
互联网大厂,不再需要AI Lab
互联网大厂,不再需要AI Lab4月29日,腾讯TEG进行架构调整,新成立大语言和多模态模型部,并对数据平台和机器学习平台职责进行调整。
来自主题: AI资讯
9244 点击 2025-05-09 14:28
 搜索
搜索
4月29日,腾讯TEG进行架构调整,新成立大语言和多模态模型部,并对数据平台和机器学习平台职责进行调整。
AI视频的DeepSeek时刻什么时候来?没想到吧,这就来了。
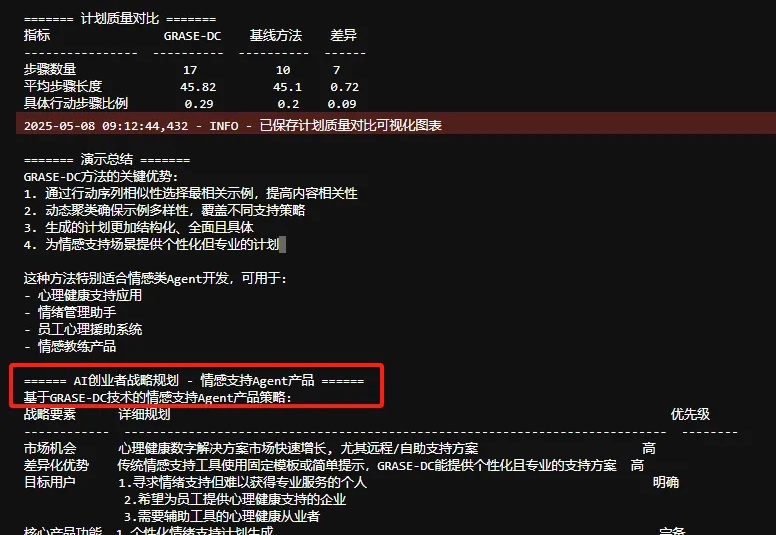
