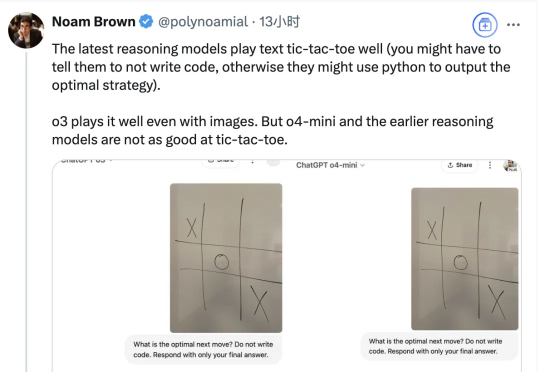
小小井字棋难倒大模型??大神卡帕西被OpenAI在线踢馆了
小小井字棋难倒大模型??大神卡帕西被OpenAI在线踢馆了宝可梦之后,让大模型玩井字棋又成了一个新的热门挑战。
来自主题: AI资讯
9845 点击 2025-04-28 18:05
 搜索
搜索
宝可梦之后,让大模型玩井字棋又成了一个新的热门挑战。
多模态大模型几何解题哪家强?

大模型技术加速向产业渗透,如何直击业务痛点、带来真实增效?
通过蒙特卡洛树搜索筛选高难度样本,ThinkLite-VL仅用少量数据就能显著提升视觉语言模型的推理能力,无需知识蒸馏,为高效训练提供了新思路。
一项来自清华大学和上海交通大学的研究颠覆了对可验证奖励强化学习(RLVR)的认知。RLVR被认为是打造自我进化大模型的关键,但实验表明,它可能只是提高了采样效率,而非真正赋予模型全新推理能力。

最近在看 Agent 方向的论文和产品,已经被各种进展看花了眼。但我发现,真正能超越 demo,能在 B 端场景扎实落地的却寥寥无几。
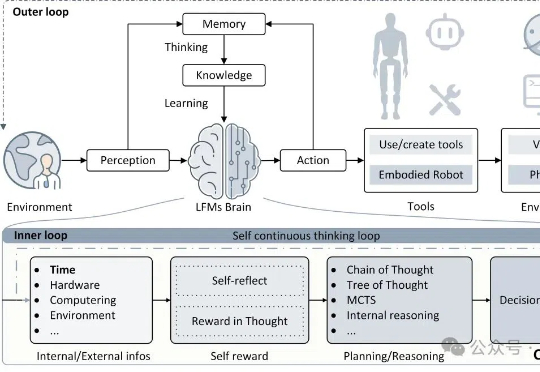
自主通才科学家(AGS)正成为现实!
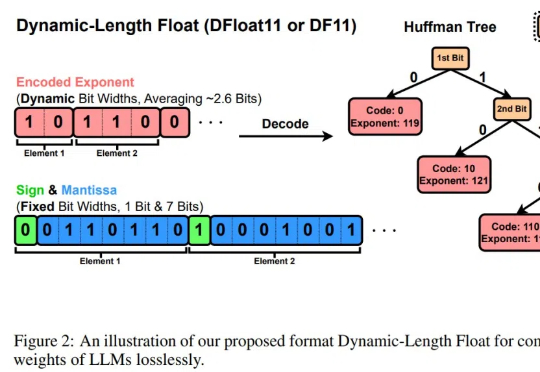
大型语言模型(LLMs)在广泛的自然语言处理(NLP)任务中展现出了卓越的能力。
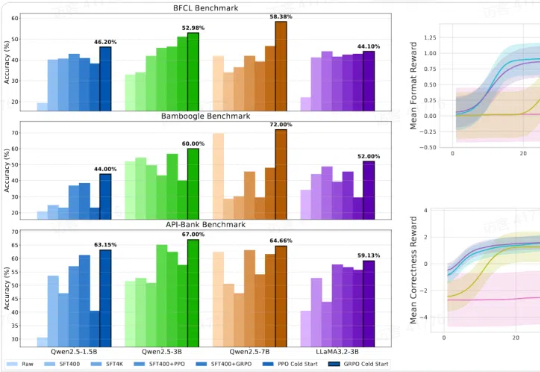
「工欲善其事,必先利其器。」 如今,人工智能正以前所未有的速度革新人类认知的边界,而工具的高效应用已成为衡量人工智能真正智慧的关键标准。
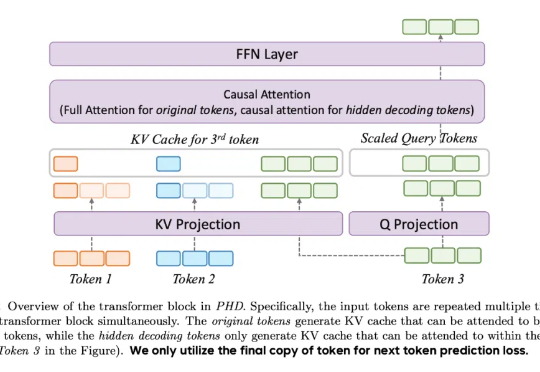
最近,DeepSeek-R1 和 OpenAI o1/03 等推理大模型在后训练阶段探索了长度扩展(length scaling),通过强化学习(比如 PPO、GPRO)训练模型生成很长的推理链(CoT),并在奥数等高难度推理任务上取得了显著的效果提升。