英伟达253B开源新王登场,Llama 4三天变陪衬!直逼DeepSeek-R1成推理天花板
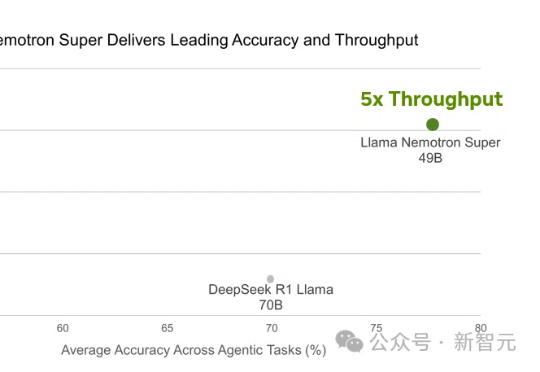
英伟达253B开源新王登场,Llama 4三天变陪衬!直逼DeepSeek-R1成推理天花板Llama 4刚出世就被碾压!英伟达强势开源Llama Nemotron-253B推理模型,在数学编码、科学问答中准确率登顶,甚至以一半参数媲美DeepSeek R1,吞吐量暴涨4倍。关键秘诀,就在于团队采用的测试时Scaling。
来自主题: AI资讯
7833 点击 2025-04-09 18:02