当您的Agent需要规划多步骤操作以达成目标时,比如游戏策略制定或旅行安排优化等等,传统规划方法往往需要复杂的搜索算法和多轮提示,计算成本高昂且效率不佳。来自Google DeepMind和CMU的研究者提出了一个简单却非常烧脑的问题:我们是否一直在用错误的方式选择示例来引导LLM学习规划?
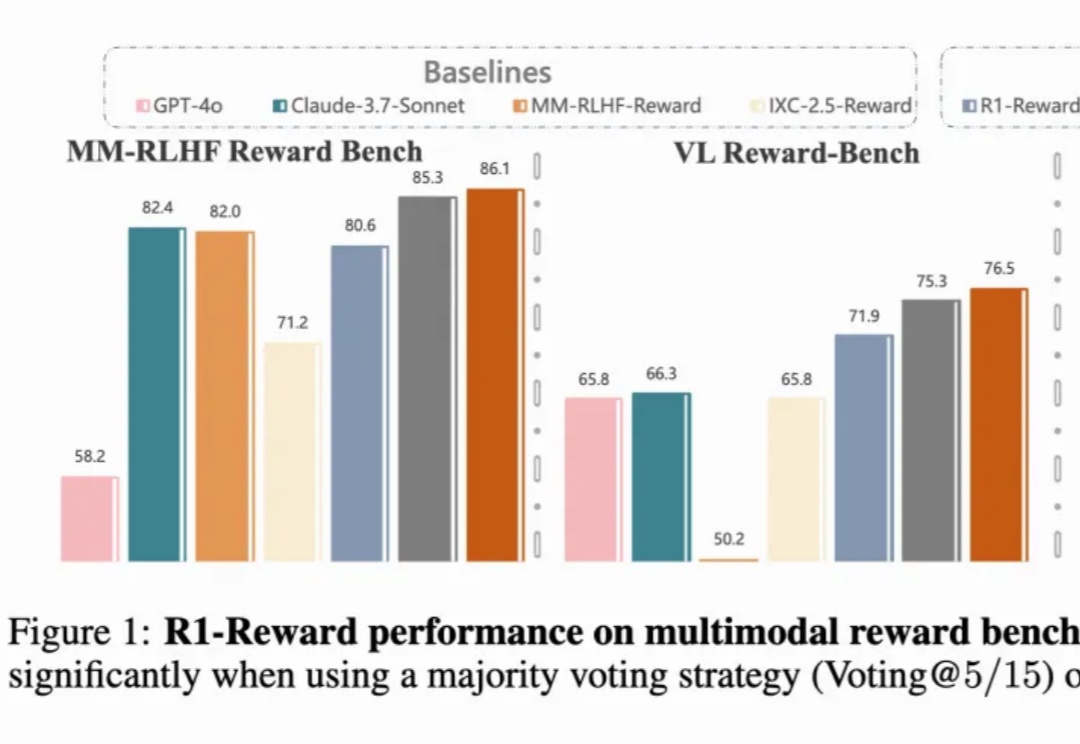
多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用:
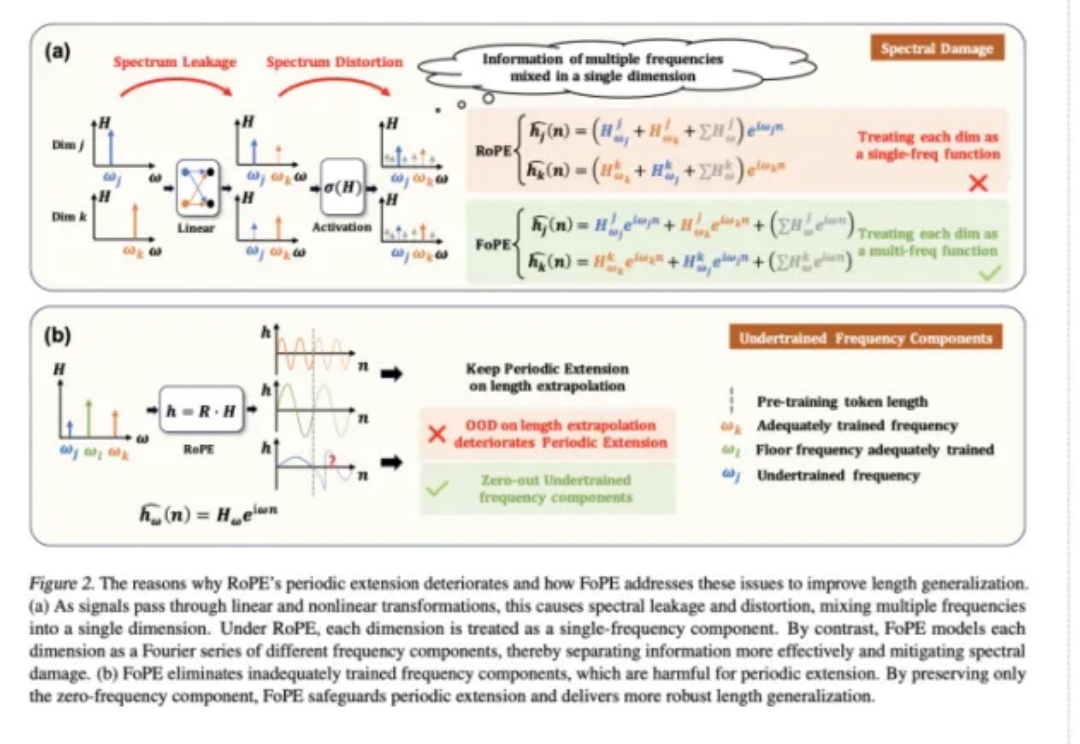
长文本能力对语言模型(LM,Language Model)尤为重要,试想,如果 LM 