双榜SOTA!微软ACL2026新作重新定义AI长记忆
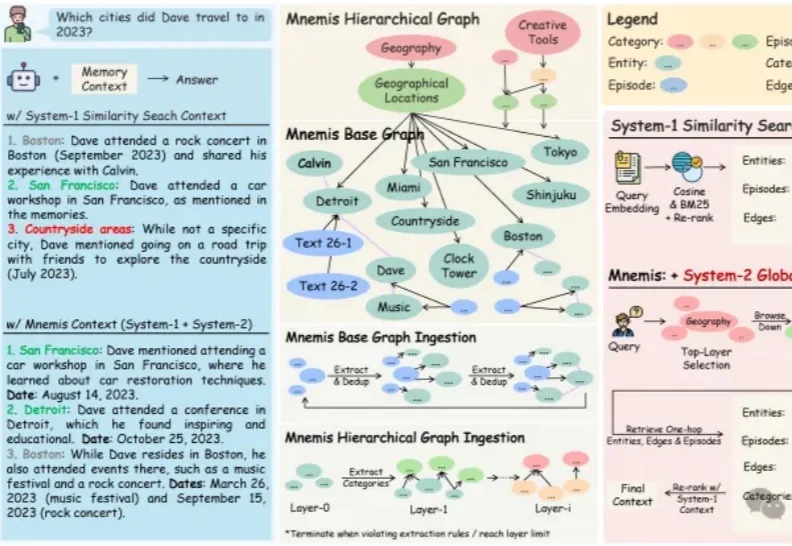
双榜SOTA!微软ACL2026新作重新定义AI长记忆随着大语言模型在各类应用中加速落地,一个核心技术瓶颈日益凸显——AI始终缺乏真正的长期记忆能力。当前主流的RAG(检索增强生成)方案依赖语义相似度检索历史信息,但“语义相似”并不等于“真正相关”,常常出现检索结果不完整、无法区分信息相关性、缺乏推理能力等问题。
来自主题: AI技术研报
9086 点击 2026-05-28 09:50
 搜索
搜索
随着大语言模型在各类应用中加速落地,一个核心技术瓶颈日益凸显——AI始终缺乏真正的长期记忆能力。当前主流的RAG(检索增强生成)方案依赖语义相似度检索历史信息,但“语义相似”并不等于“真正相关”,常常出现检索结果不完整、无法区分信息相关性、缺乏推理能力等问题。

智能体时代,如何让视觉分割更准确?

众所周知,大模型训练成本极高。
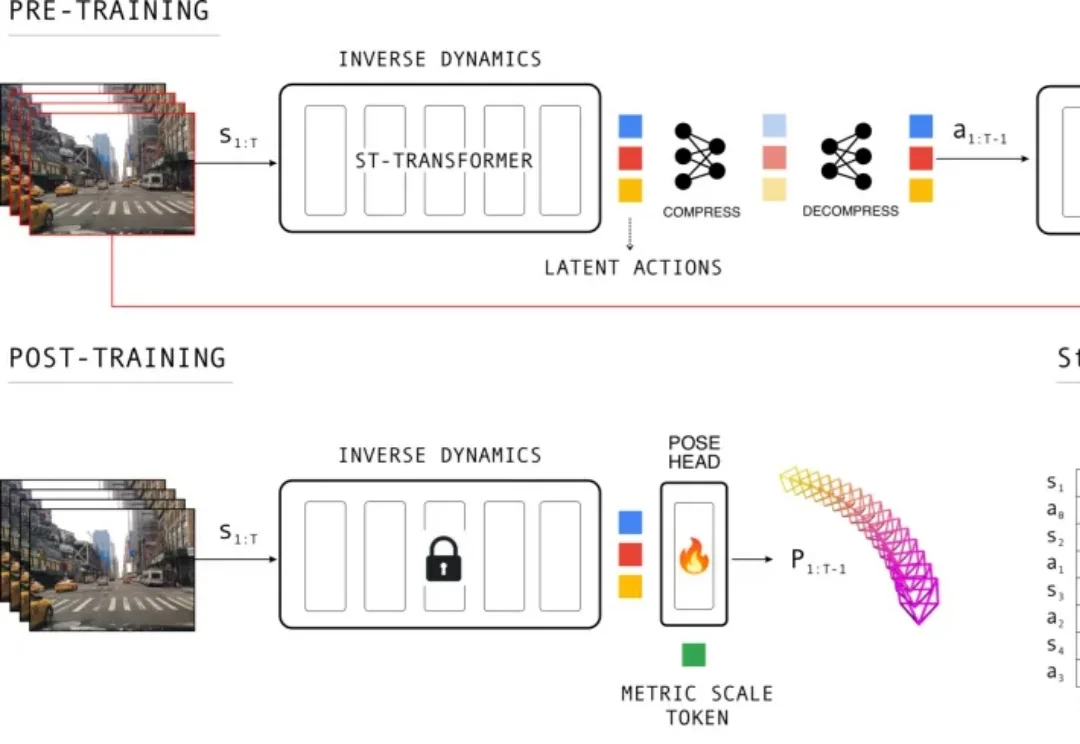
不用百万级 3D 标注,模型也能从普通驾驶视频中学会「自己是怎么动的」。Wayve 的 LA-Pose 试图把未标注视频里的运动信号,转化为自动驾驶系统所需的相机位姿估计能力。

过去几年,大模型竞争主要发生在 AI 公司之间。但随着 AI 开始从数字世界进入真实设备与物理世界,竞争逻辑正在发生变化。

多模态Agent最容易制造的一种错觉是:它看过图片,所以它记住了图片。

说在前面:这又是一篇讲Harness的Survey,你最近可能已经看过了数篇讲Harness的文章、论文,其中还可能包括我上周解读的《Agent Harness Engineering:Agent的底盘工程综述|CMU、耶鲁、Amazon》。

英伟达世界动作模型 DreamZero 训练一次要烧 8 张 H100 整整 25 天,RLinf 从算子融合到 I/O 全链路系统级重构,把训练吞吐拉高近 4 倍——1 个月的活,1 周就能干完。

造AI这件事,现在的主角变成了AI。

机器人看得见,但不一定看得准。