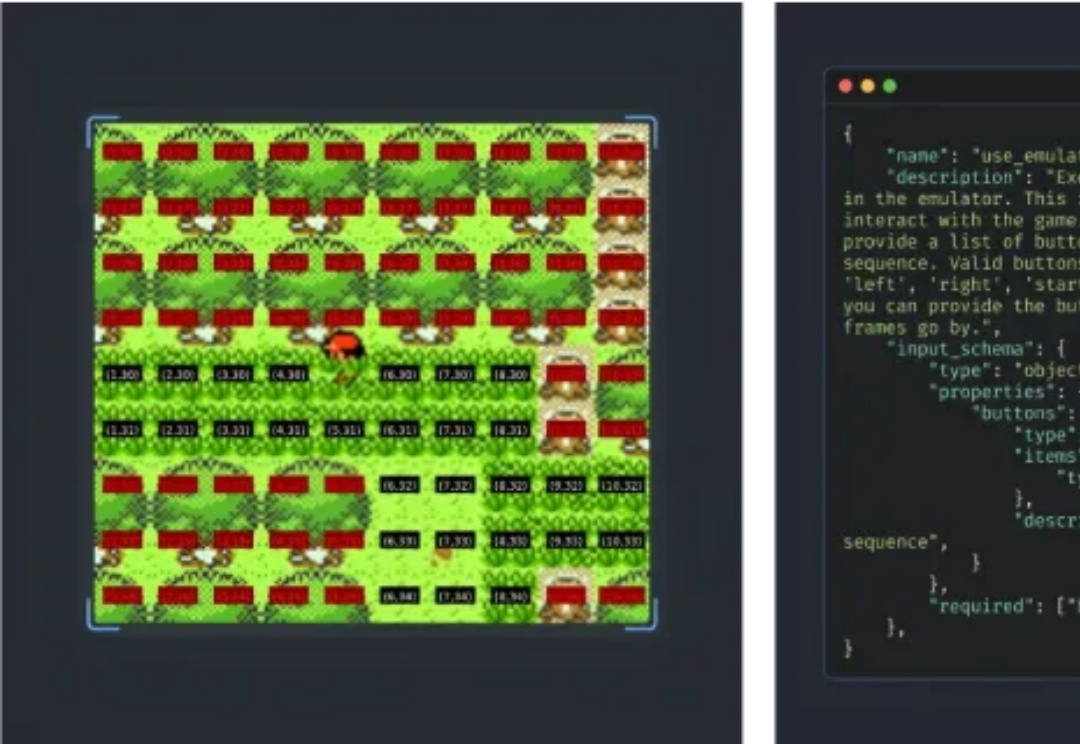
Claude玩宝可梦,卡关就「装死」重启,大模型:逃避可耻但有用
Claude玩宝可梦,卡关就「装死」重启,大模型:逃避可耻但有用半个月前,Anthropic 发布了其迄今为止最聪明的 AI 模型 —— Claude 3.7 Sonnet。
来自主题: AI技术研报
8518 点击 2025-03-09 13:46
 搜索
搜索
半个月前,Anthropic 发布了其迄今为止最聪明的 AI 模型 —— Claude 3.7 Sonnet。
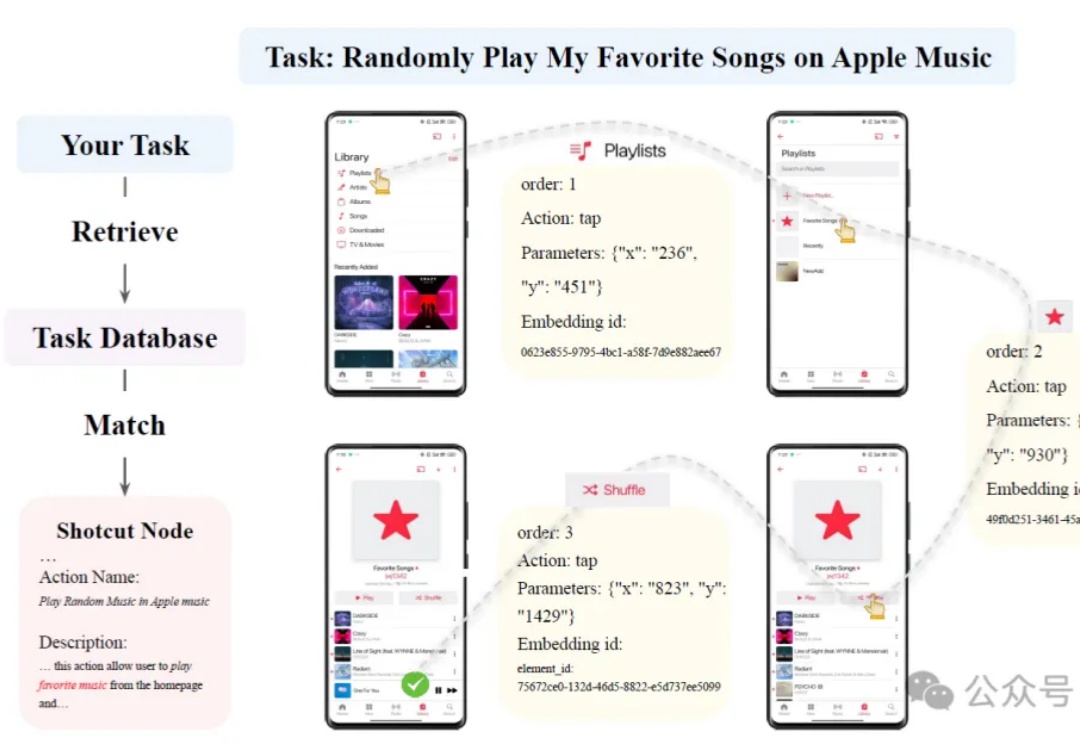
人工智能正迎来前所未有的变革,其中,大语言模型(LLM)的崛起推动了智能系统从信息处理向自主交互迈进。

