长文本向量模型在4K Tokens 之外形同盲区?
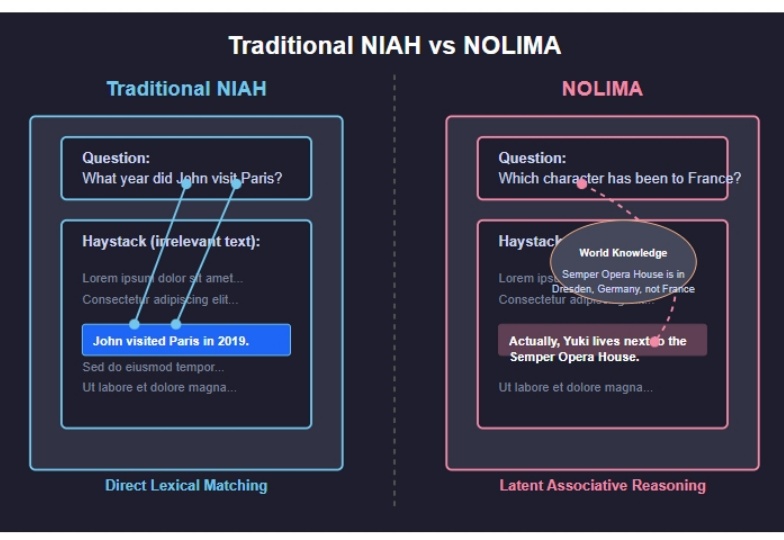
长文本向量模型在4K Tokens 之外形同盲区?2025 年 2 月发布的 NoLiMA 是一种大语言模型(LLM)长文本理解能力评估方法。不同于传统“大海捞针”(Needle-in-a-Haystack, NIAH)测试依赖关键词匹配的做法,它最大的特点是 通过精心设计问题和关键信息,迫使模型进行深层语义理解和推理,才能从长文本中找到答案。
来自主题: AI技术研报
6413 点击 2025-03-12 15:08
 搜索
搜索
2025 年 2 月发布的 NoLiMA 是一种大语言模型(LLM)长文本理解能力评估方法。不同于传统“大海捞针”(Needle-in-a-Haystack, NIAH)测试依赖关键词匹配的做法,它最大的特点是 通过精心设计问题和关键信息,迫使模型进行深层语义理解和推理,才能从长文本中找到答案。
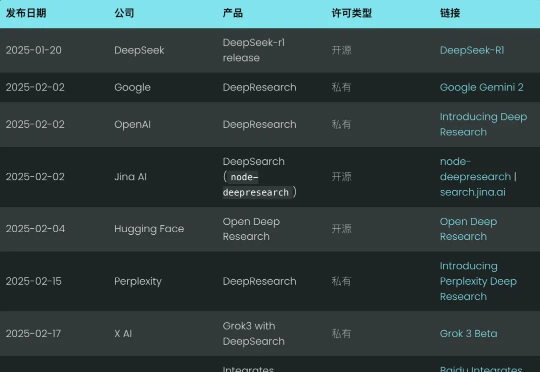
