
ChatGPT「秘方」竟在拖LLM后腿?Karpathy、LeCun联手开怼RLHF!
ChatGPT「秘方」竟在拖LLM后腿?Karpathy、LeCun联手开怼RLHF!RLHF到底是不是强化学习?最近,AI大佬圈因为这个讨论炸锅了。和LeCun同为质疑派的Karpathy表示:比起那种让AlphaGo在围棋中击败人类的强化学习,RLHF还差得远呢。
来自主题: AI资讯
8061 点击 2024-08-10 10:32
 搜索
搜索
RLHF到底是不是强化学习?最近,AI大佬圈因为这个讨论炸锅了。和LeCun同为质疑派的Karpathy表示:比起那种让AlphaGo在围棋中击败人类的强化学习,RLHF还差得远呢。

假如你目前正在使用和研究类似CAMEL的多智能体系统,现在已经有了扮演研究者的Agent和负责写论文的Agent,再添加一个事实核查Agent会改善结果吗?
前段时间冲上热搜的问题「9.11比9.9大吗?」,让几乎所有LLM集体翻车。看似热度已过,但AI界大佬Andrej Karpathy却从中看出了当前大模型技术的本质缺陷,以及未来的潜在改进方向。

有CPU就能跑大模型,性能甚至超过NPU/GPU!

用光训练神经网络,清华成果最新登上了Nature!
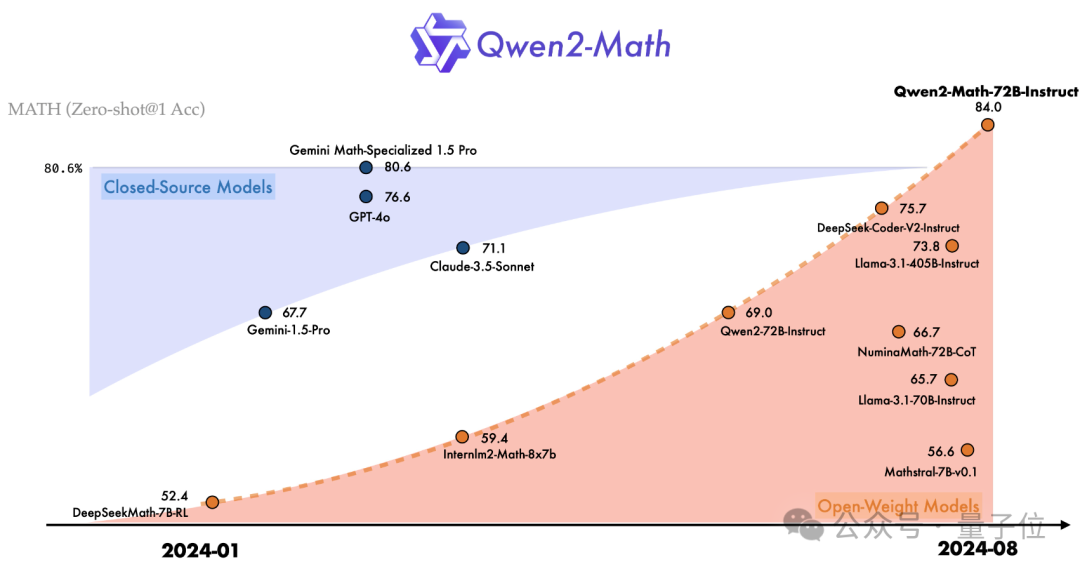
最强数学大模型,现在易主!

GPT-4o的怪癖暴露了,还是被官方公开的!

GPT-5 大模型?不要太着急。

RLHF 与 RL 到底能不能归属为一类,看来大家还是有不一样的看法。

但可能打不过公园里的老大爷?