
当奖励成为漏洞:从对齐本质出发自动「越狱」大语言模型
当奖励成为漏洞:从对齐本质出发自动「越狱」大语言模型本文第一作者为香港大学博士研究生谢知晖,主要研究兴趣为大模型对齐与强化学习。
来自主题: AI技术研报
7938 点击 2024-08-31 15:09
 搜索
搜索
本文第一作者为香港大学博士研究生谢知晖,主要研究兴趣为大模型对齐与强化学习。

Transformer 在深度学习领域取得巨大成功的关键是注意力机制。注意力机制让基于 Transformer 的模型关注与输入序列相关的部分,实现了更好的上下文理解。然而,注意力机制的缺点是计算开销大,会随输入规模而二次增长,Transformer 也因此难以处理非常长的文本。

8月28日至30日,2024中国国际大数据产业博览会正在贵阳火热进行中。“产业链上下游的人都来了。”一位行业人士观察,与以往不同,这届数博会上,数据要素、智算基础设施建设,正在和智能化、大模型行业应用等一起成为被密集讨论的话题。

大模型带动生成式AI爆发后,对算力的高需求让芯片巨头英伟达的订单量、收入、股价一路走高,而国内芯片厂商却一直处于蛰伏状态。
从几周前 Sam Altman 在 X 上发布草莓照片开始,整个行业都在期待 OpenAI 发布新模型。根据 The information 的报道,Strawberry 就是之前的 Q-star,其合成数据的方法会大幅提升 LLM 的智能推理能力,尤其体现在数学解题、解字谜、代码生成等复杂推理任务。这个方法也会用在 GPT 系列的提升上,帮助 OpenAI 新一代 Orion。

在与 GPT-4o 的全面较量中,GLM-4-Plus 已经可以在大多数任务上做到逼近甚至在某些任务上实现了超越。还有 One More Thing:清言上线了视频通话功能,首批面向部分用户开放。
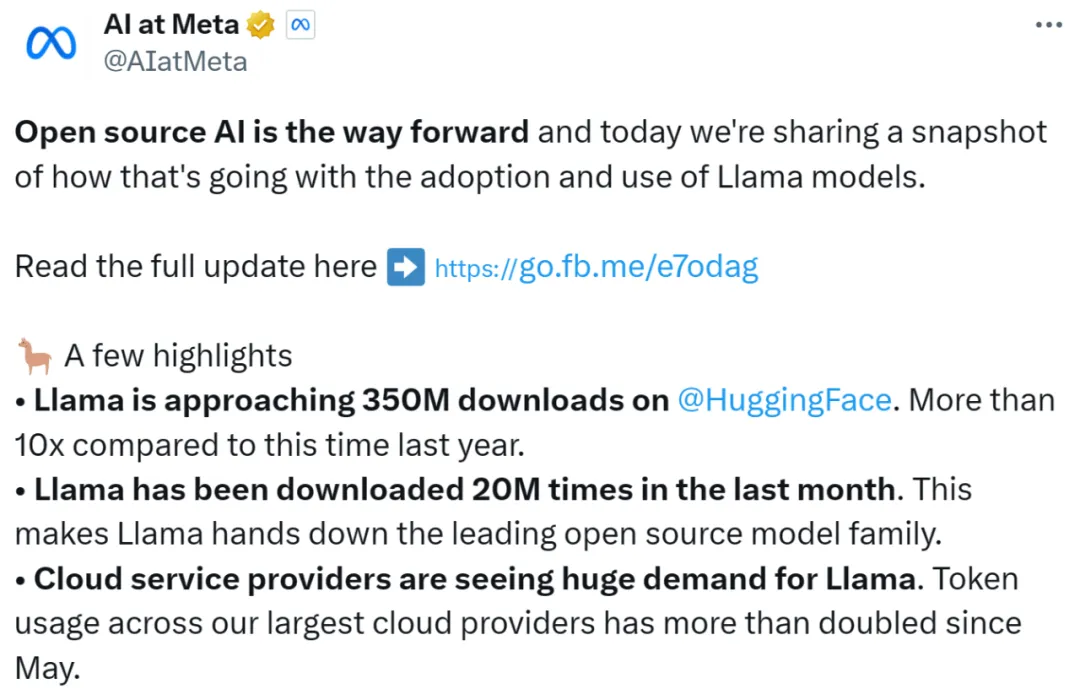
今天一大早,Meta 便秀了一把「Llama 系列模型在开源领域取得的成绩」,包括如下:

罗盟,本工作的第一作者。新加坡国立大学(NUS)人工智能专业准博士生,本科毕业于武汉大学。主要研究方向为多模态大语言模型和 Social AI、Human-eccentric AI。

当前的大型语言模型似乎能够通过一些公开的图灵测试。我们该如何衡量它们是否像人一样聪明呢?

在人工智能重塑各个行业的今天,法律界也迎来了前所未有的变革。传统的法律实践面临着效率低下、成本高昂等挑战,而AI技术的出现为解决这些问题提供了新的可能。