这才 2 月份,深度搜索(Deep Search)就已经隐隐成为 2025 年的新搜索标准了。像谷歌和 OpenAI 这样的巨头,纷纷亮出自己的“Deep Research”产品,努力抢占这波技术浪潮的先机。(我们也很自豪,在同一天也发布了开源的node-deepresearch)。
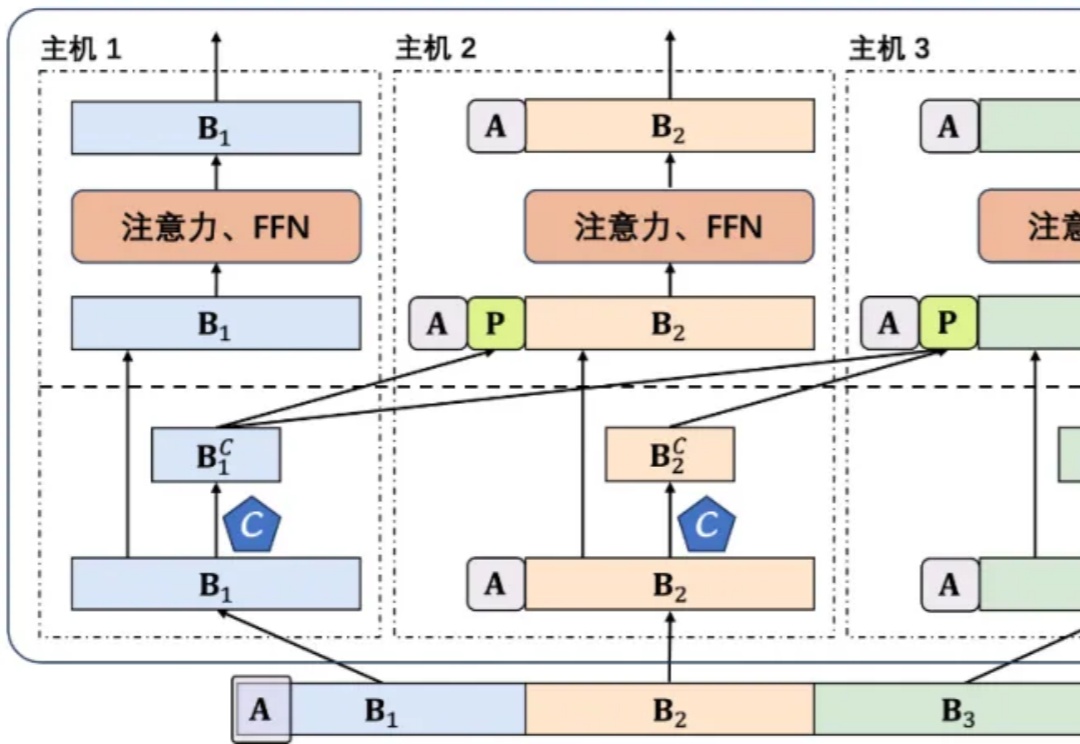
在 ChatGPT 爆火两年多的时间里,大语言模型的上下文窗口长度基准线被拉升,以此为基础所构建的长 CoT 推理、多 Agent 协作等类型的高级应用也逐渐增多。

3月6日上午,宁波市妇女儿童医学中心的产房中,小名思思的孩子呱呱坠地,医护人员为她进行了血氧饱和度测试以及心脏听诊,数据同步至“CHANGE大模型”(中文名启元大模型),几十秒钟后,大模型给出了“阳性”的红字提示,“是先天性心脏病,但是情况不严重,做好随访,3岁之前做一个微创手术就能根治。”医生安慰着思思的父母。
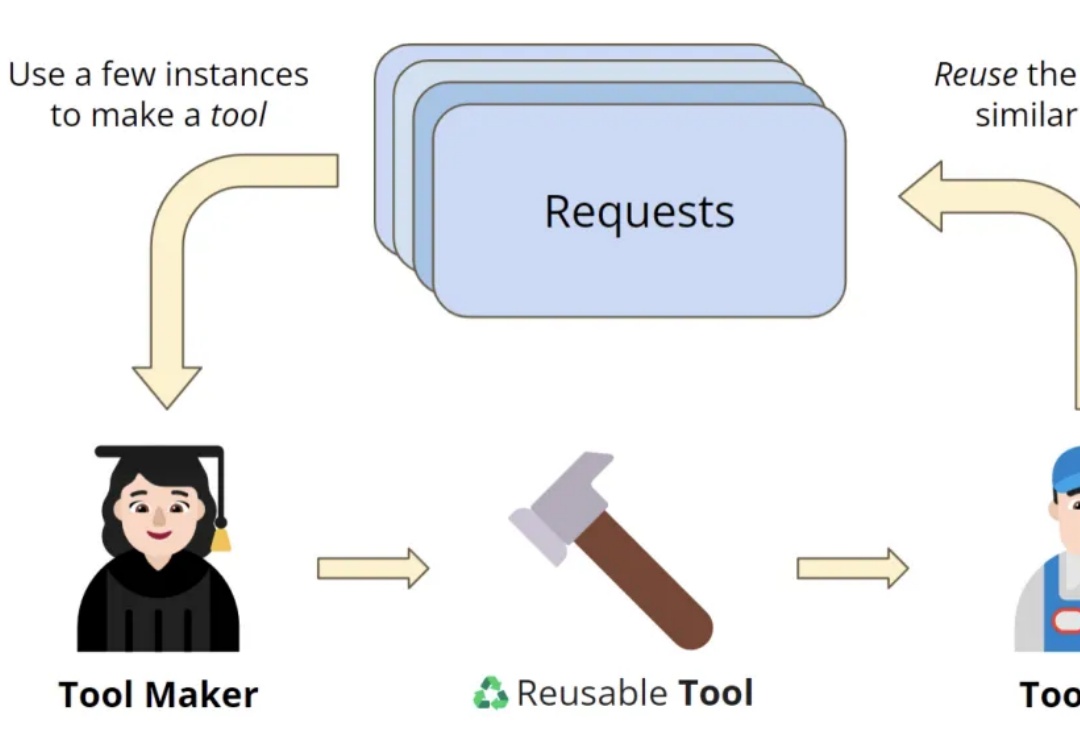
