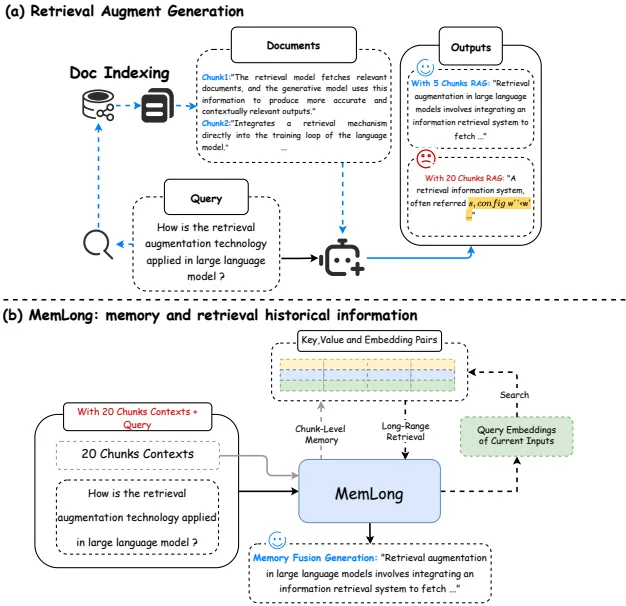
MemLong: 长文本的新记忆大师,可将上下文长度从4k提升到80k!
MemLong: 长文本的新记忆大师,可将上下文长度从4k提升到80k!这篇文章介绍了一个名为MemLong的模型,它通过使用外部检索器来增强长文本建模的能力。
来自主题: AI技术研报
8623 点击 2024-09-05 16:33
 搜索
搜索
这篇文章介绍了一个名为MemLong的模型,它通过使用外部检索器来增强长文本建模的能力。

这篇文章是笔者之前AI手写连笔书法生成的一个工作,是联合中央美院几位非常知名的老师完成的。当时提出的思路相对简单,主要结构是基于对抗生成网络(GAN)。虽然方法在大模型横行今天可能已经不算太新颖,但近期一些基于diffusion的AIGC工作还是关注到了这篇文章,并产生了一些启发。笔者认为这些灵感仍具有一定价值,因此在这里做个分享。由于一些公式和指标不太友好,为了不影响阅读故省略。

近日,Mamba方面又搞出了有意思的研究:来自康奈尔、普林斯顿等机构的研究人员成功将Llama提炼成了Mamba模型,并且设计了新的推测解码算法,加速了模型的推理。

在21世纪的科技洪流中,人工智能(AI)正以前所未有的速度重塑着世界的每一个角落,从医疗、教育到金融、制造,无一不感受到其强大的影响力。然而,当我们将目光投向看似与AI技术相去甚远的能源领域,尤其是石油行业时,一场由AI驱动的变革似乎正悄然酝酿。

PPIO推出新AI产品,助力分布式云计算及AIGC应用。

AI有情商吗?
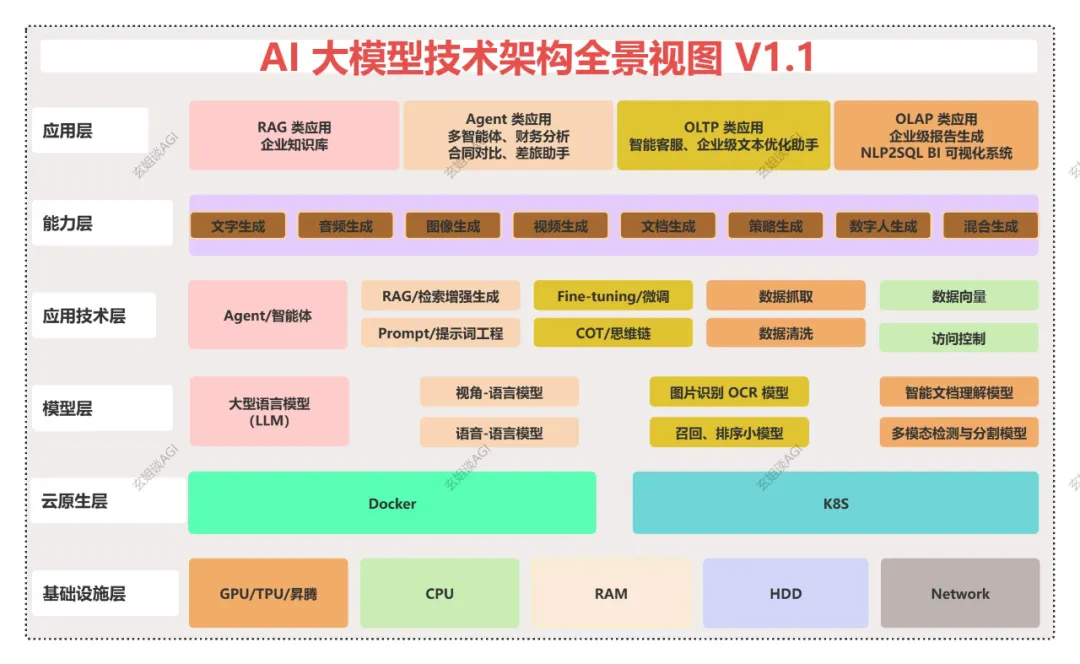
AI 大模型已经在具体的业务场景落地实践,本文通过梳理 AI 大模型技术架构的全景视图,让你全面了解 AI 大模型技术的各个层次,从基础实施层、云原生层、模型层、应用技术层、能力层、到应用层,如下图所示,揭示 AI 大模型如何在不同的层面上协同工作,推动产业应用的落地。

AI大模型公司近来狂被唱衰,那反过来看呢,实际上呢?
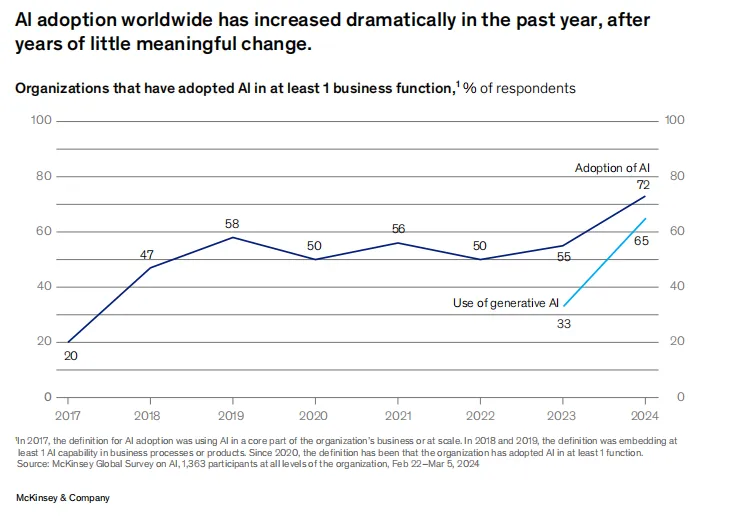
企业要用好 LLM 离不开高质量数据。和传统机器学习模型相比,LLM 对于数据需求量更大、要求更高,尤其是非结构化数据。而传统 ETL 工具并不擅长非结构化数据的处理,因此,企业在部署 LLM 的过程中,数据科学家们往往要耗费大量的时间精力在数据处理环节。这一环节既关系到 LLM 部署的效率和质量,也对数据科学家人力的 ROI 产生影响。
Flux 带起又一波文生图模型的热潮,NightCafe 是其中的受益者之一。