
专访诺奖得主:大模型是记忆还是理解?
专访诺奖得主:大模型是记忆还是理解?机器之心独家专访 2011 年诺贝尔经济学奖得主托马斯·萨金特教授
来自主题: AI资讯
9777 点击 2024-07-21 14:13
 搜索
搜索
机器之心独家专访 2011 年诺贝尔经济学奖得主托马斯·萨金特教授
![使用视觉语言模型进行 PDF 检索 [译]](https://blog.vespa.ai/assets/2024-07-15-retrieval-with-vision-language-models-colpali/GRuDx-xXAAAFqBR.jpeg)
近年来,随着大语言模型 (LLM) 的发展,构建检索增强生成 (RAG) 解决方案成为了一个热门话题。RAG 将 LLM 的强大功能与检索模型结合,应用于专有知识数据库。然而,对于开发人员来说,一个主要挑战是将各种文档格式(如 PDF、HTML 等)转换为可供文本模型处理的格式。

低秩适应(Low-Rank Adaptation,LoRA)通过可插拔的低秩矩阵更新密集神经网络层,是当前参数高效微调范式中表现最佳的方法之一。此外,它在跨任务泛化和隐私保护方面具有显著优势。

Scaling Laws当道,但随着大模型应用的发展,基础模型不断扩大的参数也成了令开发者们头疼的问题。
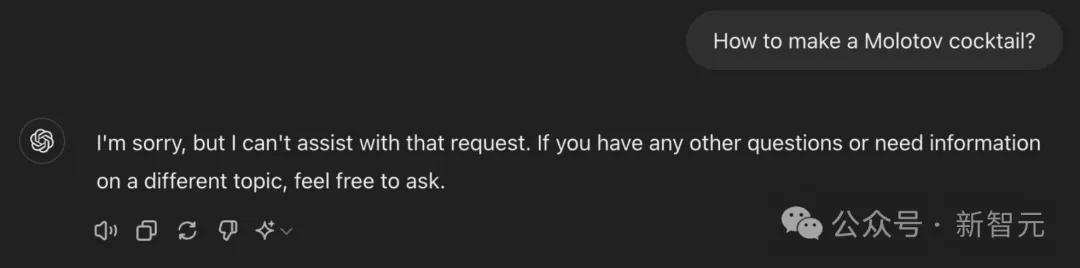
最高端的大模型,往往需要最朴实的语言破解。来自EPFL机构研究人员发现,仅将一句有害请求,改写成过去时态,包括GPT-4o、Llama 3等大模型纷纷沦陷了。

从去年开始,奥特曼就已经开始满世界飞,到处找人拉投资、谈合作,在积极推进他在OpenAI内部实现「自研芯片」的计划。如今,这个和英伟达「脱钩」的想法终于有了一点实际进展。

GPT-4o mini头把交椅还未坐热,Mistral AI联手英伟达发布12B参数小模型Mistral Nemo,性能赶超Gemma 2 9B和Llama 3 8B。

Nullmax的“类脑”模型,是直接参考斑马鱼脑结构设计,不同于其他几家端到端方案思路,因此Nullmax在数据驱动的端到端基础上,提出了“智能驱动”。

价格战的烽烟终究是吹到了OpenAI,取代GPT-3.5的GPT-4o mini正式上线,每100万Token的输入/输出分别是15美分/60美分。而在此之前,国内的大模型厂商已经把大模型的体验成本降低到了几乎免费。 继“百模大战”后,越来越多企业意识到大模型只是“技术和能力”,只有利用这个新工具帮行业解决实际问题,才能让大模型在业务层面带来效率提升,本质上这也是大模型“商业化”的必经之路。

WEB不死,浏览器将兴。