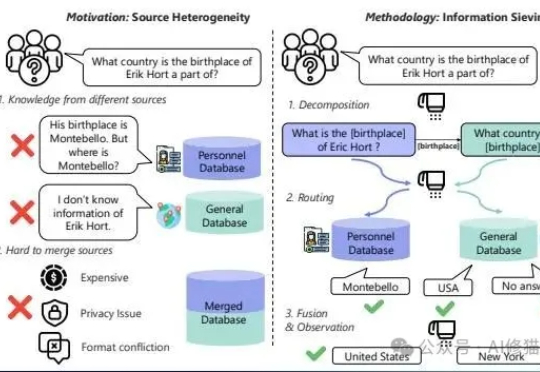
RAG也能推理思考!彻底解决多源异构知识难题
RAG也能推理思考!彻底解决多源异构知识难题现在的RAG(检索增强生成)系统。您给它一个简单直接的问题,它能答得头头是道
来自主题: AI技术研报
10028 点击 2025-08-05 15:21
 搜索
搜索
现在的RAG(检索增强生成)系统。您给它一个简单直接的问题,它能答得头头是道
AlphaStar等证明强化学习在游戏等复杂任务上,表现出色,远超职业选手!那强化学习怎么突然就不行了呢?强化学习到底是怎么走上歧路的?

除了是知名 AI 播客「No Priors」的主理人之外,Sarah Guo 更知名的身份,是风险投资 Conviction 的创始人。

OpenAI前研究员、Meta「AI梦之队员」毕书超在哥大指出:AGI就在眼前,突破需高质数据、好奇驱动探索与高效算法;Scaling Law依旧有效,规模决定智能,终身学习才是重点。
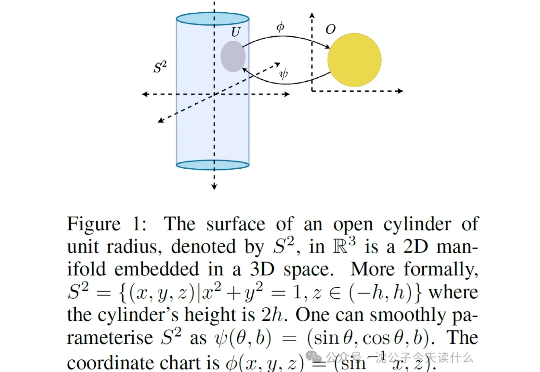
一句话概括,原来强化学习的“捷径”是天生的,智能体能去的地方(流形)被动作维度(低维流形)限制得死死的,根本没机会去那些没用的高维空间瞎逛。

在人工智能快速发展的今天,我们已逐渐习惯于让 AI 识别图像、理解语言,甚至与之对话。但当我们进入真实三维世界,如何让 AI 具备「看懂场景」、「理解空间」和「推理复杂任务」的能力?这正是 3D 视觉语言模型(3D VLM)所要解决的问题。
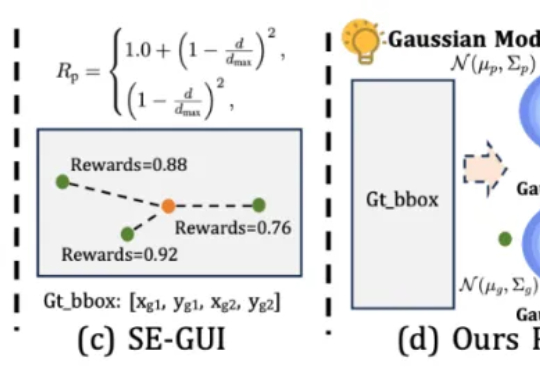
本文第一作者唐飞,浙江大学硕士生,研究方向是 GUI Agent、多模态推理等。
相信大家都有这样一个体验。 跟AI无论什么对话,感觉都是说空话套话。

提出一个真正好的猜想,比解决它更难。这是谷歌DeepMind首席执行官哈萨比斯(Demis Hassabis)在莱克斯(Lex Fridman)最新对谈中的感慨。他同时也是2024年诺贝尔化学奖的得主,带队开发出了能够高精度预测蛋白质的三维结构的AlphaFold系列模型。

不知道大家是否还记得,人工智能先驱、强化学习之父、图灵奖获得者 Richard S. Sutton,在一个多月前的演讲。 Sutton 认为,LLM 现在学习人类数据的知识已经接近极限,依靠「模仿人类」很难再有创新。