OctoTools通过标准化工具卡和规划器,帮助LLMs高效完成复杂任务,无需额外训练。在16个任务中表现优异,比其他方法平均准确率高出9.3%,尤其在多步推理和工具使用方面优势明显。
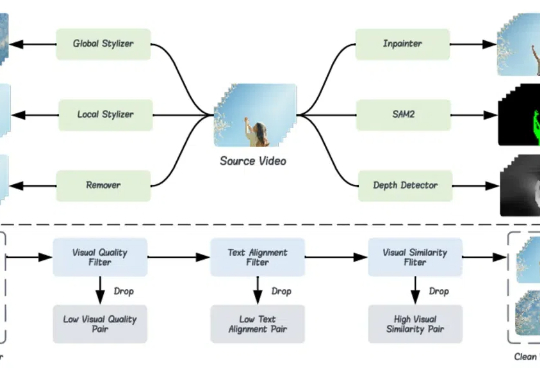
为了解决视频编辑模型缺乏训练数据的问题,本文作者(来自香港中文大学、香港理工大学、清华大学等高校和云天励飞)提出了一个名为 Señorita-2M 的数据集。该数据集包含 200 万高质量的视频编辑对,囊括了 18 种视频编辑任务。

Manus 爆火出圈,引发 Agent 热潮!从自行理解任务、拆解步骤到选择工具并执行,这需要 Agent 具备强大的复杂工作流编排和任务处理能力,而工作流也是智能体的核心技术之一。

大模型训练几乎消耗尽所有IT数据之后,挖掘OT数据正成为AI落地的重要方向。
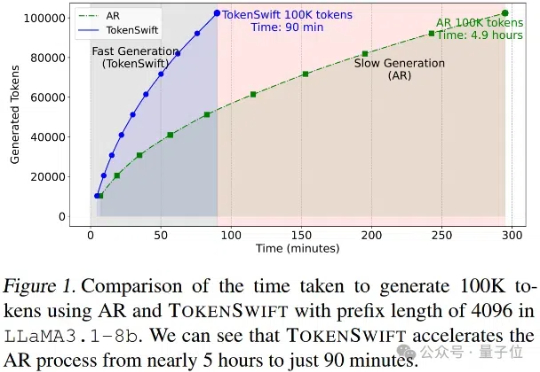
大语言模型长序列文本生成效率新突破——生成10万Token的文本,传统自回归模型需要近5个小时,现在仅需90分钟!

只要微调模型生成的前8-32个词,就能让大模型推理能力达到和传统监督训练一样的水平?