Nature认证DeepSeek成科研工具全能者,国内高校如何借力大模型?
Nature认证DeepSeek成科研工具全能者,国内高校如何借力大模型?DeepSeek的风,也是飘到了科研领域——
来自主题: AI资讯
8625 点击 2025-02-20 17:31
 搜索
搜索
DeepSeek的风,也是飘到了科研领域——

在当今的 AI 领域,图灵奖得主 Yann LeCun 算是一个另类。即便眼见着自回归 LLM 的能力越来越强大,能解决的任务也越来越多,他也依然坚持自己的看法:自回归 LLM 没有光明的未来。

数字化时代,视频内容的创作与编辑需求日益增长。从电影制作到社交媒体,高质量的视频编辑技术成为了行业的核心竞争力之一。然而,视频重打光(video relighting)—— 即对视频中的光照条件进行调整和优化,一直是这一领域的技术瓶颈。传统的视频重打光方法面临着高昂的训练成本和数据稀缺的双重挑战,导致其难以广泛应用。

据 The Information 报道,Field AI 是一家成立两年的初创公司,专注于开发人工智能模型以驱动机器人,正在洽谈以 20 亿美元的估值筹集数亿美元资金。这将使该初创公司的估值比去年夏天翻四倍,当时包括 Nvidia 在内的投资者将其估值为 5 亿美元。
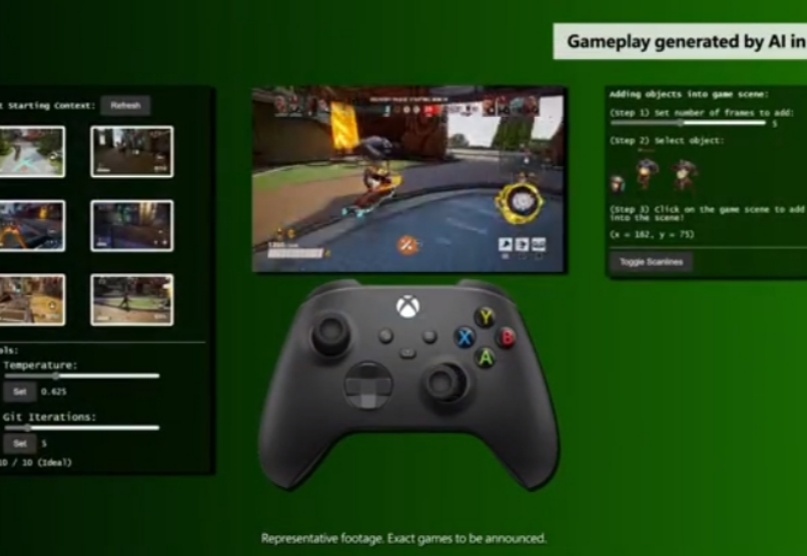
微软研究院创建了 Muse,这是首个能够根据视觉或玩家控制器动作生成游戏环境的生成性 AI 模型。它理解 3D 游戏世界和游戏物理,并能够对玩家与游戏的互动做出反应。
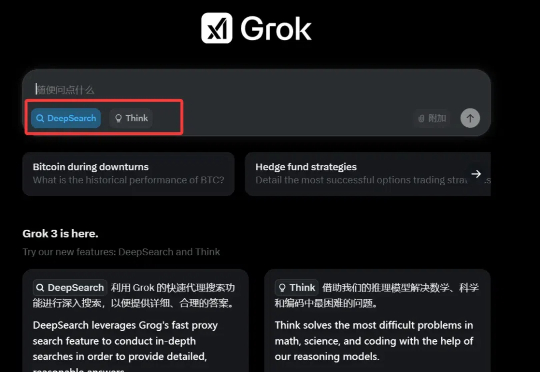
又是一个文理兼修的优等生,能薅一点是一点。堆了 20 万张 GPU、号称「地表最强」大模型 Grok-3 已经可用啦。「 Grok 3 + Thinking 感觉与 OpenAI 最强商用模型(o1-pro,200 美元/月)的顶尖水平相差无几,
仅需简单提示,满血版DeepSeek-R1美国数学邀请赛AIME分数再提高。

MatChat AI Agent集聚了中国科学院顶尖研究力量,旨在打造一个具有国际影响力的材料科学知识服务平台,为科研、教育及工业界提供权威、高效的学术支持和咨询服务。MatChat AI Agent的推出标志着自然科学的垂类模型时代到来,其精准性与规范性有望成为全球材料科学工作者的重要工具。
有人预料到DeepSeek能引爆全球吗?至少,DeepSeek-V3发布前,在大模型战场前线“卖铲子”的袁进辉心里也是打鼓的。

“一群10后在巨人《太空杀》里被AI仿生人折磨得死去活来”,有网友吐槽这是行为艺术。“网易《逆水寒》手游组了个AI NPC女团”,有网友认为《逆水寒》没活了。