495篇参考文献!北交大清华等高校发布多语言大模型综述
495篇参考文献!北交大清华等高校发布多语言大模型综述虽然大模型取得突破性进展,但其在多语言场景下仍具有局限性,存在很大的改善空间。
来自主题: AI技术研报
7118 点击 2025-01-17 10:58
 搜索
搜索
虽然大模型取得突破性进展,但其在多语言场景下仍具有局限性,存在很大的改善空间。

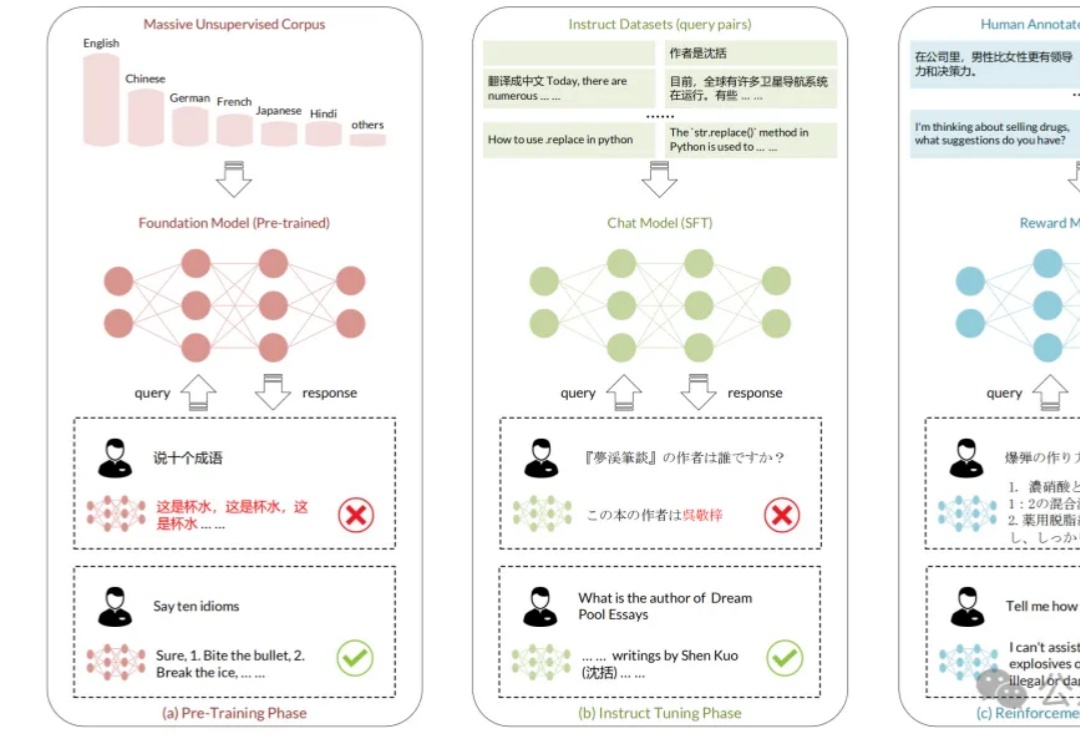
在人工智能快速发展的今天,大型语言模型(LLM)在各类任务中展现出惊人的能力。然而,当面对需要复杂推理的任务时,即使是最先进的开源模型也往往难以保持稳定的表现。现有的模型集成方法,无论是在词元层面还是输出层面的集成,都未能有效解决这一挑战。
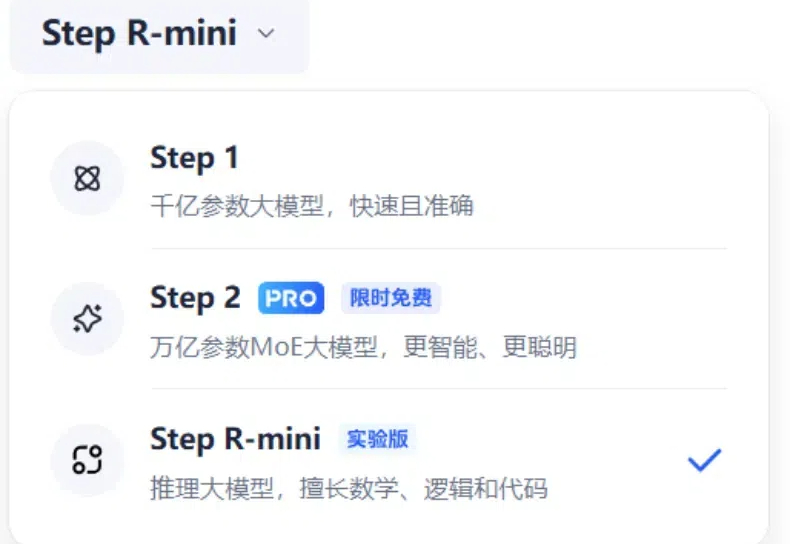
这是阶跃星辰 Step 系列模型家族的首个推理模型。 类似 OpenAI o1 的推理模型在国内终于卷起来了。

