
一个CLAUDE.md霸榜GitHub第一!蒸馏自Karpathy,6万码农抄作业
一个CLAUDE.md霸榜GitHub第一!蒸馏自Karpathy,6万码农抄作业一个毫无代码的文本,竟连霸GitHub热榜第一。Karpathy的编程神技被化作「AI紧箍咒」,让乱写Bug的大模型瞬间老实!
来自主题: AI资讯
7645 点击 2026-04-21 16:16
 搜索
搜索
一个毫无代码的文本,竟连霸GitHub热榜第一。Karpathy的编程神技被化作「AI紧箍咒」,让乱写Bug的大模型瞬间老实!

在 AI 工程界,长文本推理一直是个“富贵病”。
“给我们剧透一下 M3 吧。”
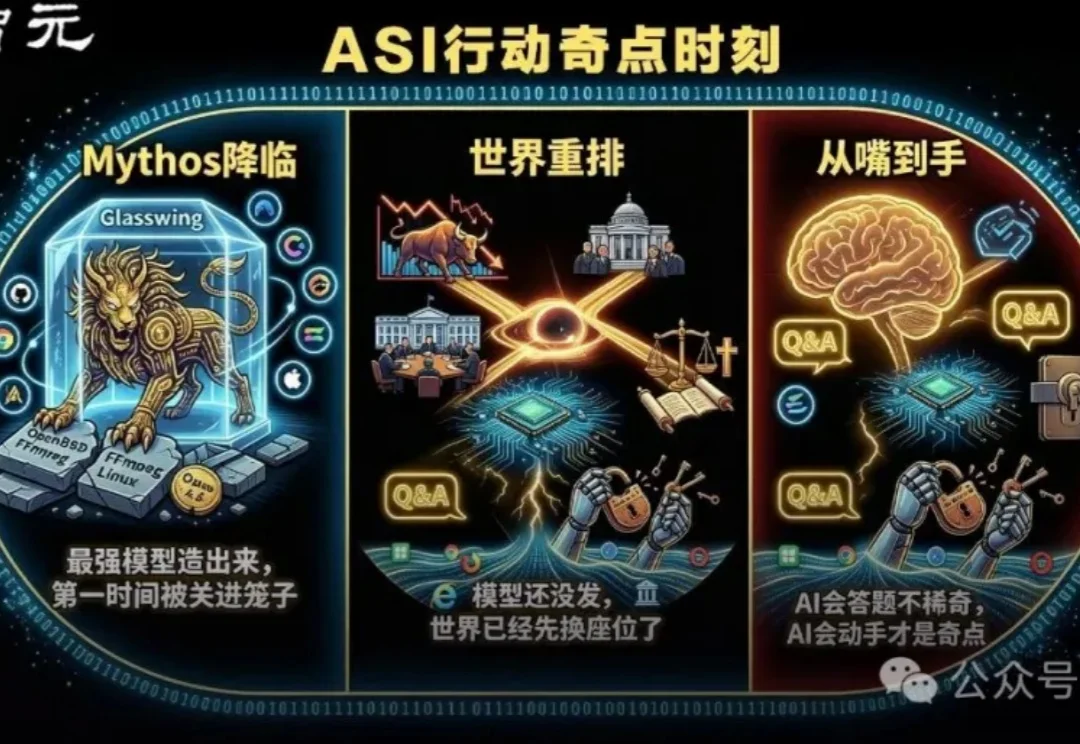
Anthropic把最强Claude Mythos亲手锁进笼子,因为它第一次让世界看清:AI正在从「会说」跨进「会做」,奇点已经不再只是想象。

看到标题《这个模型让机器人长出了嘴》,你可能会心生疑惑: AI不是早就懂语音播报了吗?

今日,亚马逊宣布将向美国AI大模型独角兽Anthropic投资50亿美元(约合人民币341亿元),未来还将根据一些商业里程碑的达成情况,追加投资至多200亿美元(约合人民币1364亿元)。

去年营收1.1亿的原生影视工作室Utopai火起来,又一次彻底刷屏!奥斯卡编剧下场背书,这家公司直接复刻了皮克斯的神话。从剧本到4K大片一键直出,AI视频刚刚完成了一次史诗级升级。

2026年初,当大多数企业还在用数据分析师手动写SQL查表时,OpenAI内部曝光的能自主思考、推理甚至自我进化的数据分析智能体,将数据查询从「天数级」缩短至「分钟级」。

今年4月,具身智能领域发生了一件看起来不大、但意味深长的事。

当谈及数学时,我们近乎本能地认为,数学是一个严谨、精确、不容置疑的完美逻辑体系,但在菲尔兹奖得主迈克尔・弗里德曼(Michael Freedman)眼中,人类真正创造和关心的数学,本质上是「柔软且可塑」的。