全国产算力!一手实测科大讯飞推理模型星火X1,与R1不相上下?
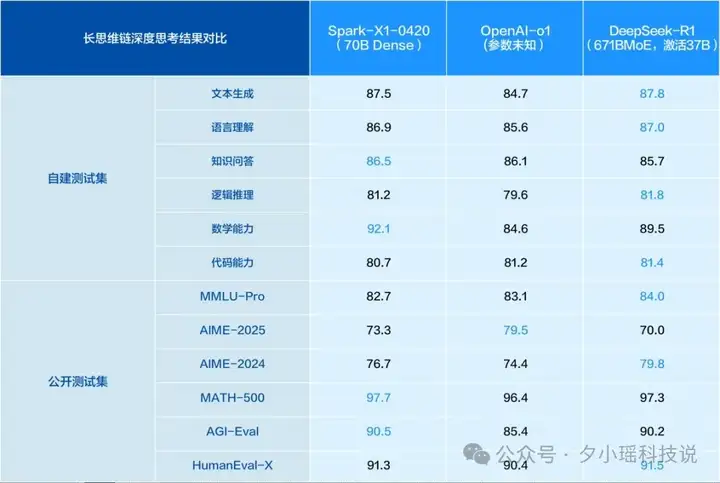
全国产算力!一手实测科大讯飞推理模型星火X1,与R1不相上下?就在昨天,深耕语音、认知智能几十年的科大讯飞,发布了全新升级的讯飞星火推理模型 X1。不仅效果上比肩 DeepSeek-R1,而且我注意到一条官方发布的信息——基于全国产算力训练,在模型参数量比业界同类模型小一个数量级的情况下,整体效果能对标 OpenAI o1 和 DeepSeek R1。
来自主题: AI资讯
10975 点击 2025-04-22 08:29