在面对复杂的推理任务时,SFT往往让大模型显得力不从心。最近,CMU等机构的华人团队提出了「批判性微调」(CFT)方法,仅在 50K 样本上训练,就在大多数基准测试中优于使用超过200万个样本的强化学习方法。
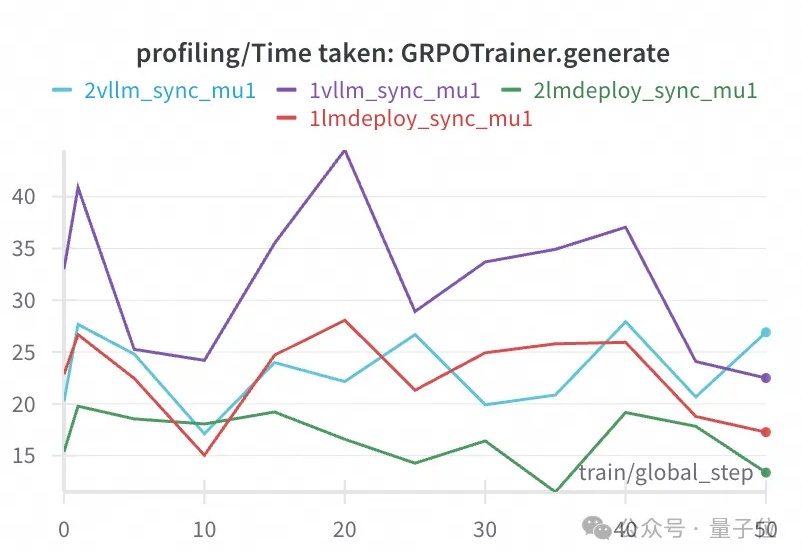
GRPO训练又有新的工具链可以用,这次来自于ModelScope魔搭社区。

DeepSeek-R1 等模型通过展示思维链(CoT)让用户一窥大模型的「思考过程」,然而,模型展示的思考过程真的代表了模型的内在推理机制吗?在医疗诊断、自动驾驶、法律判决等高风险领域,我们能否真正信任 AI 的决策?

思维链引发的战争。
大家好,很高兴在这里向各位介绍我们的产品 Free QWQ。这是世界上第一个完全免费、无限制、无需注册登录的分布式 AI 算力平台,基于 QwQ 32B 大语言模型提供强大的 AI 服务。

从今天这个视角来看,DeepSeek 等国内外大模型能力是越来越强大了,大家都说 2025 年 AI 应用还会持续爆发。但对于企业来说,有了大模型,那场景都有啥,应用又长啥样?

中国互联网公司正集体迎来资产重估,科技是最根本的推力。最近一家强调科技的巨头是美团。

起猛了,DeepSeek开口说话了。而且是超低延迟实时秒回,还可以随时打断的那种,先来看一段VCR:DeepSeek以及其他任意大模型接入这样的高质量对话引擎,全程只需要两行代码。