可以处理无限长度的输入文本,我们可以预先把所有参考资料都喂给 LM,或许 LM 在应对人类的提问时就会变得无所不能。
Anthropic 推出了一项新 API,使其 Claude AI 模型能够进行全网搜索。该公司在 5 月 7 日发布的新闻稿中表示,开发者利用此 API 可构建基于 Claude 的应用,提供最新信息。
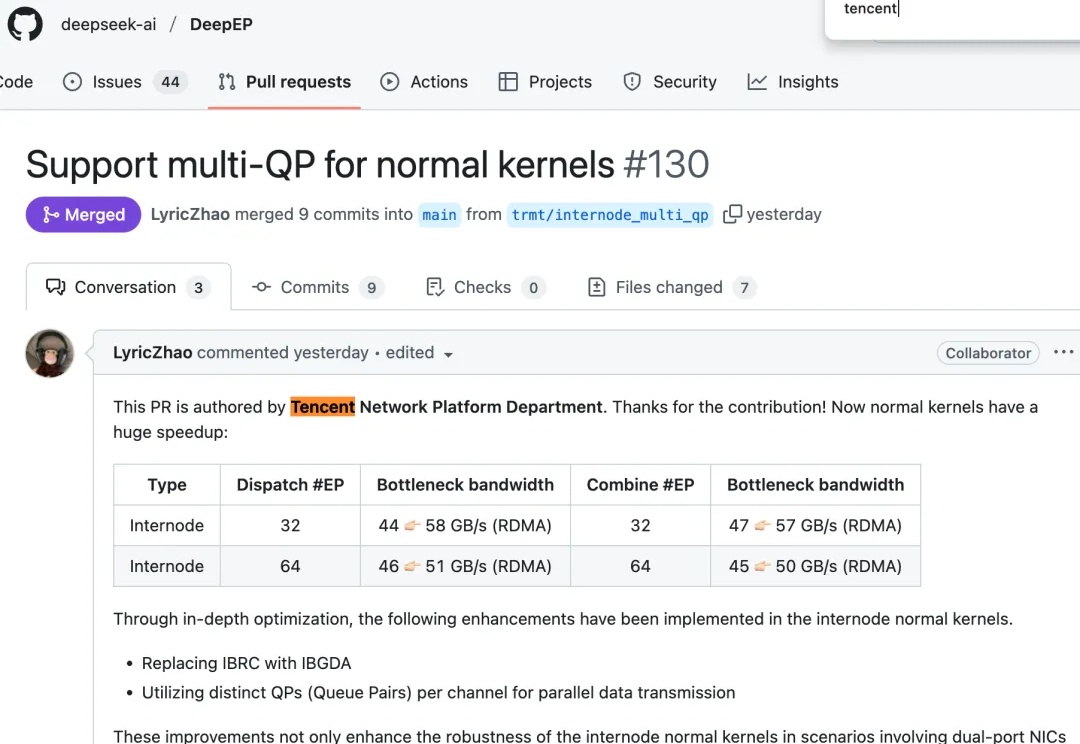
最近,DeepSeek工程师在GitHub上高亮了来自腾讯的代码贡献,并用“huge speedup”介绍了这次性能提升。
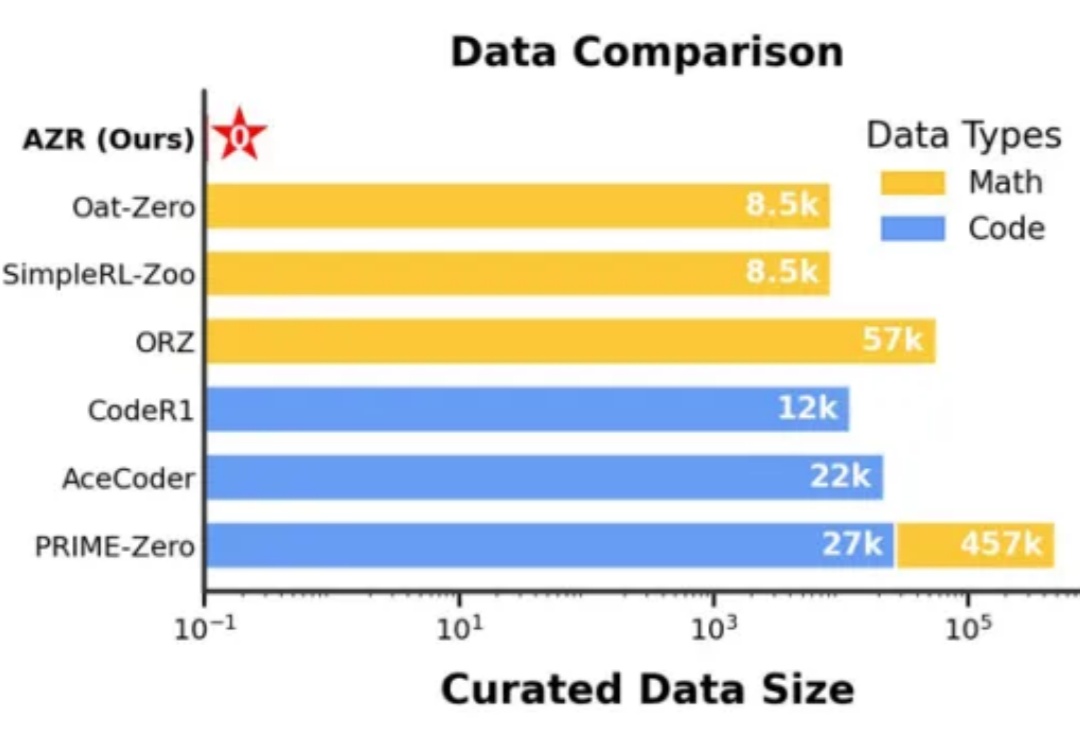
