDD) connection),大幅度提高了 Transformer 跨层信息传递的效率。
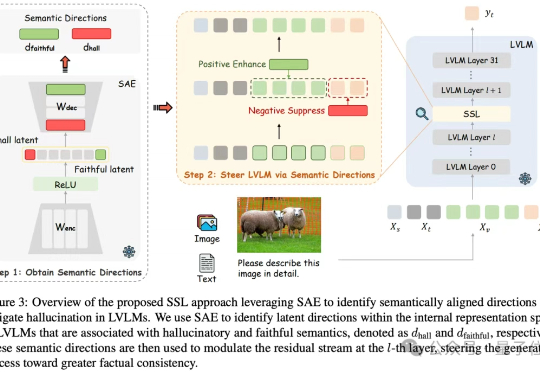
通过“视觉神经增强”机制,直接放大模型中的视觉关键注意力头输出,显著降低模型的幻觉现象。
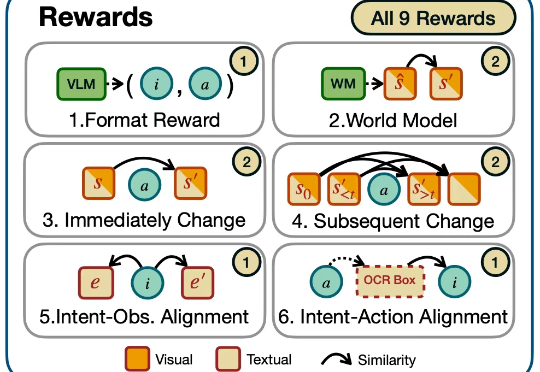
迈向通用人工智能(AGI)的核心目标之一就是打造能在开放世界中自主探索并持续交互的智能体。随着大语言模型(LLMs)和视觉语言模型(VLMs)的飞速发展,智能体已展现出令人瞩目的跨领域任务泛化能力。
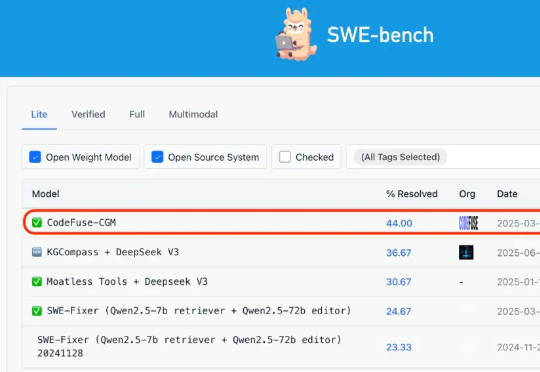
Agentless+开源模型,也能高质量完成仓库级代码修复任务,效果媲美业界 SOTA 。

当前大型视觉语言模型(LVLMs)存在物体幻觉问题,即会生成图像中不存在的物体描述。

最近,扩散语言模型(dLLM)有点火。现在,苹果也加入这片新兴的战场了。