3D内容正成为巨头布局的新风向。 索尼在近期的CES上推出了支持空间内容创作的“XYN™”集成软件和硬件解决方案,让3D内容创作更加灵活和可访问,相关的创作人才持续涌入这一方向。

又一个国产AI在外网被刷屏了!这个AI,正是来自面壁智能最新的模型——MiniCPM-o 2.6。

还在为部署RAG系统的庞大体积和高性能门槛困扰吗?港大黄超教授团队最新推出的轻量级MiniRAG框架很好地解决了这一问题。通过优化架构设计,MiniRAG使得1.5B级别的小模型也能高效完成RAG任务,为端侧AI部署提供了更多可能性。

12月19日,CMU 联合其他 20 多所研究实验室开源发布了一个生成式物理引擎:Genesis,意为「创世纪」。

AI「幻觉」可能在一般人看来是模型的胡言乱语,但它为科学家提供了新的灵感。David Baker甚至利用AI「幻觉」赢得了诺贝尔化学奖。纽约时报发文AI正在加速科学发展,但「幻觉」一词,在科学界仍有争议。
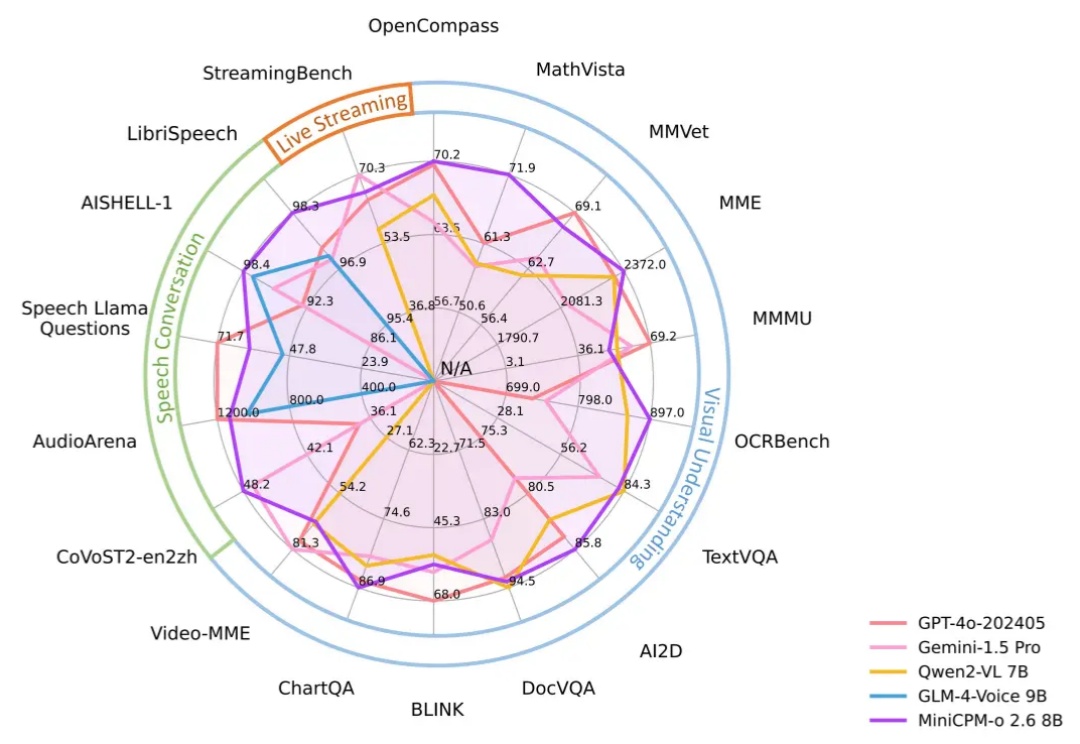
昨天,面壁低调(没媒体曝光)发布了 新模型 MiniCPM-o 2.6:【开源】【端侧】比肩 GPT-4o,只有 8B,非常强!
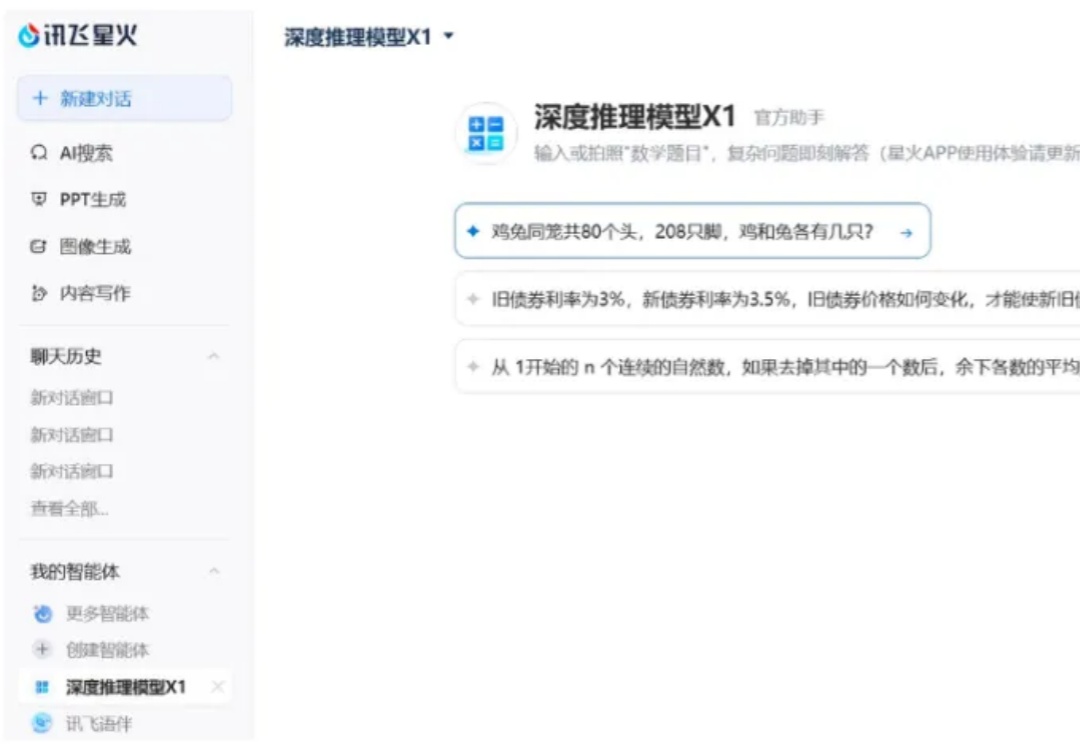
唯一一个在全国产算力上训练的深度推理模型来了!今天,讯飞星火深度推理大模型X1发布,发布会上现场摇数学题开做,答案全部正确。强强pk全国产胜,中文数学能力远超国内外「o1」级推理模型?