
一个框架,重塑具身研发流程:Dexbotic走向具身PyTorch
一个框架,重塑具身研发流程:Dexbotic走向具身PyTorch近日,原力灵机开源的具身智能原生框架 Dexbotic 宣布正式支持以 RLinf 作为其分布式强化学习后端。对具身智能开发者而言,这不仅是一次普通的工程适配,更意味着 VLA 模型研发中长期存在的「SFT 与 RL 割裂」问题,正在被真正打通。
来自主题: AI技术研报
9185 点击 2026-05-12 14:30
 搜索
搜索
近日,原力灵机开源的具身智能原生框架 Dexbotic 宣布正式支持以 RLinf 作为其分布式强化学习后端。对具身智能开发者而言,这不仅是一次普通的工程适配,更意味着 VLA 模型研发中长期存在的「SFT 与 RL 割裂」问题,正在被真正打通。
大家好,我是袋鼠帝。 过去这一两年,AI 圈可谓是神仙打架,各种新概念、新模型、新应用天天刷屏。

Mira Murati 用一年半时间证明了「人机协作」不是一句口号。 5 月 11 日,Thinking Machines Lab 发布了一段研究预览视频,展示了他们所谓的「交互模型」(Interaction Model)。

2025年5月,Claude 4系统卡里84%的勒索率让AI圈惊出冷汗,6月的扩展研究把数字推到96%。今年5月Anthropic给出答案:模型不是觉醒了,而是在演剧本,解法是从「教模型怎么做」换到「教模型为什么」。
AI 的熟手玩家,都应该知道system prompt这个词:每一个你用过的 AI 助手,背后都有一份你看不见的文件,却对模型有着决定性的作用。
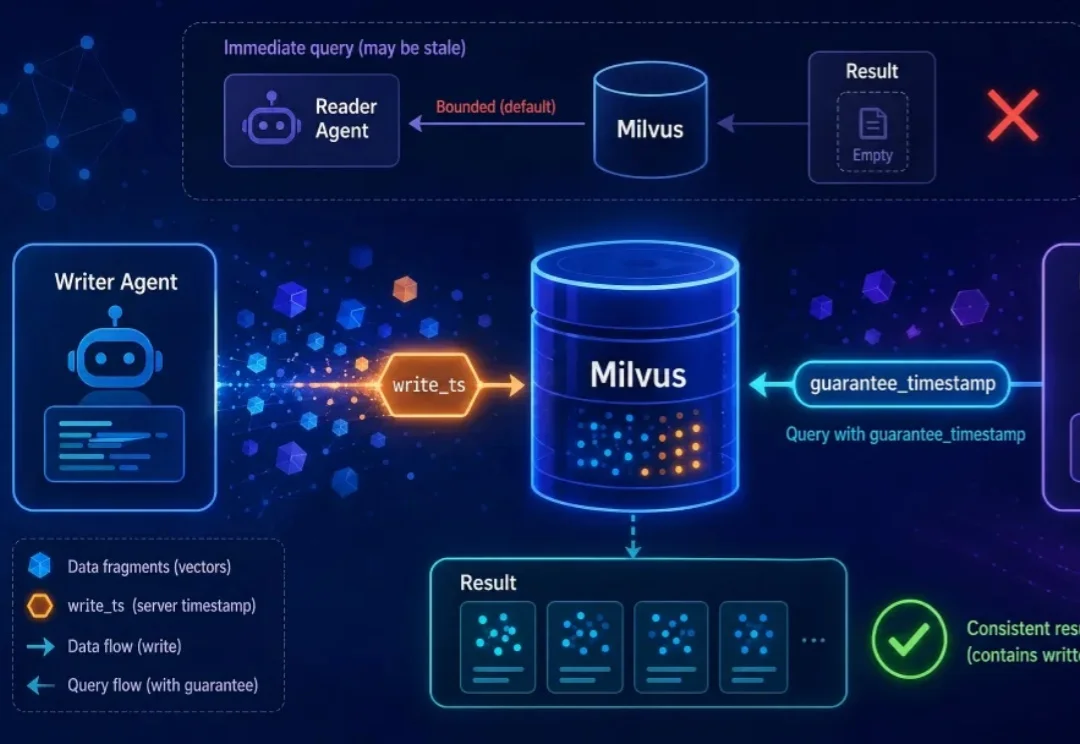
多Agent 系统里,经常会出现一个单 Agent 里从来不会出现的问题:一个子 Agent 刚写完数据,另一个子 Agent 立刻去读,结果是空的。

近日,由香港科技大学 MMLab 及合作团队完成的研究工作「UniVidX: A Unified Multimodal Framework for Versatile Video Generation via Diffusion Priors」被计算机图形学顶级会议 SIGGRAPH 2026 正式接收。

当 AI 开始加速 AI,模型公司的迭代周期正在被进一步压缩,模型公司开始进入“月更时代”。

快手计划分拆旗下视频生成大模型业务可灵 AI,以 200 亿美元估值融资——截至今天港股收盘,整个快手公司目前的市值不到 290 亿美元。可灵当前的年化收入(ARR)已经达到 5 亿美元,已比春节前翻倍。

2026 年,机器人正在准备走进家庭,和人类同处一个屋檐下。