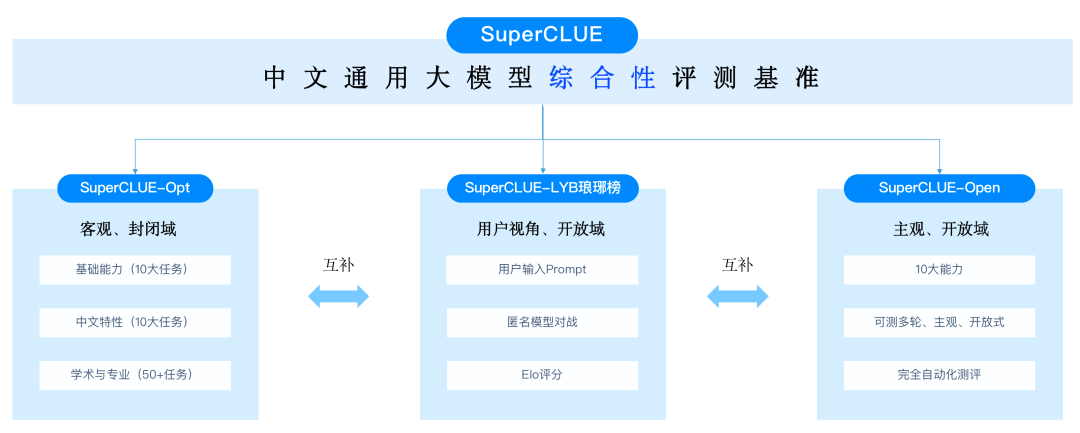
大模型常用评测基准汇总
大模型常用评测基准汇总基于评测维度,考虑到各评测集关注的评测维度,可以将其划分为通用评测基准和具体评测基准。
来自主题: AI资讯
14260 点击 2024-07-23 19:24
 搜索
搜索
基于评测维度,考虑到各评测集关注的评测维度,可以将其划分为通用评测基准和具体评测基准。

近年,短视频生态的赛道迅猛崛起,围绕短视频而生的创作编辑工具在不断涌现,美图公司旗下专业手机视频编辑工具 ——Wink,凭借独创的视频画质修复能力独占鳌头,海内外用户量持续攀升。

近日,MIT CSAIL 的一个研究团队(一作为 MIT 在读博士陈博远)成功地将全序列扩散模型与下一 token 模型的强大能力统合到了一起,提出了一种训练和采样范式:Diffusion Forcing(DF)。
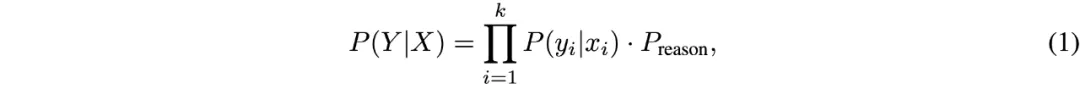
随着人工智能技术的快速发展,能够处理多种模态信息的多模态大模型(LMMs)逐渐成为研究的热点。通过整合不同模态的信息,LMMs 展现出一定的推理和理解能力,在诸如视觉问答、图像生成、跨模态检索等任务中表现出色。

这是人类首次证明神经网络可以创建自己的地图。

Llama 3.1 终于现身了,不过出处却不是 Meta 官方。

当今的LLM已经号称能够支持百万级别的上下文长度,这对于模型的能力来说,意义重大。但近日的两项独立研究表明,它们可能只是在吹牛,LLM实际上并不能理解这么长的内容。

谷歌提出了一种新的基于ML的大气环流模型NeuralGCM,比传统的基于物理的模型节省了几个数量级的计算量,计算成本降低了10万倍,相当于高性能计算领域25年的进步速度。对于2-15天的天气预报,这种方法比SOTA物理模型还要准确。
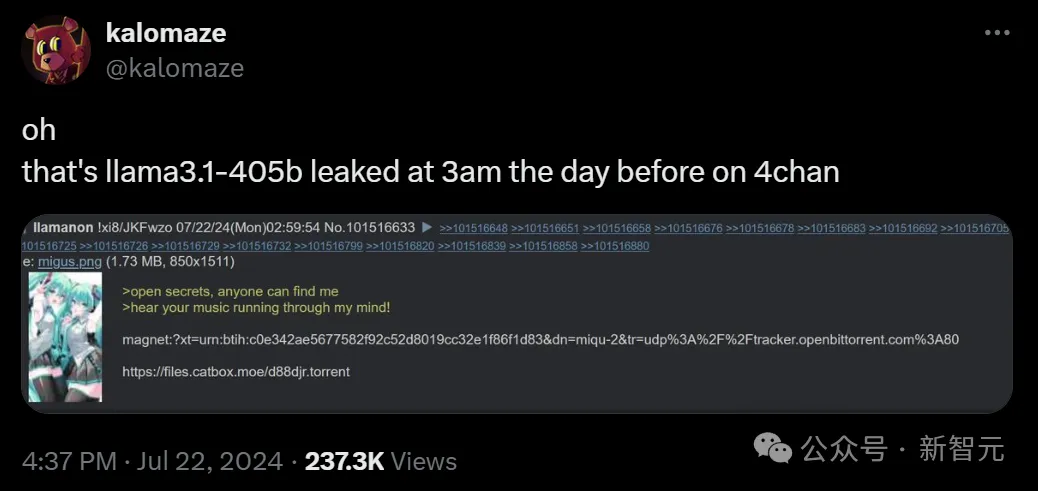
Llama 3.1又被提前泄露了!开发者社区再次陷入狂欢:最大模型是405B,8B和70B模型也同时升级,模型大小约820GB。基准测试结果惊人,磁力链全网疯转。

大模型技术席卷全球科技界,中国也迅速跟进这一浪潮,在诸多领域开始落地,提升了企业运营效率和消费者体验。然而,大模型企业也面临技术成熟度、成本、数据安全、行业差异、用户接受度等挑战,商业化仍然是一个摆在所有厂商面前的问题。