在人工智能领域,推理能力的进化已成为通向通用智能的核心挑战。近期,Reinforcement Learning with Verifiable Rewards(RLVR)范式下涌现出一批「Zero」类推理模型,摆脱了对人类显式推理示范的依赖,通过强化学习过程自我学习推理轨迹,显著减少了监督训练所需的人力成本。

现在,跑准万亿参数的大模型,可以彻底跟英伟达Say Goodbye了。
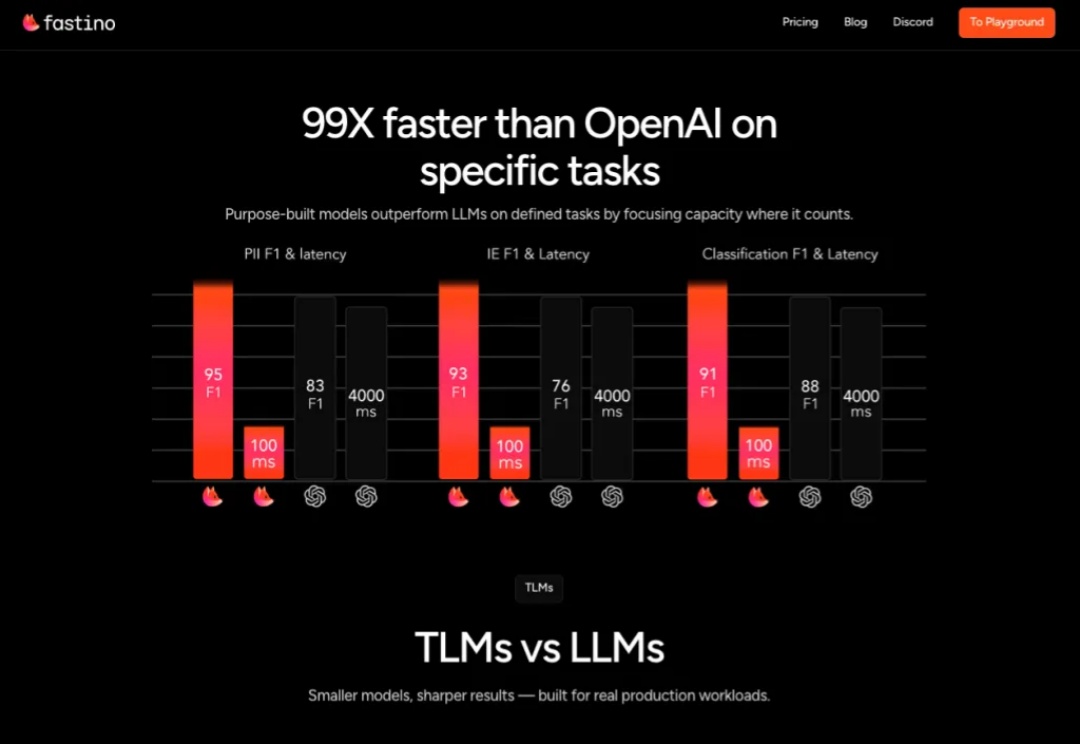
科技巨头常吹嘘需要庞大昂贵GPU 集群的万亿参数 AI 模型,但 Fastino 正采取截然不同的策略